这里的代码示例我用python实现一下:
分组就是把一个正则表达式的各个子表达式部分用括号括起来,然后可以调用groups()方法,获取所有的分组,python返回的是元组(X,XX,XXX)。
调用group(0)返回的是原字符串,group(1)返回的是分组匹配的第一个,group(2)返回的是分组匹配的是第二个,一次类推。
示例:我们简单匹配一下邮件地址
import re
re_email=re.compile(r'^(w?|[<]{0,1}w*[>]{0,1})[@]{1}(w*.w*)$')
re_email.match('<ShyBee>@163.com').groups()
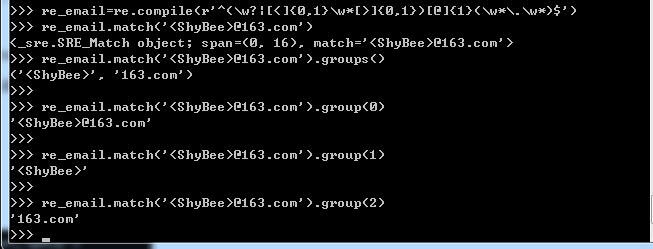
这就是正则表达式分组的概念,很强大,很好用。继续说一下正则表达式的贪婪匹配原则:正则匹配默认是贪婪匹配,也就是匹配尽可能多的字符

当使用d+时,分组会匹配尽可能多的数字,这样就导致分组(0*)没有匹配到任何字符,可以使用?取消贪婪模式,结果如上图所示。