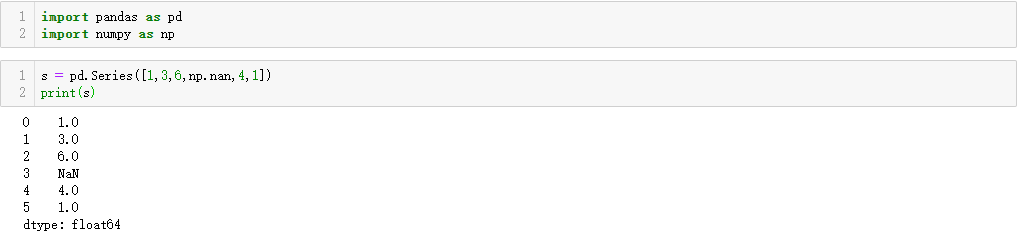
import pandas as pd import numpy as np s = pd.Series([1,3,6,np.nan,4,1]) print(s)
dates = pd.date_range('20191009',periods=6) print(dates)

df = pd.DataFrame(np.random.randn(6,4),index=dates,columns=['a','b','c','d'])#行是index 列columns print(df)

#直接用默认形式 df1 = pd.DataFrame(np.arange(12).reshape((3,4))) print(df1)

#利用字典形式 df2 = pd.DataFrame({'A':1., 'B':pd.Timestamp('20191009'), 'C':pd.Series(1,index=list(range(4)),dtype='float32'), 'D':np.array([3]*4,dtype='int32'), 'E':pd.Categorical(["test","train","test","train"]), 'F':'foo'}) print(df2) print(df2.index)#列的名字 print(df2.columns)#行的名字 print(df2.values)#值 print(df2.describe()) print(df2.T)#转置 df2.sort_index(axis=1,ascending=False)#按列排序 倒的序列排序 df2.sort_index(axis=0,ascending=False)#按行排序 倒的序列排序 df2.sort_values(by='E')#按某一列数值排序

#选择数据 dates = pd.date_range('20191009',periods=6) df = pd.DataFrame(np.arange(24).reshape((6,4)),index=dates,columns=['A','B','C','D']) # print(df['A'],df.A) # print(df[0:3],df['20191009':'20191011']) #select by label:loc # print(df.loc['20191010']) # print(df.loc[:,['A','B']]) print(df.loc['20191009',['A','B']]) #select by position:iloc print(df.iloc[1:2,1:3])#筛选 print(df.iloc[[1,3,5],1:3])#逐个筛选 #mixed selection:ix print(df.ix[:3,['A','C']])#第0行到第3行,A C 两列 print(df[df.A>8])#在A那行大于8的数字显示出来
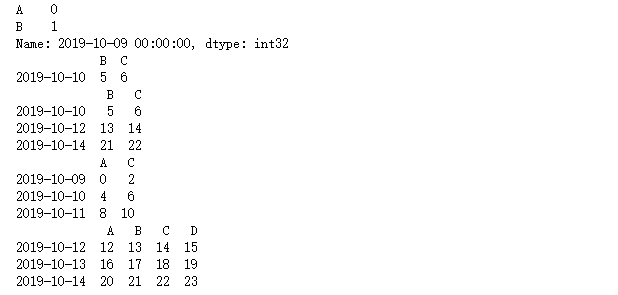
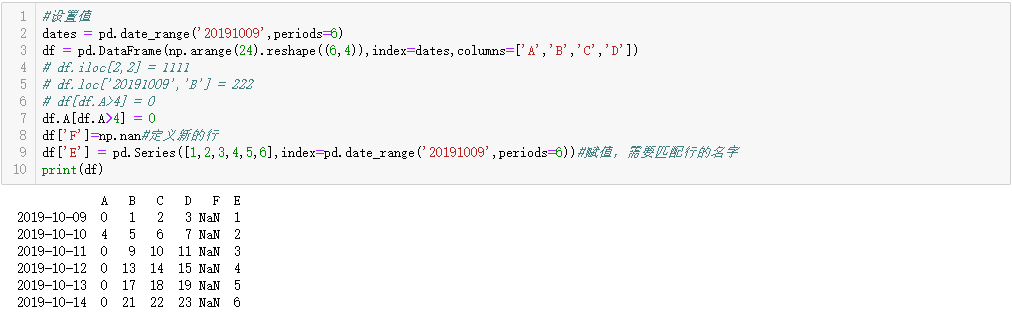
#设置值 dates = pd.date_range('20191009',periods=6) df = pd.DataFrame(np.arange(24).reshape((6,4)),index=dates,columns=['A','B','C','D']) # df.iloc[2,2] = 1111 # df.loc['20191009','B'] = 222 # df[df.A>4] = 0 df.A[df.A>4] = 0 df['F']=np.nan#定义新的行 df['E'] = pd.Series([1,2,3,4,5,6],index=pd.date_range('20191009',periods=6))#赋值,需要匹配行的名字 print(df)
#处理丢失掉的数据 dates = pd.date_range('20191009',periods=6) df = pd.DataFrame(np.arange(24).reshape((6,4)),index=dates,columns=['A','B','C','D']) df.iloc[0,1] = np.nan df.iloc[1,2] = np.nan print(df) # print(df.fillna(value=0)) # print(df.isnull()) print(np.any(df.isnull()==True))#表格比较大,用这个看是否有丢失的数据
