实验要求
基本功能
- 统计文件的字符数
- 统计文件的单词总数
- 统计文件的总行数
- 统计文件中各单词的出现次数
- 对给定文件夹及其递归子文件夹下的所有文件进行统计
- 统计两个单词(词组)在一起的频率,输出频率最高的前10个。
- 在Linux系统下,进行性能分析,过程写到blog中(附加题)
注意:
a) 空格,水平制表符,换行符,均算字符
b) 单词的定义:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
英文字母:A-Z,a-z
字母数字符号:A-Z,a-z,0-9
分割符:空格,非字母数字符号
例如:”file123”是一个单词,”123file”不是一个单词。file,File和FILE是同一个单词。
如果两个单词只有最后的数字结尾不同,则认为是同一个单词,例如,windows,windows95和windows7是同一个单词,iPhone4和IPhone5是同一个单词,但是,windows和windows32a是不同的单词,因为他们不是仅有数字结尾不同
输出按字典顺序,例如,windows95,windows98和windows2000同时出现时,输出windows2000
词组的定义:windows95 good, windows2000 good123,可以算是同一种词组。按照词典顺序输出。
c) 输入文件名以命令行参数传入
d) 输出文件result.txt
characters: number
words: number
lines: number
e) 根据命令行参数判断是否为目录
PSP表格
| PSP2.1 | 任务内容 | 计划完成需要的时间(min) | 实际完成需要的时间(min) |
|---|---|---|---|
| Planning | 计划 | 30 | 20 |
| Estimate | 估计时间并做出规划 | 20 | 25 |
| Analysis | 需求分析 (包括学习新技术) | 30 | 30 |
| Design Spec | 生成设计文档 | 20 | 10 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 5 |
| Design | 具体设计 | 30 | 50 |
| Coding | 具体编码 | 360 | 400 |
| Code Review | 代码复审 | 10 | 10 |
| est | 测试(自我测试,修改代码,提交修改) | 300 | 600 |
| Test Report | 测试报告 | 60 | 60 |
| Size Measurement | 计算工作量 | 10 | 15 |
| Postmortem & Process Improvement Plan | 事后总结 ,并提出过程改进计划 | 10 | 15 |
| 总计 | 890 | 1240 |
前期分析与设计
刚看到这个题目时,感觉还挺简单的。因为在之前的C语言课程上我们做过类似的题目,但是当我详细阅读要求时,却发现事情并没有那么简单。首先助教给出的测试集着实把我吓了一跳,一个170多兆的文件夹,还需要我完成这么多的要求,显然需要占用极其庞大的内存空间。
1.统计字符数:依次读取文件中的字符,每读取一个字符,计数器加一。
2.统计行数:每读到一个换行符计数器就加一。
3.统计单词数:如果读到四个英文字符计数器就加一,然后一直读取字符,直到读到分隔符为止。
4.统计词频和词组频数:前期使用结构体数组,在处理大文件时,发现会有栈溢出的情况,所以后来改用哈希表,哈希表中记录的是不同的单词或词组存储的位置。发现解决了这个问题。
5.找出频率最高的前十名单词和词组,采用冒泡算法,只需要排10次就可以找到相应的结果。
6.使用递归调用的办法来遍历文件夹。即获得一个文件夹的路径,就遍历该文件夹下所有的子文件夹,这样的话就可以扫描所有的文件。
测试结果与问题(含源代码)
基于我的设计思路,我写出来了以下的代码,但是在我测试的时候我发现统计出来的频率为前十的单词和词组结果明显不对,但是当我对单文件进操作时,答案是正确的,这就说明出现了bug。这就让我很不爽,但是因为临近ddl,我只能把代码交上去了,希望各位大佬能够帮我找一下bug,就算是作业已经交上去了,但我还是想搞清楚原因。
源代码如下:
// ConsoleApplication4.cpp: 定义控制台应用程序的入口点。
//
#include "stdafx.h"
#include "process.h"
#include "string"
#include "cstring"
#include "iostream"
#include "io.h"
#include "stdlib.h"
#define strcasecmp _stricmp
#define MAX 20000000
int characternum = 0, wordnum = 0, line = 0;
using namespace std;
FILE *fin, *fout;
char *words[MAX], *former[MAX], *latter[MAX]; //words字符指针数组记录单词存储空间的首地址,former字符指针数组记录词组的第一个单词存储空间的首地址,latter字符指针数组记录词组的第二个单词存储空间的首地址
int cont[MAX], area[MAX], prnum[MAX], loc[MAX], num = 0, num1 = 0; //cont记录单词的频数,area记录的是在哈希表中单词头指针存在words中的下标,词组分别对应prnum和loc
void listFiles(const char * dir);
void init()//将记录频数的数组初始化
{
for (int i = 0; i < MAX; i++)
{
cont[i] = 0;
prnum[i] = 0;
}
}
unsigned int hashindex(char *str)//哈希函数
{
int n, i;
int seed = 131;
unsigned int hash = 0;
char copy[1024];
n = strlen(str);
n--;
while (str[n] > 47 && str[n] < 58) {
n--;
}
for (i = 0; i < n + 1; i++)
copy[i] = str[i];
copy[n + 1] = '�';
n = 0;
while (copy[n] != '�')
{
if (copy[n] >= 65 && copy[n] <= 90 || copy[n] >= 48 && copy[n] <= 57)
hash = hash * seed + copy[n];
else
hash = hash * seed + copy[n] - 32;
n++;
}
return ((hash & 0x7FFFFFFF) % MAX);
}
bool compare(int n, char *str)//比较两个单词是否相同(不计大小写)
{
char c[1024], b[1024];
int k;
strcpy_s(c, strlen(str) + 1, str);
strcpy_s(b, strlen(words[n]) + 1, words[n]);
k = strlen(c);
k--;
while (c[k] > 47 && c[k] < 58) {
k--;
}
c[k + 1] = '�';
k = strlen(b);
k--;
while (b[k] > 47 && b[k] < 58) {
k--;
}
b[k + 1] = '�';
if (strcasecmp(b, c) == 0)
return true;
return false;
}
void hashe(char *str)//存放单词并记录频数(包括冲突的解决机制)
{
int i;
unsigned int index;
bool flag;
index = hashindex(str);
if (cont[index] == 0)
{
cont[index]++;
area[index] = num;
num++;
}
else
{
flag = compare(area[index], str);
if (flag == true)
{
if (strcmp(words[area[index]], str) > 0)
{
delete(words[area[index]]);
words[area[index]] = str;
}
else
delete(str);
cont[index]++;
return;
}
for (i = 1;; i++)
{
if (cont[(index + i) % MAX] == 0)
{
cont[(index + i) % MAX]++;
area[(index + i) % MAX] = num;
num++;
break;
}
flag = compare(area[(index + i) % MAX], str);
if (flag == true)
{
if (strcmp(words[area[(index + i) % MAX]], str) > 0)
{
delete(words[area[(index + i) % MAX]]);
words[area[(index + i) % MAX]] = str;
}
else
delete(str);
cont[(index + i) % MAX]++;
break;
}
}
}
}
void characterandlinecollect(void)//统计字符总数和行数
{
char c;
while ((c = fgetc(fin)) != EOF)
{
if (c >= 32 && c <= 126)
characternum++;
if (c == '
')
{
line++;
}
}
if (characternum != 0)
line++;
}
bool compare1(int n, char *str)//比较两个词组的首单词是否相同(不计大小写)
{
char c[1024], b[1024];
int k;
strcpy_s(c, strlen(str) + 1, str);
strcpy_s(b, strlen(former[n]) + 1, former[n]);
k = strlen(c);
k--;
while (c[k] > 47 && c[k] < 58)
{
k--;
}
c[k + 1] = '�';
k = strlen(b);
k--;
while (b[k] > 47 && b[k] < 58) {
k--;
}
b[k + 1] = '�';
if (strcasecmp(b, c) == 0)
return true;
return false;
}
bool compare2(int n, char *str)//比较两个词组的第二个单词是否相同(不计大小写)
{
char c[1024], b[1024];
int k;
strcpy_s(c, strlen(str) + 1, str);
strcpy_s(b, strlen(latter[n]) + 1, latter[n]);
k = strlen(c);
k--;
while (c[k] > 47 && c[k] < 58) {
k--;
}
c[k + 1] = '�';
k = strlen(b);
k--;
while (b[k] > 47 && b[k] < 58) {
k--;
}
b[k + 1] = '�';
if (strcasecmp(b, c) == 0)
return true;
return false;
}
int put(char *str1, char *str2, int n)
{
if (n == 0)
return 0;
int hashnum;
int p, a, b, length;
hashnum = (hashindex(str1) + hashindex(str2)) % MAX;
while (prnum[hashnum]>0) {
p = loc[hashnum];
a = compare1(p, str1);
b = compare2(p, str2);
if (a == 1 && b == 1) {
prnum[hashnum]++;
return 1;
}
else
hashnum = (hashnum + 1) % MAX;
}
loc[hashnum] = n;
prnum[hashnum] = 1;
return 0;
}
int everywordcollect()//统计单词频数和词组频数
{
int wordnum1 = 0, count = 0, k, j, t, signP = 0;
char c, w[1024];
rewind(fin);
init();
former[0] = (char *)malloc(sizeof(char) * 10);
former[0][0] = '�';
while ((c = fgetc(fin)) != EOF)
{
if (c >= 65 && c <= 90 || c >= 97 && c <= 122)
{
count++;
w[count - 1] = c;
for (int i = 0; i<3; i++)
{
c = fgetc(fin);
if (c >= 65 && c <= 90 || c >= 97 && c <= 122)
{
count++;
w[count - 1] = c;
}
else
break;
}
if (count == 4)
{
wordnum1++;
c = fgetc(fin);
for (k = count; c >= 65 && c <= 90 || c >= 97 && c <= 122 || c >= 48 && c <= 57; k++)
{
w[k] = c;
c = fgetc(fin);
}
w[k] = '�';
words[num] = (char *)malloc(sizeof(char) * (strlen(w) + 1));
former[num1 + 1] = (char *)malloc(sizeof(char) * (strlen(w) + 1));
latter[num1] = (char *)malloc(sizeof(char) * (strlen(w) + 1));
strcpy_s(words[num], strlen(w) + 1, w);
strcpy_s(former[num1 + 1], strlen(w) + 1, w);
strcpy_s(latter[num1], strlen(w) + 1, w);
hashe(words[num]);
signP = put(former[num1], latter[num1], num1);
if (signP == 1) {
free(former[num1]);
free(latter[num1]);
former[num1] = (char *)malloc((strlen(w) + 1) * sizeof(char));
strcpy_s(former[num1], (strlen(w) + 1), w);
free(former[num1 + 1]);
}
else num1++;
}
count = 0;
}
else;
}
return wordnum1;
}
int main(int argc, char *argv[])
{
int k,j,t;
char dir[200];
strcpy_s(dir, 200, argv[1]);
listFiles(dir);
errno_t err;
err = fopen_s(&fout, "result.out", "w");
if (err == 1)
{
printf("can't open file!
");
exit(0);
}
for (k = 0; k < 10; k++)
for (j = k + 1; j < MAX; j++)
if (cont[k] < cont[j])
{
t = cont[k];
cont[k] = cont[j];
cont[j] = t;
t = area[k];
area[k] = area[j];
area[j] = t;
}
for (k = 0; k < 10; k++)
for (j = k + 1; j < MAX; j++)
if (prnum[k] < prnum[j])
{
t = prnum[k];
prnum[k] = prnum[j];
prnum[j] = t;
t = loc[k];
loc[k] = loc[j];
loc[j] = t;
}
fprintf(fout, "characters:%d
", characternum);
fprintf(fout, "line:%d
", line);
fprintf(fout, "word:%d
", wordnum);
fprintf(fout, "
the top ten frequency of word:
");
for (k = 0; k < 10; k++)
{
fprintf(fout, "%s:%d
", words[area[k]], cont[k]);
}
fprintf(fout, "
the top ten frequency of phrase:
");
for (k = 0; k < 10; k++)
{
fprintf(fout, "%s %s:%d
", former[loc[k]], latter[loc[k]], prnum[k]);
}
fclose(fout); //close files
system("pause");
return 0;
}
void listFiles(const char * dir)//遍历文件的函数
{
char dirNew[200];
char copy[200];
char c[200];
strcpy_s(dirNew, 200, dir);
strcat_s(dirNew, 200, "\*.*");
int length;
int handle;
_finddata_t findData;
handle = _findfirst(dirNew, &findData);
if (handle == -1)
return;
do
{
if (findData.attrib & _A_SUBDIR)
{
if (strcmp(findData.name, ".") == 0 || strcmp(findData.name, "..") == 0)
continue;
strcpy_s(c, 200, dir);
strcat_s(c, 200, "\");
strcat_s(c, 200, findData.name);
listFiles(c);
}
else {
int i;
errno_t err;
strcpy_s(copy, 200, dirNew);
length = strlen(copy);
copy[length - 3] = '�';
strcat_s(copy, 200, findData.name);
err = fopen_s(&fin, copy, "r");
characterandlinecollect();
wordnum += everywordcollect();
fclose(fin);
}
} while (_findnext(handle, &findData) == 0);
_findclose(handle);
}
测试结果:

可以看出频率前十的单词与词组统计是有误的,希望各位能够帮我指出错误原因。
今天早上刚起床,我想到了结果出错的原因:init()函数的位置放错了,应该放在main()函数中,否则每遍历一个文件,就需要调用everywordcollect()函数,而原本init()函数放在everywordcollect()里面,也就是说每遍历一个文件,就将记录数据的数组初始化一遍,结果肯定不对。下面,我将修改过的everywordcollect()函数与main()函数贴出来:
int everywordcollect()
{
int wordnum1 = 0, count = 0, k, j, t, signP = 0;
char c, w[1024];
rewind(fin);
former[0] = (char *)malloc(sizeof(char) * 10);
former[0][0] = '�';
while ((c = fgetc(fin)) != EOF)
{
if (c >= 65 && c <= 90 || c >= 97 && c <= 122)
{
count++;
w[count - 1] = c;
for (int i = 0; i<3; i++)
{
c = fgetc(fin);
if (c >= 65 && c <= 90 || c >= 97 && c <= 122)
{
count++;
w[count - 1] = c;
}
else
break;
}
if (count == 4)
{
wordnum1++;
c = fgetc(fin);
for (k = count; c >= 65 && c <= 90 || c >= 97 && c <= 122 || c >= 48 && c <= 57; k++)
{
w[k] = c;
c = fgetc(fin);
}
w[k] = '�';
words[num] = (char *)malloc(sizeof(char) * (strlen(w) + 1));
former[num1 + 1] = (char *)malloc(sizeof(char) * (strlen(w) + 1));
latter[num1] = (char *)malloc(sizeof(char) * (strlen(w) + 1));
strcpy_s(words[num], strlen(w) + 1, w);
strcpy_s(former[num1 + 1], strlen(w) + 1, w);
strcpy_s(latter[num1], strlen(w) + 1, w);
hashe(words[num]);
signP = put(former[num1], latter[num1], num1);
if (signP == 1) {
free(former[num1]);
free(latter[num1]);
former[num1] = (char *)malloc((strlen(w) + 1) * sizeof(char));
strcpy_s(former[num1], (strlen(w) + 1), w);
free(former[num1 + 1]);
}
else num1++;
}
count = 0;
}
else;
}
return wordnum1;
}
int main(int argc, char *argv[])
{
int k,j,t;
char dir[200];
cin.getline(dir, 200);
//strcpy_s(dir, 200, argv[1]);
init();
listFiles(dir);
errno_t err;
err = fopen_s(&fout, "result.out", "w");
if (err == 1)
{
printf("can't open file!
");
exit(0);
}
for (k = 0; k < 10; k++)
for (j = k + 1; j < MAX; j++)
if (cont[k] < cont[j])
{
t = cont[k];
cont[k] = cont[j];
cont[j] = t;
t = area[k];
area[k] = area[j];
area[j] = t;
}
for (k = 0; k < 10; k++)
for (j = k + 1; j < MAX; j++)
if (prnum[k] < prnum[j])
{
t = prnum[k];
prnum[k] = prnum[j];
prnum[j] = t;
t = loc[k];
loc[k] = loc[j];
loc[j] = t;
}
fprintf(fout, "characters:%d
", characternum);
fprintf(fout, "line:%d
", line);
fprintf(fout, "word:%d
", wordnum);
fprintf(fout, "
the top ten frequency of word:
");
for (k = 0; k < 10; k++)
{
fprintf(fout, "%s:%d
", words[area[k]], cont[k]);
}
fprintf(fout, "
the top ten frequency of phrase:
");
for (k = 0; k < 10; k++)
{
fprintf(fout, "%s %s:%d
", former[loc[k]], latter[loc[k]], prnum[k]);
}
fclose(fout); //close files
system("pause");
return 0;
}
修改过bug之后的测试结果:
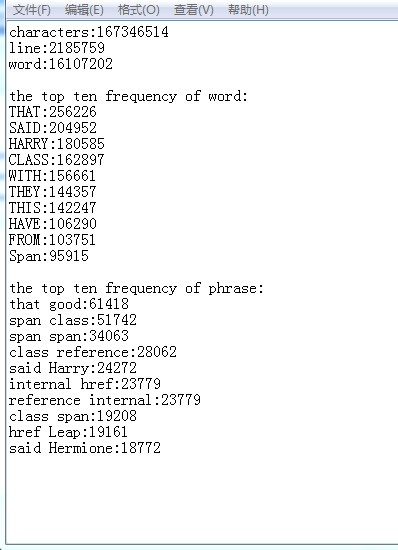
性能分析
一个有趣的事情是,当我在进行性能测试时,我发现了程序运行缓慢的原因,我交给助教的代码的排序算法的位置放错了,我放在了一个循环之中,这就导致我每读一个单词,就排序一次。上面的代码已经修复了这一点。
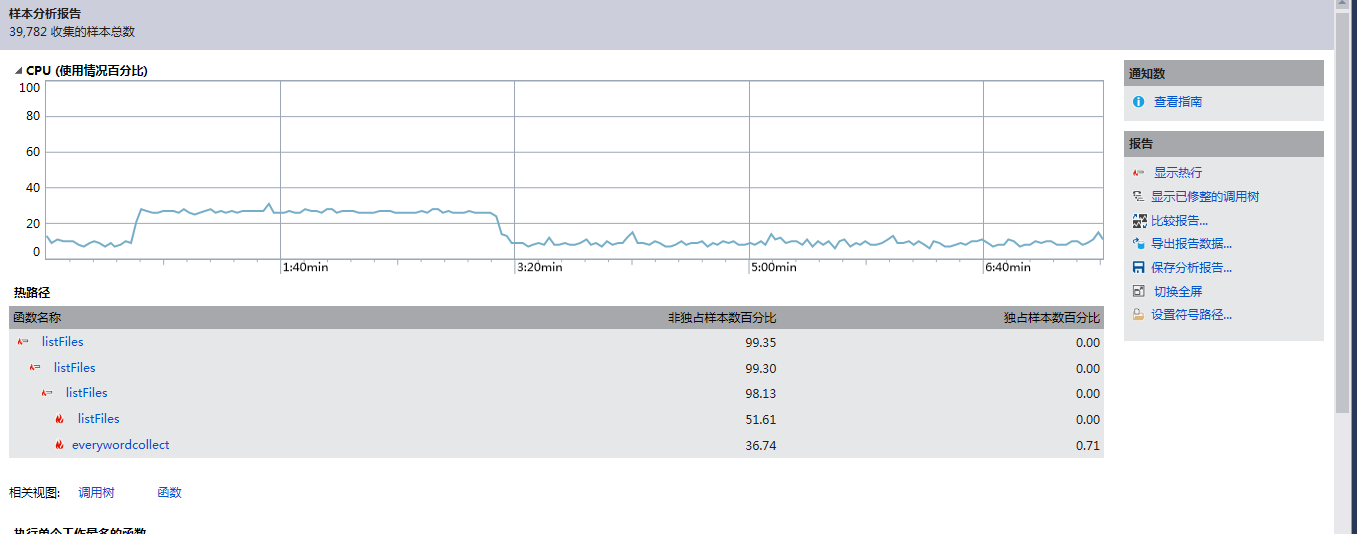
VS的性能分析工具给出的热行如下:
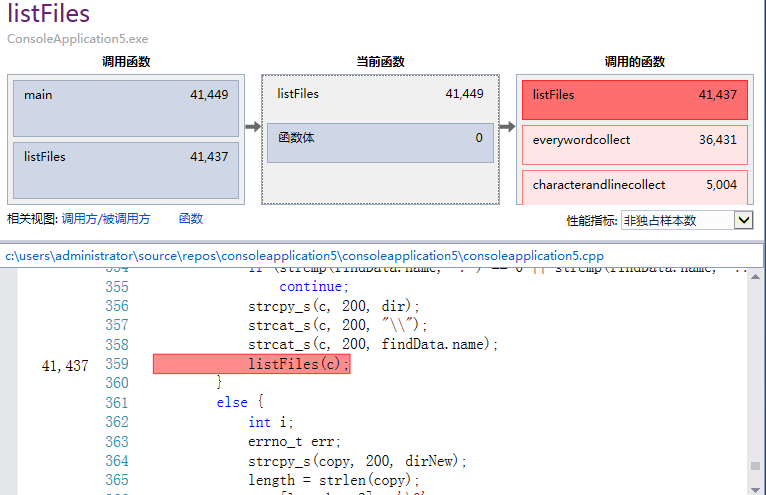
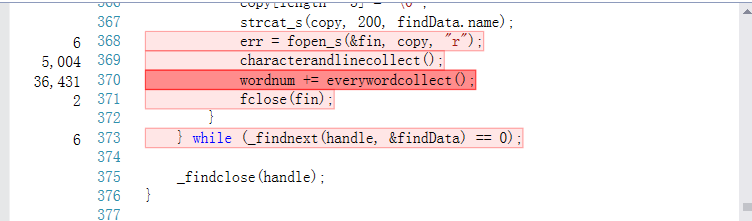
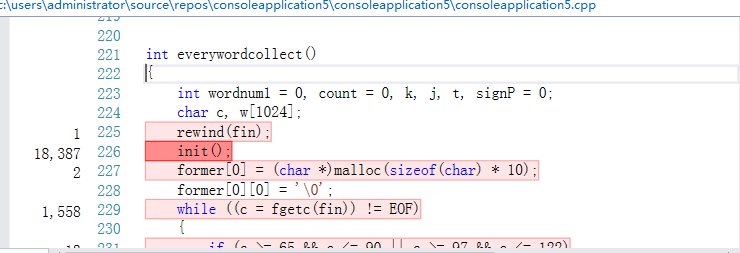
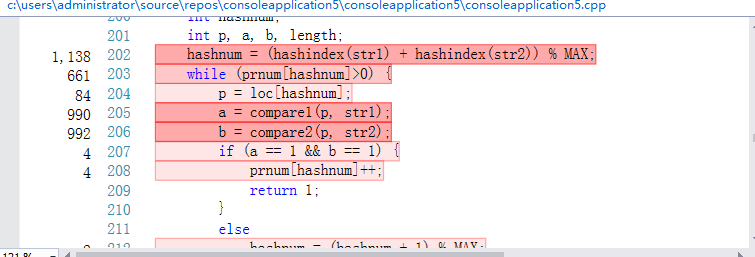
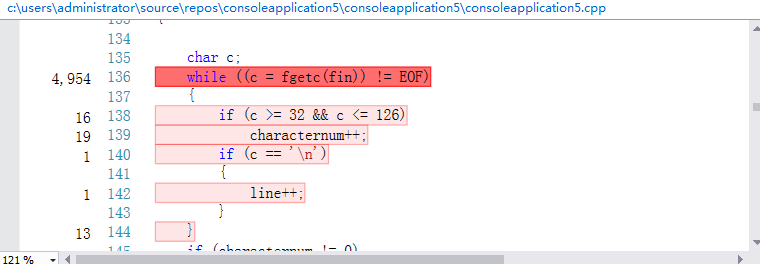
可以看出,热行是listFiles()函数、init()函数、求词组的哈希值、读取字符的循环,但是基于我的编程思路,这些操作都是必要的,因为我的程序是需要分配很多内存的,但我在程序上已经做出来改进,当一些不必要的内存没有存在的意义时,我就将其释放掉,如果可以改进单词和词组存储方式,就能在很大程度上消除热行带来的影响。
Linux系统上的调试
在身边同学的帮助下,我成功地在Linux系统上修改了代码,并且能够在Linux系统上编译运行了,主要是修改了一些头文件,并且更新了一部分的函数(比如strcpy_s、fopen_s),修改后Linux系统上的代码是:
#include "cstring"
#include "iostream"
#include<string>
#include<experimental/filesystem>
#define MAX 20000000
int characternum = 0, wordnum = 0, line = 0;
FILE *fin, *fout;
char *words[MAX], *former[MAX], *latter[MAX];
int cont[MAX], area[MAX], prnum[MAX], loc[MAX], num = 0, num1 = 0;
void listFiles(const char * dir);
void init()
{
for (int i = 0; i < MAX; i++)
{
cont[i] = 0;
prnum[i] = 0;
}
}
unsigned int hashindex(char *str)
{
int n, i;
int seed = 131;
unsigned int hash = 0;
char copy[1024];
n = strlen(str);
n--;
while (str[n] > 47 && str[n] < 58) {
n--;
}
for (i = 0; i < n + 1; i++)
copy[i] = str[i];
copy[n + 1] = '�';
n = 0;
while (copy[n] != '�')
{
if (copy[n] >= 65 && copy[n] <= 90 || copy[n] >= 48 && copy[n] <= 57)
hash = hash * seed + copy[n];
else
hash = hash * seed + copy[n] - 32;
n++;
}
return ((hash & 0x7FFFFFFF) % MAX);
}
bool compare(int n, char *str)
{
char c[1024], b[1024];
int k;
strcpy(c, str);
strcpy(b, words[n]);
k = strlen(c);
k--;
while (c[k] > 47 && c[k] < 58) {
k--;
}
c[k + 1] = '�';
k = strlen(b);
k--;
while (b[k] > 47 && b[k] < 58) {
k--;
}
b[k + 1] = '�';
if (strcasecmp(b, c) == 0)
return true;
return false;
}
void hashe(char *str)
{
int i;
unsigned int index;
bool flag;
index = hashindex(str);
if (cont[index] == 0)
{
cont[index]++;
area[index] = num;
num++;
}
else
{
flag = compare(area[index], str);
if (flag == true)
{
if (strcmp(words[area[index]], str) > 0)
{
delete(words[area[index]]);
words[area[index]] = str;
}
else
delete(str);
cont[index]++;
return;
}
for (i = 1;; i++)
{
if (cont[(index + i) % MAX] == 0)
{
cont[(index + i) % MAX]++;
area[(index + i) % MAX] = num;
num++;
break;
}
flag = compare(area[(index + i) % MAX], str);
if (flag == true)
{
if (strcmp(words[area[(index + i) % MAX]], str) > 0)
{
delete(words[area[(index + i) % MAX]]);
words[area[(index + i) % MAX]] = str;
}
else
delete(str);
cont[(index + i) % MAX]++;
break;
}
}
}
}
void characterandlinecollect(void)
{
char c;
while ((c = fgetc(fin)) != EOF)
{
if (c >= 32 && c <= 126)
characternum++;
if (c == '
')
{
line++;
}
}
if (characternum != 0)
line++;
}
bool compare1(int n, char *str)
{
char c[1024], b[1024];
int k;
strcpy(c, str);
strcpy(b, former[n]);
k = strlen(c);
k--;
while (c[k] > 47 && c[k] < 58)
{
k--;
}
c[k + 1] = '�';
k = strlen(b);
k--;
while (b[k] > 47 && b[k] < 58) {
k--;
}
b[k + 1] = '�';
if (strcasecmp(b, c) == 0)
return true;
return false;
}
bool compare2(int n, char *str)
{
char c[1024], b[1024];
int k;
strcpy(c, str);
strcpy(b, latter[n]);
k = strlen(c);
k--;
while (c[k] > 47 && c[k] < 58) {
k--;
}
c[k + 1] = '�';
k = strlen(b);
k--;
while (b[k] > 47 && b[k] < 58) {
k--;
}
b[k + 1] = '�';
if (strcasecmp(b, c) == 0)
return true;
return false;
}
int put(char *str1, char *str2, int n)
{
if (n == 0)
return 0;
int hashnum;
int p, a, b, length;
hashnum = (hashindex(str1) + hashindex(str2)) % MAX;
while (prnum[hashnum]>0) {
p = loc[hashnum];
a = compare1(p, str1);
b = compare2(p, str2);
if (a == 1 && b == 1) {
prnum[hashnum]++;
return 1;
}
else
hashnum = (hashnum + 1) % MAX;
}
loc[hashnum] = n;
prnum[hashnum] = 1;
return 0;
}
int everywordcollect()
{
int wordnum1 = 0, count = 0, k, j, t, signP = 0;
char c, w[1024];
rewind(fin);
former[0] = (char *)malloc(sizeof(char) * 10);
former[0][0] = '�';
while ((c = fgetc(fin)) != EOF)
{
if (c >= 65 && c <= 90 || c >= 97 && c <= 122)
{
count++;
w[count - 1] = c;
for (int i = 0; i<3; i++)
{
c = fgetc(fin);
if (c >= 65 && c <= 90 || c >= 97 && c <= 122)
{
count++;
w[count - 1] = c;
}
else
break;
}
if (count == 4)
{
wordnum1++;
c = fgetc(fin);
for (k = count; c >= 65 && c <= 90 || c >= 97 && c <= 122 || c >= 48 && c <= 57; k++)
{
w[k] = c;
c = fgetc(fin);
}
w[k] = '�';
words[num] = (char *)malloc(sizeof(char) * (strlen(w) + 1));
former[num1 + 1] = (char *)malloc(sizeof(char) * (strlen(w) + 1));
latter[num1] = (char *)malloc(sizeof(char) * (strlen(w) + 1));
strcpy(words[num], w);
strcpy(former[num1 + 1], w);
strcpy(latter[num1], w);
hashe(words[num]);
signP = put(former[num1], latter[num1], num1);
if (signP == 1) {
free(former[num1]);
free(latter[num1]);
former[num1] = (char *)malloc((strlen(w) + 1) * sizeof(char));
strcpy(former[num1], w);
free(former[num1 + 1]);
}
else num1++;
}
count = 0;
}
else;
}
return wordnum1;
}
int main(int argc, char *argv[])
{
int k, j, t;
char dir[200];
strcpy(dir, argv[1]);
init();
listFiles(dir);
fout = fopen("Result.out", "w");
for (k = 0; k < 10; k++)
for (j = k + 1; j < MAX; j++)
if (cont[k] < cont[j])
{
t = cont[k];
cont[k] = cont[j];
cont[j] = t;
t = area[k];
area[k] = area[j];
area[j] = t;
}
for (k = 0; k < 10; k++)
for (j = k + 1; j < MAX; j++)
if (prnum[k] < prnum[j])
{
t = prnum[k];
prnum[k] = prnum[j];
prnum[j] = t;
t = loc[k];
loc[k] = loc[j];
loc[j] = t;
}
fprintf(fout, "characters:%d
", characternum);
fprintf(fout, "line:%d
", line);
fprintf(fout, "word:%d
", wordnum);
fprintf(fout, "
the top ten frequency of word:
");
for (k = 0; k < 10; k++)
{
fprintf(fout, "%s:%d
", words[area[k]], cont[k]);
}
fprintf(fout, "
the top ten frequency of phrase:
");
for (k = 0; k < 10; k++)
{
fprintf(fout, "%s %s:%d
", former[loc[k]], latter[loc[k]], prnum[k]);
}
fclose(fout); //close files
return 0;
}
void listFiles(const char * dir)
{
namespace fs = std::experimental::filesystem;
std::string name;
for (auto &p : fs::recursive_directory_iterator(dir))
{
if (!fs::is_directory(p.path()))
{
name = p.path();
fin = fopen(name.c_str(), "r");
characterandlinecollect();
wordnum += everywordcollect();
fclose(fin);
printf("%s close
", name.c_str());
}
}
}
运行之后的结果是:
characters:173654762
line:2278537
word:16639526
the top ten frequency of word:
THAT:259187
SAID:208862
CLASS:192005
HARRY:184733
WITH:158746
THIS:152455
THEY:145946
Span:116119
HAVE:107384
FROM:105495
the top ten frequency of phrase:
span class:62861
that good:61427
span span:41286
class reference:31289
reference internal:26668
internal href:26668
said Harry:24981
class span:23146
href Leap:22569
said Hermione:19193
收获与教训
1.在编程之前要做好充足的准备工作,一定要将设计思路理清楚之后才能着手编程。否则将会无数次的出错,无数次的debug,然而debug的过程是相当痛苦的。
2.我发现自身能力还是很欠缺,看到很多同学用的都是C++语言,而我连一些最基本的C++操作都无法使用。所以这个学期我要开始着手自学C++语言,因为一些操作用C语言的话相当麻烦,而用C++中给定的类就能够轻而易举的解决。此外,我还要开始了解linux系统,我觉得只能在windows系统上写代码的程序员不是真正的程序员。
3.身边一定要多结交编程高手,其实这次编程过程中,我的代码出现了很多问题。而仅凭我的力量,很难在短时间之内找出来问题。所以这次我求助了好几位编程高手,他们在较短的时间内帮我解决了这些问题。与这些高手交流的过程中,我学会了很多东西,但如果仅凭我一个人百度,我估计要花非常多的时间。在感谢他们的同时,我觉得我还是要努力提升自身实力。
4.程序员的心态一定要好。在程序出现问题是一定要从容冷静的处理,不能够只是干着急。要冷静的分析问题可能发生的原因,并一步步的排查。
5.程序的编写是一个循序渐进的过程,所以不能够放在一天突击完成,虽然我在上周末就开始编程了,但是直到本周三,我还没有做好词汇的统计功能。出于对自身能力的错误估计,我认为我在一天之内就能完成剩余的功能。结果导致我最后没有实现所有的要求。这也是本次作业给我的一个遗憾吧。
6.用VS的热行分析来提高代码的运行速度真的超好用啊,这一次我竟然在用热行分析时找到了为什么我的代码运行的慢的原因(前面已经交代了,是排序位置放在循环中导致的)!
其实这次作业给我的收获远远比教训要多,它不但让我了解到了自身的真实能力,对自己有一个清晰的认识,同时也让我领悟到了以上这么多的道理。我觉得我一定会继续努力,积极坦然的面对下一个任务,争取做到不留遗憾。
本次作业,我使用的是github进行源代码管理,地址为:https://github.com/wazjx55/homework_1。
欢迎大家浏览。最后,还是希望各位多多给出意见和建议,尤其是代码的错误,谢谢!