目前只是学习阶段,笔记稍后整理,只记录代码部分
视频地址:https://www.bilibili.com/video/BV1Ja4y1W7as
TensorFlow Windows环境配置,默认安装CPU版本
Python和PyCharm安装这里就跳过了
Anaconda下载
https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/,选择最新版本的,这里我安装的是2020.11版本

安装的时候注意加入系统变量,安装路径尽量不要有中文字符或者空格
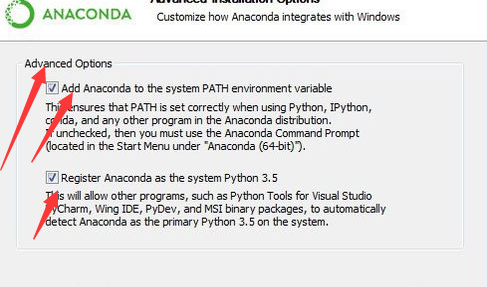
安装好以后需要配置一下清华源
在控制台或者anaconda powershell里面输入
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ conda config --set show_channel_urls yes
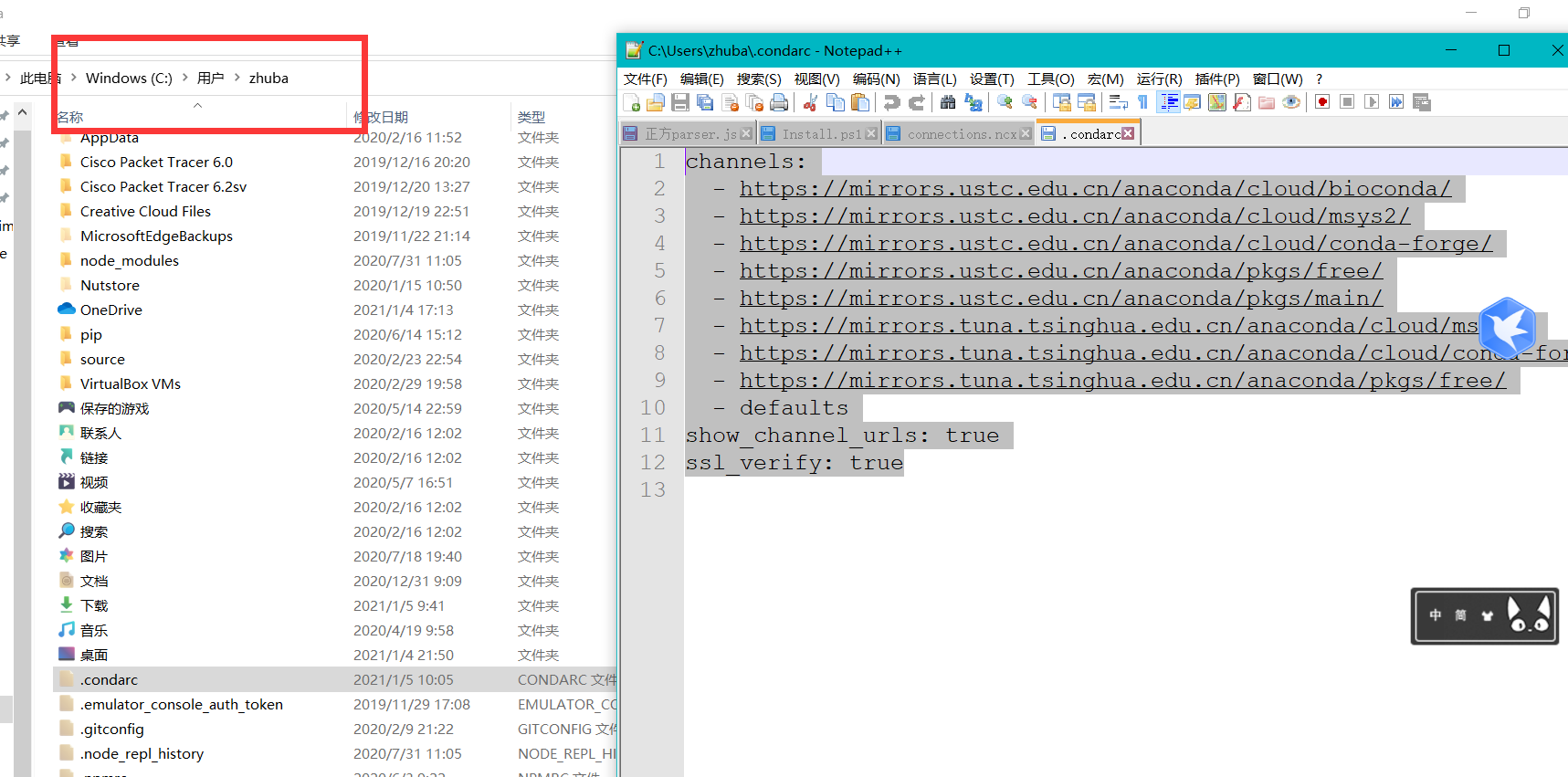
在这里可以查看配置文件,你也可以直接修改
channels: - https://mirrors.ustc.edu.cn/anaconda/cloud/bioconda/ - https://mirrors.ustc.edu.cn/anaconda/cloud/msys2/ - https://mirrors.ustc.edu.cn/anaconda/cloud/conda-forge/ - https://mirrors.ustc.edu.cn/anaconda/pkgs/free/ - https://mirrors.ustc.edu.cn/anaconda/pkgs/main/ - https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/ - https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge - https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ - defaults show_channel_urls: true ssl_verify: true
然后使用pip来安装tensorflow,当然你可以先在anaconda中创建一个虚拟环境再进行安装,我这里直接使用的默认环境
pip install tensorflow
安装好后,到navigator中检查是否安装成功
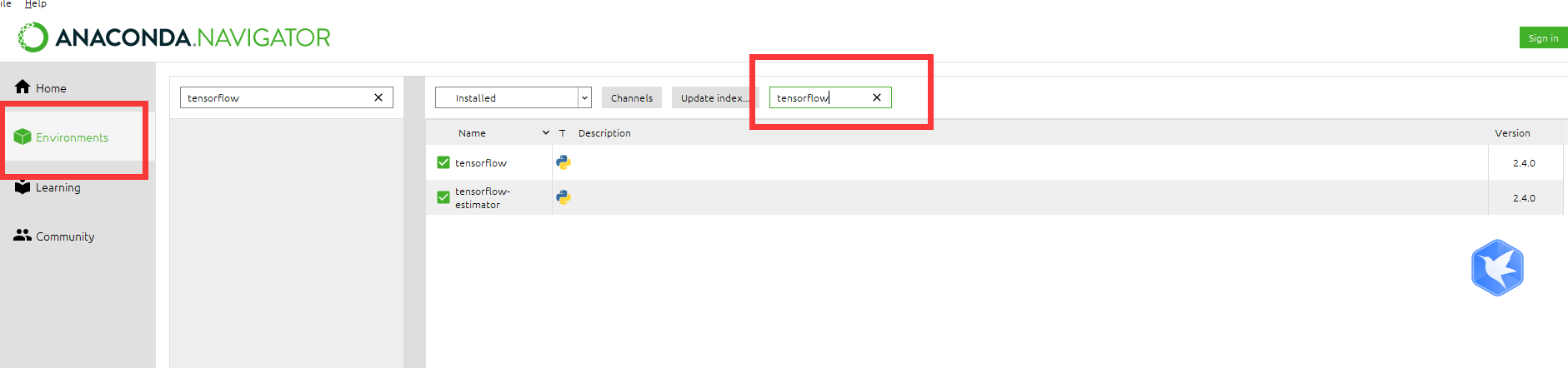
打开anaconda然后进入python,导入tensorflow包如果不报错则说明安装成功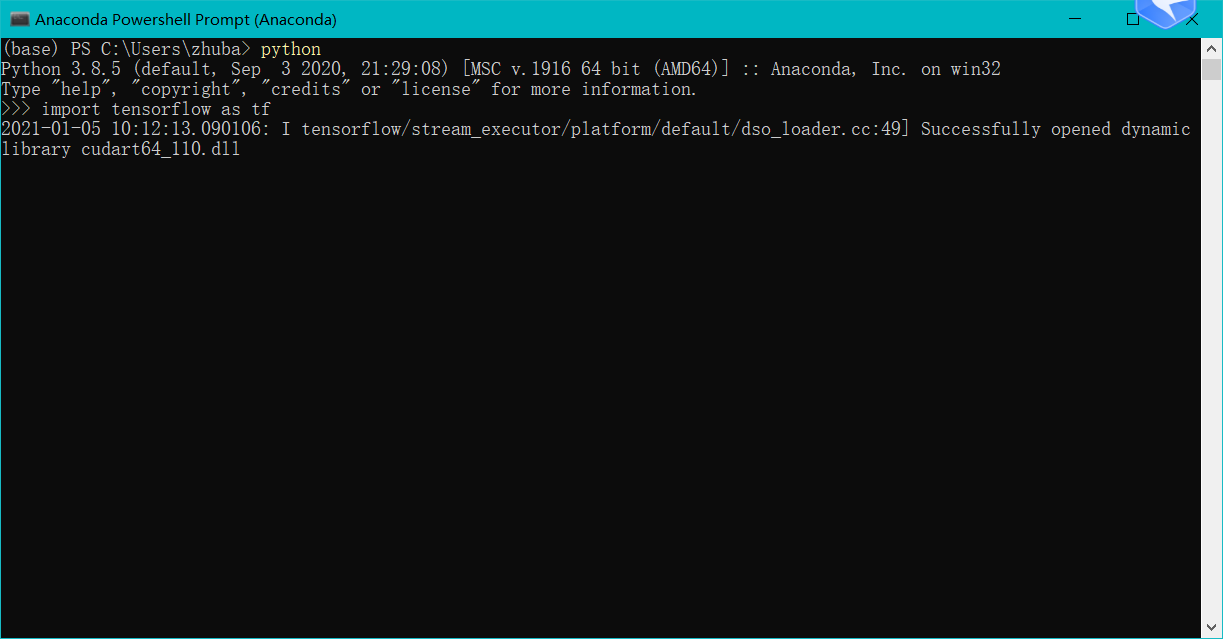
使用pycharm来创建tensorflow项目的时候,虚拟环境请选择anaconda
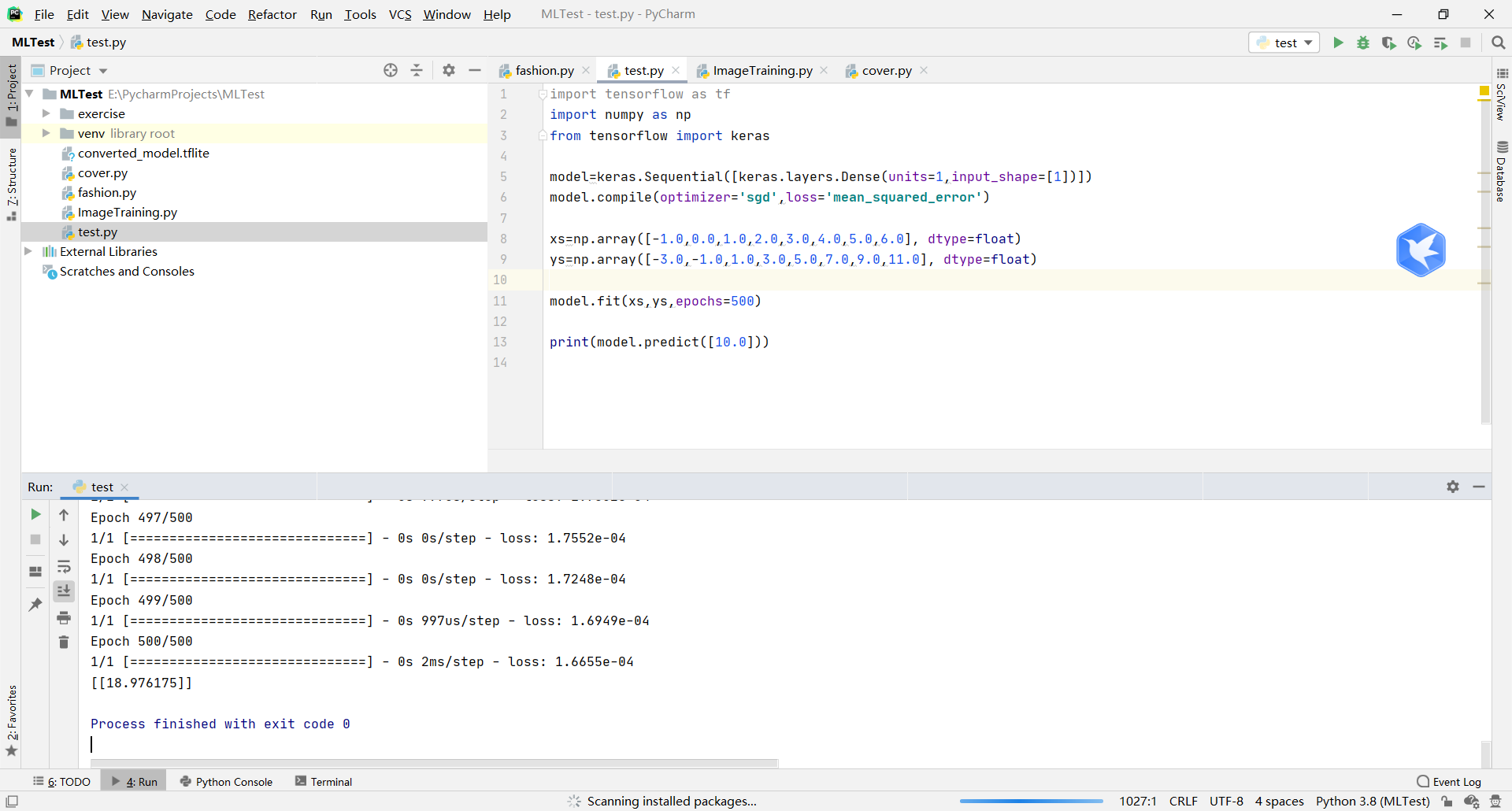
运行下面第一个实例,你应该得到类似如下结果
入门
一维简单预测
import tensorflow as tf import numpy as np from tensorflow import keras model=keras.Sequential([keras.layers.Dense(units=1,input_shape=[1])]) model.compile(optimizer='sgd',loss='mean_squared_error') xs=np.array([-1.0,0.0,1.0,2.0,3.0,4.0,5.0,6.0], dtype=float) ys=np.array([-3.0,-1.0,1.0,3.0,5.0,7.0,9.0,11.0], dtype=float) model.fit(xs,ys,epochs=500) print(model.predict([10.0]))
fashion数据集训练,普通版本
# TensorFlow and tf.keras import tensorflow as tf from tensorflow import keras # Helper libraries import numpy as np import matplotlib.pyplot as plt print(tf.__version__) fashion_mnist = keras.datasets.fashion_mnist (train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data() plt.figure() plt.imshow(train_images[0]) plt.colorbar() plt.grid(False) plt.show() train_images = train_images / 255.0 test_images = test_images / 255.0 class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot'] plt.figure(figsize=(10,10)) for i in range(25): plt.subplot(5,5,i+1) plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(train_images[i], cmap=plt.cm.binary) plt.xlabel(class_names[train_labels[i]]) plt.show() model = keras.Sequential([ keras.layers.Flatten(input_shape=(28, 28)), keras.layers.Dense(128, activation='relu'), keras.layers.Dense(10) ]) model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy']) model.fit(train_images, train_labels, epochs=10) test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2) print(' Test accuracy:', test_acc)
fashion数据集训练,使用卷积神经网络
卷积层加池化层
# TensorFlow and tf.keras import tensorflow as tf from tensorflow import keras # Helper libraries import numpy as np import matplotlib.pyplot as plt print(tf.__version__) fashion_mnist = keras.datasets.fashion_mnist (train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data() train_images = train_images.reshape(60000,28,28,1) train_images=train_images/255.0 test_images=test_images.reshape(10000,28,28,1) test_images=test_images/255.0 class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot'] model = keras.Sequential([ keras.layers.Conv2D(64,(3,3),activation='relu',input_shape=(28,28,1)),#卷积层 keras.layers.MaxPool2D(2,2),#池化层 keras.layers.Conv2D(64,(3,3),activation='relu'), keras.layers.MaxPool2D(2,2), keras.layers.Flatten(input_shape=(28, 28)),#平化 28*28 keras.layers.Dense(128, activation='relu'),#全连接层,relu如果输出小于0就输出0,大于0直接输出 keras.layers.Dense(10,activation='softmax')#全连接层,10个神经元对应10个类别,softmax一般出现在最后一层,将概率最大的设置为1,其他设置为0 ]) model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy']) model.summary() model.fit(train_images, train_labels, epochs=5) test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2) print(' Test accuracy:', test_acc)
自己搭建一个二分类问题
import tensorflow as tf from keras.preprocessing.image import ImageDataGenerator from tensorflow.keras.optimizers import RMSprop train_dir="E://PycharmProjects//LearingImageData//DataSets//train" validation_dir="E://PycharmProjects//LearingImageData//DataSets//var" train_datagen= ImageDataGenerator(rescale=1./255) #统一化处理 train_generator=train_datagen.flow_from_directory( train_dir, target_size=(300,300), batch_size=128,#每次抽出128张图片进行训练 class_mode='binary'#如果只有两类,用binary,多个类别用categorical ) test_datagen= ImageDataGenerator(rescale=1./255) #统一化处理 validation_generator=test_datagen.flow_from_directory( validation_dir, target_size=(300,300), batch_size=128,#每次抽出128张图片进行训练 class_mode='binary'#如果只有两类,用binary,多个类别用categorical ) #搭建一个简单的CNN模型 model= tf.keras.models.Sequential([ tf.keras.layers.Conv2D(16,(3,3),activation='relu', input_shape=(300,300,3)), tf.keras.layers.MaxPool2D(2,2), tf.keras.layers.Conv2D(32,(3,3),activation='relu'),#每个卷积层后面都有一个最大池化层 tf.keras.layers.MaxPool2D(2,2), tf.keras.layers.Conv2D(64,(3,3),activation='relu'), tf.keras.layers.MaxPool2D(2,2), tf.keras.layers.Flatten(), tf.keras.layers.Dense(512,activation='relu'), tf.keras.layers.Dense(1,activation='sigmoid')#3类,0,1,2 ]) #model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), # optimizer=RMSprop(lr=0.001), # metrics=['accuracy']) model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) model.summary() history=model.fit( train_generator, epochs=20, validation_data=validation_generator, steps_per_epoch=2, validation_steps=1, verbose=2) model.save("E://PycharmProjects//LearingImageData//DataSets//finalModel")
Keras模型转TensorFlow Lite
import tensorflow as tf saved_model_dir="E://PycharmProjects//LearingImageData//DataSets//finalModel" converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) tflite_model = converter.convert() open("converted_model.tflite", "wb").write(tflite_model)
特征增强
为了避免过拟合,我们可以使用工具对原图片数据集进行旋转、裁剪等操作来人为增加数据集
import tensorflow as tf from keras.preprocessing.image import ImageDataGenerator from tensorflow.keras.optimizers import RMSprop train_dir="E://PycharmProjects//LearingImageData//DataSets//train" validation_dir="E://PycharmProjects//LearingImageData//DataSets//var" #解决过拟合的问题 train_datagen= ImageDataGenerator( rescale=1./255, rotation_range=40,#随机旋转,-40°到40° width_shift_range=0.2,#平移宽度 height_shift_range=0.2,#平移高度 shear_range=0.2,#错切0-1 zoom_range=0.2,#放大倍数 horizontal_flip=True,#翻转 fill_mode='nearest') #统一化处理
语料分块
import tensorflow as tf from tensorflow import keras from tensorflow.keras.preprocessing.text import Tokenizer from tensorflow.keras.preprocessing.sequence import pad_sequences sentences=[#语料库 'I love my dog', 'I love my cat', 'You love my Dog!', 'Do you think my dog is amazing?' ] tokenizer=Tokenizer(num_words=100,oov_token="<OOV>")#指定想关注的最大单词量,oov为语料库以外的单词指定token tokenizer.fit_on_texts(sentences) word_index=tokenizer.word_index#查看分词器创建的单词索引 sequences=tokenizer.texts_to_sequences(sentences)#为语料库中的单词分配token padded=pad_sequences(sequences,padding='post',maxlen=5,truncating='post')#统一输入长度 print(" Word Index = ",word_index) print(" Sequences = ",sequences) print(" Padded Sequences: ") print(padded) print("测试:") test_data=[ 'I really love my dog', 'my dog loves my manatee' ] test_seq=tokenizer.texts_to_sequences(test_data) print(" Test Sequence = ",test_seq) padded=pad_sequences(test_seq,maxlen=10) print(" Padded Test Sequence: ") print(padded)
搭建一个讽刺新闻标题识别器
json下载地址:https://storage.googleapis.com/laurencemoroney-blog.appspot.com/sarcasm.json
import tensorflow as tf from tensorflow import keras from tensorflow.keras.preprocessing.text import Tokenizer from tensorflow.keras.preprocessing.sequence import pad_sequences import json import numpy as np # 文本分类器 with open("sarcasm.json", "r") as f: datastore = json.load(f) sentences = [] labels = [] urls = [] for item in datastore: sentences.append(item['headline']) labels.append(item['is_sarcastic']) urls.append(item['article_link']) tokenizer = Tokenizer(num_words=100, oov_token="<OOV>") # 指定想关注的最大单词量,oov为语料库以外的单词指定token tokenizer.fit_on_texts(sentences) word_index = tokenizer.word_index # 查看分词器创建的单词索引 print(len(word_index)) print(word_index) sequences = tokenizer.texts_to_sequences(sentences) # 为语料库中的单词分配token padded = pad_sequences(sequences, padding='post') # 统一输入长度 print(padded[0]) print(padded.shape) vocab_size = 10000 embedding_dim = 16 max_length = 32 trunc_type = 'post' padding_type = 'post' oov_tok = "<OOV>" training_size = 20000 training_sentences = sentences[0:training_size] testing_sentences = sentences[training_size:] training_labels = labels[0:training_size] testing_labels = labels[training_size:] tokenizer = Tokenizer(num_words=vocab_size, oov_token=oov_tok) tokenizer.fit_on_texts(training_sentences) word_index = tokenizer.word_index training_sequences = tokenizer.texts_to_sequences(training_sentences) training_padded = pad_sequences(training_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type) testing_sequences = tokenizer.texts_to_sequences(testing_sentences) testing_padded = pad_sequences(testing_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type) training_padded = np.array(training_padded) training_labels = np.array(training_labels) testing_padded = np.array(testing_padded) testing_labels = np.array(testing_labels) # 嵌入 model = tf.keras.Sequential([ tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length), tf.keras.layers.GlobalAveragePooling1D(), tf.keras.layers.Dense(24, activation='relu'), tf.keras.layers.Dense(1, activation='sigmoid') ]) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) num_epochs = 30 history = model.fit(training_padded, training_labels, epochs=num_epochs, validation_data=(testing_padded, testing_labels), verbose=2)