很久之前做的东西。一直没时间分享,今天有空正好分享出来。
想做个爬取唯品会首页的商品分类和链接的脚本。第一反应是用BeautifulSoup。但是在浏览器里调试了很久没有发现链接,无奈只能放弃了使用BeautifulSoup。
尝试了抓包,我们看看下面是抓到的包:
通过多次的抓取,终于抓到了两个接口。然后点击查看两个接口中我们抓到的headers
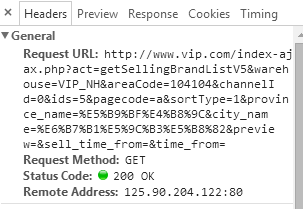
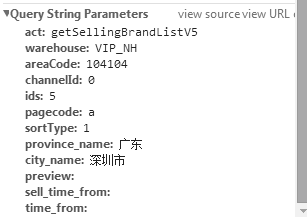
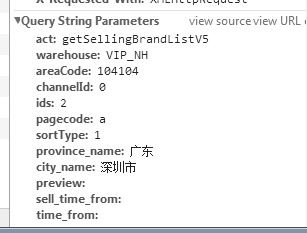
我们可以很清楚的看到,两个接口除了ids这个字段的值不一样,其他的东西都是一样的。我们可以双击打开这两个接口,就会发现里面返回的内容正好是我们想要的东西,而且还是json格式,简直不要太方便啊。那么接下来就可以通过接口去访问以下这个接口,进行尝试。
import requests
import json
headers = {
"host":"www.vip.com",
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36 Core/1.47.933.400 QQBrowser/9.4.8699.400",
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8"
}
ssesion = requests.session()
url1 = "http://www.vip.com/index-ajax.php?act=getSellingBrandListV5&warehouse=VIP_NH&areaCode=104104&channelId=0&"
url2 = "&pagecode=a&sortType=1&province_name=%E5%B9%BF%E4%B8%9C&city_name=%E6%B7%B1%E5%9C%B3%E5%B8%82&preview=&sell_time_from=&time_from="
def get_classify():
url =url1+"ids="+str(2)+url2
responed = ssesion.get(url,headers=headers).text
response = json.loads(responed)
print(response)
get_classify()
运行之后结果如下

OK,我们的到了这个,然后怎么去获得品牌和链接呢?似乎难度不小
首先我要看一下这个到底是什么数据类型,才可以知道接下来怎么操作才能得到我需要的内容。
使用print(type(response))来检查数据类型。
我们可以看到结果是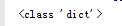
字典类型的数据。很好,知道了数据类型,接下来我们来看看到底是个几层的字典。
使用print(len(response))
我们可以看到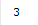
好吧,是一个三层的嵌套的字典。那么就好办了。json的解析,必须是像剥洋葱一样,一层一层的去解析,这点比较苦逼,不过也不是没有办法。
我这里是通过取key的值,一步一步的剥离到了里面。
data = response['data']
floors = data['floors']
加入这两行之后,再打印floors看看我们得到了一个什么东西

已经剥离出了外面的两层字典。我们查找一下,会发现我们需要的品牌名称和链接,是在这个字典的一个叫items的数组中。
items = floors[str(2)]["items"]
for i in items:
print(i["name"], i["link"])
我们通过上面的第一句,去获得这个字典中的key为items的内容,也就是刚才说的那个items的数组,然后使用一个for循环,遍历数组,打印出数组中的name和link对应的值。
运行一下,看看结果:

对照着唯品会首页的第二个分类检查一下,似乎品牌都没有错呢。点击各个链接也都能正常的跳转过去。
这里已经实现,那么接下来就来完成对前7个分类的品牌及链接的爬取就很简单了:
import requests
import json
headers = {
"host":"www.vip.com",
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36 Core/1.47.933.400 QQBrowser/9.4.8699.400",
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8"
}
ssesion = requests.session()
url1 = "http://www.vip.com/index-ajax.php?act=getSellingBrandListV5&warehouse=VIP_NH&areaCode=104104&channelId=0&"
url2 = "&pagecode=a&sortType=1&province_name=%E5%B9%BF%E4%B8%9C&city_name=%E6%B7%B1%E5%9C%B3%E5%B8%82&preview=&sell_time_from=&time_from="
def get_classify():
for i in range(1,8):
url =url1+"ids="+str(i)+url2
responed = ssesion.get(url,headers=headers).text
response = json.loads(responed)
data = response['data']
# print(len(response))
#分层解析json数据
floors = data['floors']
# print(floors)
items = floors[str(i)]["items"]
#遍历items打印出店铺名字和url
for i in items:
print(i["name"],i["link"])
get_classify()
就像我们前面讲到的,这些接口也仅仅只是ids的字段不同,而且还是有序的。所以在这里,我就利用一个循环和range()方法来实现对前七个分类商品的接口的访问。
爬取唯品会的这一段小代码里,最难的应该就是json的解析。当然仅仅是对我来说哈,毕竟菜鸡一枚。json的数据解析也算是入门的最基础的东西了,也希望大家都能记住哈,这个解析必须一层一层的来。