Hash索引:
哈希索引基于哈希表实现,只有精确索引所有列的查询才有效,对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码,哈希码是一个较小的值,并且不同键值的行计算出来的哈希码不一样,哈希索引将所有的哈希存储在索引中,同时在哈希表中保存指向每个数据的指针
MySQL中,只有Memory存储引擎显示支持hash索引,是Memory表的默认索引类型,尽管Memory表也可以使用B-Tree索引,Memory存储引擎支持非唯一hash索引,这在数据库领域是罕见的,如果多个值有相同的哈希码,索引把它们的行指针用链表保存到同一个hash表项中
CREATE TABLE testhash ( fname VARCHAR(50) NOT NULL, lname VARCHAR(50) NOT NULL, KEY USING HASH(fname)) ENGINE=MEMORY;
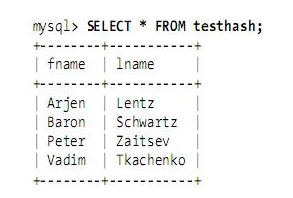
假设索引使用hash函数f( ),如下: f('Arjen') = 2323 f('Baron') = 7437 f('Peter') = 8784 f('Vadim') = 2458
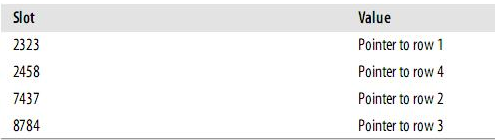
mysql> SELECT lname FROM testhash WHERE fname='Peter';
因为索引自己仅仅存储很短的值,所以,索引非常紧凑。Hash值不取决于列的数据类型,一个TINYINT列的索引与一个长字符串列的索引一样大
hash索引有以下一些限制:
由于索引仅包含hash code和记录指针,所以,MySQL不能通过使用索引避免读取记录,但是访问内存中的记录是非常迅速的,不会对性能造成太大的影响
不能使用hash索引排序
hash不支持键的部分匹配,因为是通过整个索引值来计算hash值的
hash索引只支持等值比较,例如使用=、IN()、<=>,对于WHERE price>100并不能加速查询
访问hash索引的速度非常快,除非有很多的hash冲突(不同的索引列值却有相同的hash值);当出现hash冲突时,存储引擎必须遍历链表中的所有行指针,逐行及你想那个比较,知道找到所有符合条件的行
如果hash冲突很多的话,一些索引维护操作的代价也会很高,当从表中删除一行时,存储引擎要遍历对应hash值的链表中的每一行,找到并删除对应行的引用,冲突越多,代价越大
InnoDB引擎有一个特殊的功能叫做“自适应哈希索引
当InnoDB注意到某些索引值被使用得非常频繁时,它会在内存中基于B-Tree索引上再创建一个哈希索引,这样就上B-Tree索引也具有哈希索引的一些优点,比如快速的哈希查找 创建哈希索引:如果存储引擎不支持哈希索引,则可以模拟像InnoDB一样创建哈希索引,这可以享受一些哈希索引的便利,例如只需要很小的索引就可以为超长的键创建索引 思路很简单:在B-Tree基础上创建一个伪哈希索引。这和真正的哈希索引不是一回事,因为还是使用B-Tree进行查找,但是它使用哈希值而不是键本身进行索引查找 你需要做的就是在查询的where子句中手动指定使用哈希函数。这样实现的缺陷是需要维护哈希值。可以手动维护,也可以使用触发器实现 如果采用这种方式,记住不要使用SHA1和MD5作为哈希函数。因为这两个函数计算出来的哈希值是非常长的字符串,会浪费大量空间,比较时也会更慢。
SHA1和MD5是强加密函数,设计目标是最大限度消除冲突,但这里并不需要这样高的要求。简单哈希函数的冲突在一个可以接受的范围,同时又能够提供更好的性能。 如果数据表非常大,CRC32会出现大量的哈希冲突,CRC32返回的是32位的整数,当索引有93000条记录时出现冲突的概率是1%。 处理哈希冲突:当使用哈希索引进行查询时,必须在where子句中包含常量值。
B-Tree索引:
R-Tree索引:
MyISAM支持空间索引,主要用于地理空间数据类型,例如GEOMETRY
Full-Text索引:
全文索引是MyISAM的一个特殊索引类型,他查找的是文本中的关键词,主要用于全文检索
索引的优点:
最常见的B-Tree索引,按照顺序存储数据,所以MySQL可以用来做ORDER BY和GROUP BY操作,因为数据是有序的,所以B-Tree也就会将相关的列值存储在一起,最后,因为索引中存储了实际的列值,所以某些查询只使用索引就能够完成全部查询
索引可以大大减少了服务器需要扫描的数据量
索引可以帮助服务器避免排序和临时表
索引可以将随机IO变成顺序IO
索引三星系统:
一星:索引将相关的记录放到一起
二星:索引中的数据顺序和查找中的排列顺序一致
三星:索引中的列包含了查询中需要的全部列
*****************************************索引问题******************************************************
什么存储支持什么索引类型?
组合索引和多个索引顺序比较?
索引的选择性?
前缀索引为什么无法做order by 和 group by操作?
按索引排序时为什么是将一条记录移动到紧接着的下一条记录?