1. 排序算法很多,常见的有冒泡/插入/选择 O(n^2)、归并/快速 O(nLogn)、桶排序/计数/基数O(n)。
2. 排序过程中,我们需要考虑算法
a. 原地算法,即不需要额外的空间
b. 是否是稳定的算法, 保持原有的顺序不变。比如按照一个对象的多个属性排序,稳定排序算法更好实现,效率更好。
c.最好、最坏、平均时间复杂度,有的特定数据情况下,某些算法时间复杂度会退化。
我们知道,时间复杂度反映的是数据规模 n 很大的时候的一个增长趋势,所以它表示的时候会忽略系数、常数、低阶。
但是实际的软件开发中,我们排序的可能是 10 个、100 个、1000 个这样规模很小的数据,所以,在对同一阶时间复杂度的排序算法性能对比的时候,我们就要把系数、常数、低阶也考虑进来。
3. bubbleSort排序优化,设置一个flag去判断是否还有交换操作,提前退出比较,提高效率。
// 冒泡排序,a表示数组,n表示数组大小 public void bubbleSort(int[] a, int n) { if (n <= 1) return; for (int i = 0; i < n; ++i) { // 提前退出冒泡循环的标志位 boolean flag = false; for (int j = 0; j < n - i - 1; ++j) { if (a[j] > a[j+1]) { // 交换,每一轮冒一个最大或者最小的元素到末尾 int tmp = a[j]; a[j] = a[j+1]; a[j+1] = tmp; flag = true; // 表示有数据交换 } } if (!flag) break; // 没有数据交换,提前退出 } }
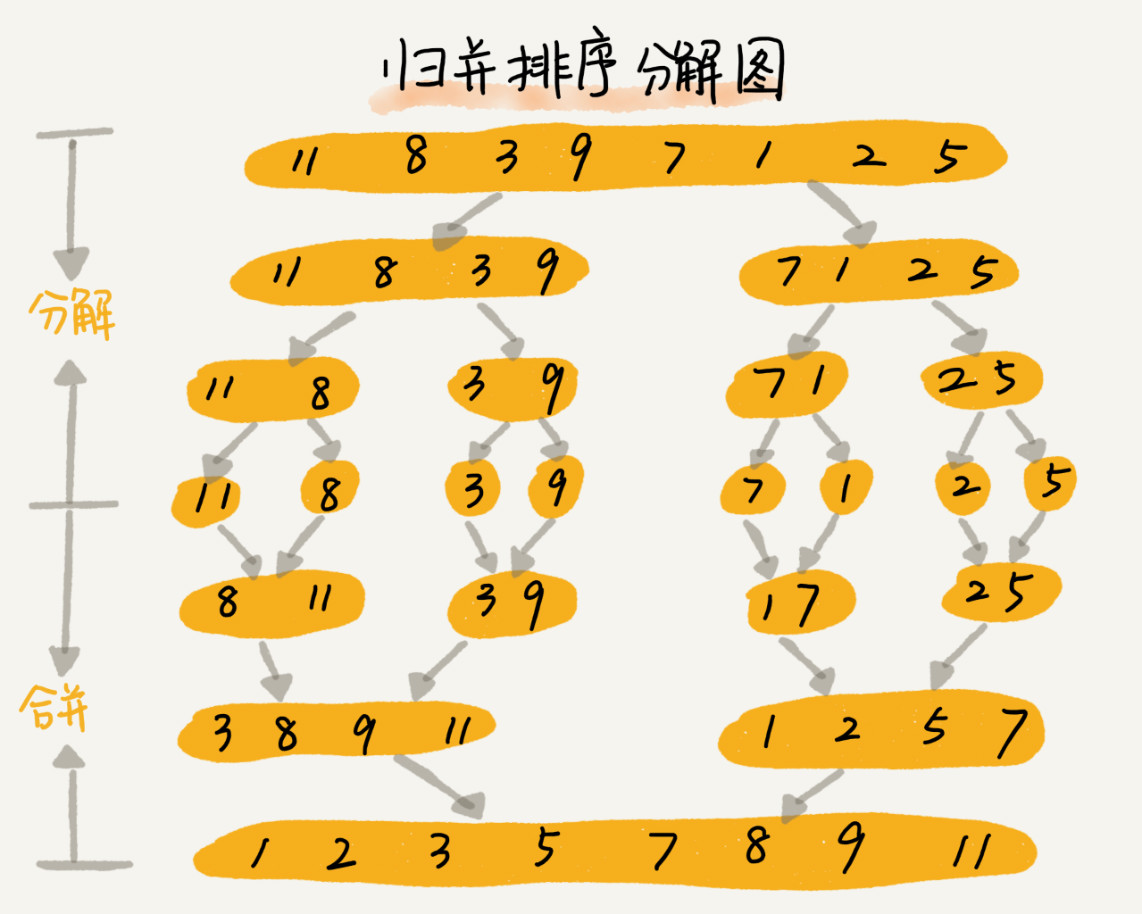
4. 归并排序,核心是把一个数组从中间分成2个数组分别排序,然后在合并两个有序数组成一个数组,结果就是有序的了。本质是分治的思想,采用递归这种变成技巧来实现,注意归并排序不是原地排序算法,100M的数据,还需要100M的额外空间,所以实际使用比较少,虽然他们最好、最坏、平均时间复杂度都是O(nLogn)。
5. 快排是一致出镜率很高的排序算法,他的平时时间复杂度是O(nLogn),他也是分治递归的思想。
如果要排序数组中下标从 p 到 r 之间的一组数据,我们选择 p 到 r 之间的任意一个数据作为 pivot(分区点)。我们遍历 p 到 r 之间的数据,将小于 pivot 的放到左边,将大于 pivot 的放到右边,将 pivot 放到中间。
它的难点在于中间数pivot的选择,希望尽可能的分割出两个元素差不多的区间,算法的时间复杂度才不会退化,有时候我们可以从一批数据中随机选一个,比如最后一个。有时候为了更好,可以从从数据的前,中,后,分别取1个数出来,选位于中间那个数。
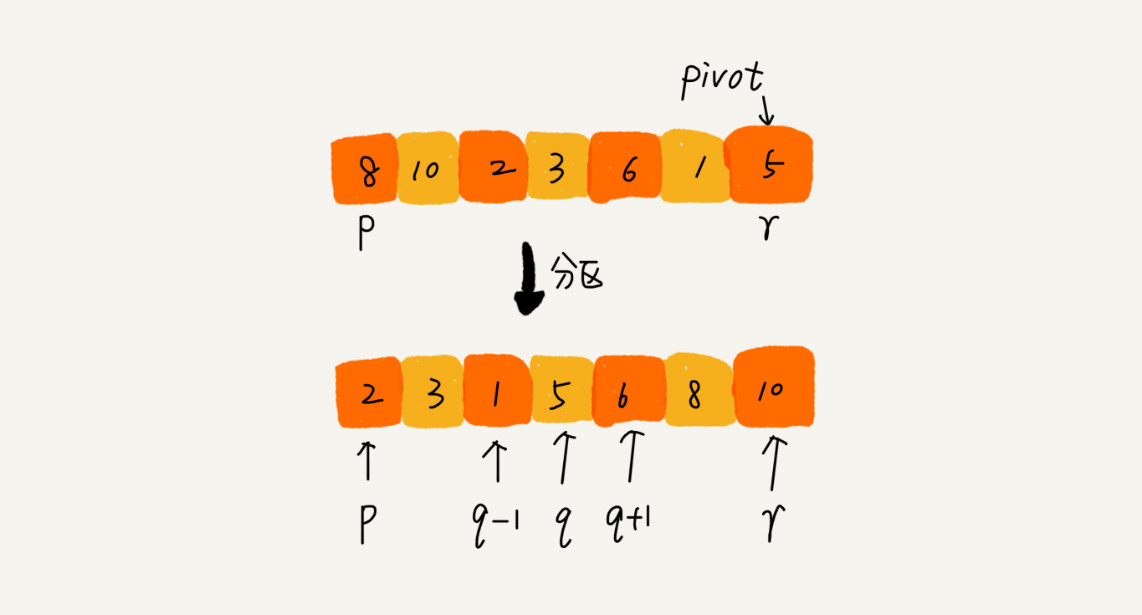
private static void quickSortC(int[] a, int p, int r) { if (p >= r) { return; } int q = partition(a, p, r); quickSortC(a, p, q - 1); quickSortC(a, q + 1, r); } public static int partition(int[] a, int start, int end) { int pivot = a[end]; int i = start; for (int j = start; j < end; j++) { if (a[j] < pivot) { swap(a, i, j); i = i + 1; } } swap(a, i, end); return i; }
6. 归并排序和快速排序是两种稍微复杂的排序算法,它们用的都是分治的思想,代码都通过递归来实现,过程非常相似。理解归并排序的重点是理解递推公式和 merge() 合并函数。同理,理解快排的重点也是理解递推公式,还有 partition() 分区函数。归并排序算法是一种在任何情况下时间复杂度都比较稳定的排序算法,这也使它存在致命的缺点,即归并排序不是原地排序算法,空间复杂度比较高,是 O(n)。正因为此,它也没有快排应用广泛。快速排序算法虽然最坏情况下的时间复杂度是 O(n*n),但是平均情况下时间复杂度都是 O(nlogn)。不仅如此,快速排序算法时间复杂度退化到 O(n*n) 的概率非常小,我们可以通过合理地选择 pivot 来避免这种情况。
7. 工程级别的排序算法,如某种语言的库方法,往往是由多种算法组合使用,根据数据规模而动态变化。比如数据量少时,就可以采用归并排序,即使消耗点内存没什么关系,而对于大数据量或者内存紧张的场合,就采用如快排等原地排序算法。并且一定注意的是,O(n^2)不一定比O(nLogn)慢,因为我们可能讨论的算法时间复杂度只是一种局势,实际中我们可能忽略了低阶、常量等因子。
应用
数组中的第K大个数。
比如,4, 2, 5, 12, 3 这样一组数据,第 3 大元素就是 4。我们选择数组区间 A[0…n-1]的最后一个元素 A[n-1]作为 pivot,对数组 A[0…n-1]原地分区,这样数组就分成了三部分,A[0…p-1]、A[p]、A[p+1…n-1]。如果 p+1=K,那 A[p]就是要求解的元素;如果 K>p+1, 说明第 K 大元素出现在 A[p+1…n-1]区间,我们再按照上面的思路递归地在 A[p+1…n-1]这个区间内查找。同理,如果 K<p+1,那我们就在 A[0…p-1]区间查找。