阿里巴巴微服务与配置中心技术实践之道
原创: 坤宇 InfoQ 2018-02-08
在面向分布式的微服务系统中,如何通过更高效的配置管理方式,帮助微服务系统架构持续“无痛”的演进,动态调整和控制系统的运行时飞行姿态,值得我们好好的在配置管理上重新思考和设计。别让您的微服务被配置管理“绊”了一跤!
本文是阿里巴巴高级技术专家 @坤宇在 2017 年 QCon 微服务专题演讲中关于微服务与配置中心的演讲实录的文字版,演讲视频可以参见:
http://www.infoq.com/cn/presentations/micro-service-and-configuration-center?spm=a2c4e.11153940.blogcont332358.36.30772099lWiw8H。
QCon 北京 2018 正在招募中,对微服务架构与治理专题感兴趣请戳 阅读原文 了解详情!
阿里巴巴集团早在 2007 年进行从 IOE 集中式应用架构升级为互联网分布式服务化架构的时候,就意识到在分布式环境中,传统的分散式的、基于配置文件的、应用自包含的配置管理方式将面临重大挑战,亟需设计匹配新架构的新的配置管理解决方案,解决诸如分布式服务治理,数据源容灾切换,异地多活,预案,限流规则等场景下的配置变更以及热生效问题,这直接诞生了今天阿里集团内部被广泛使用的配置中心 ACM(Diamond),而这也是目前世界上最大的配置中心,存储了超过百万的生产配置,在集团内部支持了包括淘宝、天猫、菜鸟、阿里云、高德等全网几乎阿里所有的应用,每天产生近 10 亿次的配置变更推送。
写在前面
在“史前”单体巨兽型应用时代,配置管理不是什么大不了的事情,但今天在微服务架构中,配置管理已发生革命性的变化,但业内对这一块的前沿探索一直处于秘而不宣的状态,如果我们对这块没有过深入的思考和实践,我们很难真正理解为什么 Spring Cloud 会提出 Configuration Service 的概念。 在面向分布式的微服务系统中,如何通过更高效的配置管理方式,帮助微服务系统架构持续“无痛”的演进,动态调整和控制系统的运行时飞行姿态,值得我们好好的在配置管理上重新思考和设计。
正 文
我的这个话题只能算是今天微服务架构专题中的一个开胃小菜,可以说我们是直接进入了微服务实干里面,即微服务的配置管理这一块。我不知道在座的有多少人意识到,我们讲微服务可能有很多的挑战,比如像运维啊,测试啊,有很多的跟以前单体应用开发时有不一样的挑战,那关于“配置”这个以前我们司空见惯的东西,它也有一些新的挑战。很多人还没有意识到,在微服务架构底下,配置管理也会成为一个挑战。
讲到配置管理这个问题域,我们要提到一个核心的概念——“配置”。我们人比较有意思的地方在于,有的时候,一些司空见惯的东西,我们反而缺乏对它本质的思考,那“配置”的本质是什么东西呢?配置的表象,我们可能知道,一个配置项可能是 key-value,value 可能是一个有限值的集合,配置我们都不陌生,一个系统没有提供几个配置参数的话,可能都不好意思上线跟别的系统打招呼,为什么是这个样子呢?从我的理解来说,本质上是因为我们人类没有办法掌控和预知一切,所以我们映射到软件系统这个领域,需要人为的预留一些线头,以便在未来,拨弄这些线头调整系统的飞行状态。所以我觉得配置是 程序运行时动态调整行为的能力 的一种手段,而且这个是上到生产,在运行时想调整行为的几乎唯一的一个手段。

下面我们来看一个例子,大家可能会对刚才的这一点有一个更直观的感受。

我们都知道,在生产环境上我们可能把我们的日志级别调整为 error 级别,但是,在系统出问题我们希望对它 debug 的时候,我们需要动态的调整系统的行为的能力,把日志级别调整为 debug 级别,这是一个非常简单的例子。
在单体应用时代,或者说在集中式应用开发时代,我们应用可能就是打成一个包,那在这个包里我们可能提供一些配置文件,当我们的系统上到生产环境之后,如果我们需要修改系统的行为,我们只需要登录到机器,修改一下配置文件,然后 reload 一下,实际上不是什么大的负担。
首先,微服务系统天然就是一个分布式系统,那在分布式系统中,我们有没有可能登陆机器一台一台地改配置文件呢?尤其像现在的分布式系统规模越来越大。第二点,不同的微服务是由不同的团队,不同的组织去负责开发和维护的,微服务架构给大家承诺的是,每个微服务可以采用不同的技术栈,在这种情况下,我们作为运维人员,作为 Ops,甚至不知道配置文件在哪里,因为配置文件名,配置文件放置的目录,可能是五花八门,所以没有办法去做基于配置文件的管理。大规模的分布式系统可能部署在不同的机房,有各种部署,那当一个配置改变了之后,这个配置什么时候生效的,它有没有生效,有多少机器上,配置变更了,但是失败了。
这些状态,通过配置文件是没办法明确地把这些状态暴露出来的,简单的来说,应用暴露了哪些配置,你依赖的那些三方的服务,其它团队开发的服务,到底暴露了哪些配置参数,可能这个简单的问题通过配置文件管理的时候,我们都没有办法回答。再不用说分布式系统中某一些子系统我们想一致性的改变它们的行为的话,还有比如配置如何容灾,配置文件如果丢失了,我要回滚到某一个历史版本,这个事情怎么做?这些都是采用微服务分布式架构给配置管理带来的挑战。
984 年在 IEEE 上发表了一篇论文,论文的题目就是《分布式系统的动态配置》
在这篇论文里,这两位老哥对分布式系统的理解可能还没有达到今天的这个层次,当时他们可能也想象不到分布式系统后来发展到今天这么庞大,这么复杂。但是他们对动态配置这个领域的问题看得是比较清楚的,就是在一个大型的分布式系统中,你没有办法把整个分布式系统停下来,去做一个软件的、硬件的或者系统的升级。
我们上面看了分布式系统给配置管理带来的一些挑战以及大概地介绍了一下淘宝的配置中心的发展历程,淘宝的配置中心发展到今天大概存储了超过百万的生产配置,每天要产生几个亿的配置推送,可以说是现在世界大规模上生产的一个配置中心,那我们下面来看一下,配置中心在哪些关键的场景下,可以发挥一些关键的作用,我这里举三个例子,给大家一个直观的感受,第一个是大促预案:

第二个案例是大规模数据容灾:
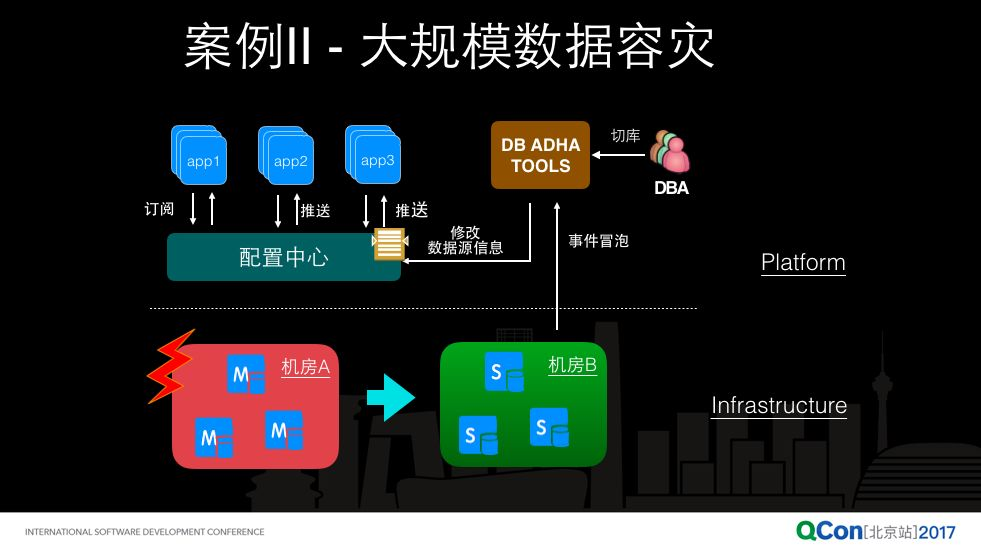
最早淘宝配置中心产生的原因之一就是当时我们要解决大规模数据容灾的问题。一般来说,为了高可用,业务可能部署在 2 个机房,现在一般同城双机房是标配。数据存储,比如像 mysql,在生成上我们为了高可用,可能会配备一主几备,主库是可写的,备库可能是只读的。在生产上可能有几台机器坏了或者甚至一个机房坏了,出问题、故障了,基础设置(infrastructure)这一块,可能有一些事件冒泡到软件平台 PaaS 这一层,这个时间冒泡一般会到 DBA 团队的一些数据库高可用基础设施,DBA 会根据整个业务系统在机房的部署拓扑,来找到这个坏掉的机房里的所有的主库,来做一个主备库的切换,把备库切成可写。在这个过程中,配置中心的作用呢,就是跟 DBA 的高可用切换工具保持联动,DBA 工具负责数据库切换,产生数据源配置变更,所有应用基于配置中心监听各自的数据源配置变更,当产生主备库切换,配置中心会将数据源配置变更推送到应用,整个过程对应用是透明的,无感知的。应用是不用知道底下机房出问题了,主备库出现切换了。
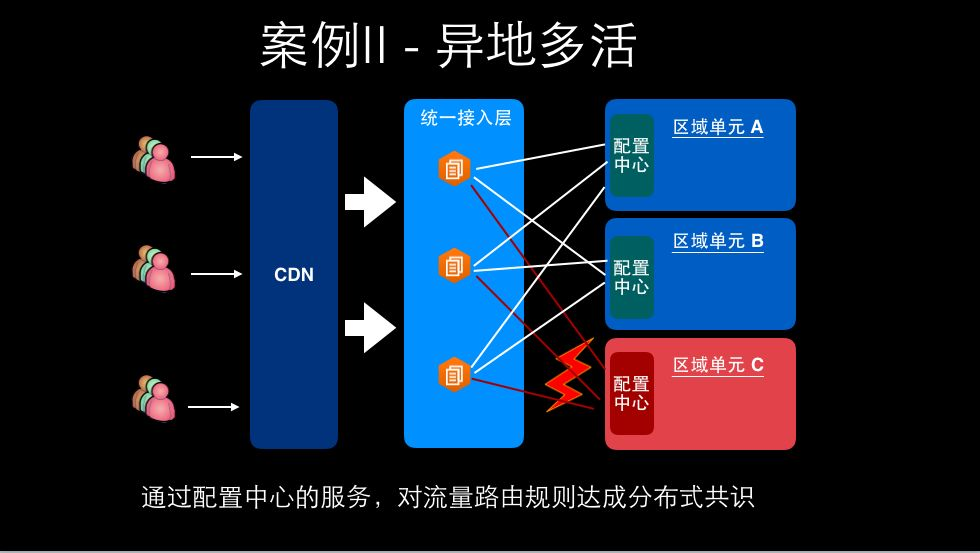
第三个例子是异地多活:
下面我们讲讲配置中心设计中的技术决策。
第一个点,我们都知道,做一个分布式系统本身我们要有一个基本的意识,那就是系统一定会挂,而且是在你想象不到的时间点挂。作为一个配置中心,当所有的系统都依赖你去做配置管理的时候,就必须回答一个问题:当你挂了,其它人怎么办?所以一定要仔细地去看这个场景底下我们怎么去处理。这个里面对配置中心有几个关键的技术决策点,从逻辑上来说其它业务系统对于配置中心的依赖应该是一个弱依赖,做分布式系统的相信很多人都应该知道强弱依赖的一个概念。
为什么是弱依赖?最基本的一个道理,当业务系统即依赖配置中心的这些系统,当它们不需要调整系统行为能力的时候,它其实是不用 care 这个时候配置中心服务到底在不在的,所以当我的配置中心服务挂掉的时候,影响应该是有限的。也就是说这时候业务系统该做的业务还是在做,只要不做一些系统行为的调整,你的系统应该能正常的跑。要达成这一点,这里面就是说配置中心提供的客户端或者 SDK 其实应该实现客户端缓存。
还有一个就是配置应该是稀疏变更的,没有人会不断的调整系统的行为玩儿,比如一会把日志级别调整为 error 一会调整为 trace,这么玩是不对的,在稀疏变更的这个条件下,客户端缓存的价值是巨大的,如果一个数据变化约频繁,那么做缓存得到的价值越小。所在在配置管理这个场景,客户端缓存就能达到 2 个方面的诉求,1 个是刚才说的容灾,配置中心挂了,应用可以从本地客户端的缓存该重启还可以重启,另外也可以通过缓存达到改善性能的目的,从容灾的另一个角度来看,配置本身的存储需要容灾。配置是不能丢的,好多应用我的各项配置好不容易调整好了,然后换了一拨人来维护应用,可能他们根本都不知道这些配置都是干嘛的,这是你作为一个配置中心,你把人家的配置搞丢了,应用可能就起不来,甚至找不回来了,这个是不允许的。
第二点,配置中心关键的是 SLA。我们知道每个系统的 SLA 都很重要,配置中心的 SLA 讲究的是推送,推送的时延和推送的成功率,根据我们的经验,配置的推送,推送到依赖的业务方进程,虽然越快越好,但如果配置中心做不到,一般上限 3 秒以内是 ok 的。因为基于人登录多台机器上去改配置然后生效一般都是超过 3 秒的。比如一个配置变更要推送到 1000 台机器,那么每台机器上配置生效的时间在 3 秒内是 ok 的。
推送的成功率是 SLA 的另一个方面,比如说 10000 台机器,我能达到只有 100 台机器可能配置变更没有推送到,那一般在这个场景和规模下也是 ok 的。当然所有的 SLA 要求是越高越好,比如淘宝的配置中心现在基本要求是推送时延在 200ms 内,成功率要在 4 个 9 的。如果配置中心 SLA 达不到要求,那么大家是不敢从本来很可靠的配置文件,切换到外部依赖的配置中心的。

配置中心技术决策第三点是灰度。有些配置就像家里的电源开关一样,我按开关不会发生什么大事,但有些开关对于公司是核武器级别的,比如像全局路由规则,全局的限流规则,可能一个按钮下去,公司就炸了,就是全局的流量都进不来了,或者像上面说的整个单元的路由规则都乱了,这个时候可能就造成大的社会事件了。在这种场景下实际上就是要求配置中心有灰度的功能,什么意思呢?就是我先推一个配置到几台机器上试一试,要给业务方这种能力,而且这个灰度能力跟业务方发布时的灰度的能力应该是解耦的,因为应用已经在线上跑了,这个时候我们不用做发布,我们是动态的修改系统的行为能力,也就是说配置中心在支持业务本身的灰度发布之外也要支持配置的单独的灰度的能力。

最后一个,是当我们把配置放在配置中心集中管控之后,实际上这里也涉及一个 DevOps 相关的话题,也就是说,以前单体应用时代,很多的线上运维操作,比如配置的变更可能是由运维人员来完成的。在微服务时代,在配置集中到配置中心管理平台之后,很多配置可以交给系统的开发人员自己去负责配置的变更。
另外配置中心需要提供配置变更审计的能力,在一个大型的分布式系统可能每天都有故障产生,故障我们知道常常都是由一个变更引起的,变更包括几个方面,包括代码的变更,配置的变更,配置中心一定要提供说当前这个时间点,有哪些系统变更了哪些关键的配置,这个能力实际上是要有的。另外一个场景比如说像大促,封盘了,不允许有任何人在线上配置的变更,除了像刚才说的像大促预案这种计划内的配置变更,这种时候,因为配置中心是配置管理的一个集中式的入口,很容易就达到这个目的。那以分散的配置文件的方式以前是没法做到的。
上面讲了这么多的配置中心的一些关键技术特性和决策点,下面我们整体看一下一般一个配置中心的架构和技术:
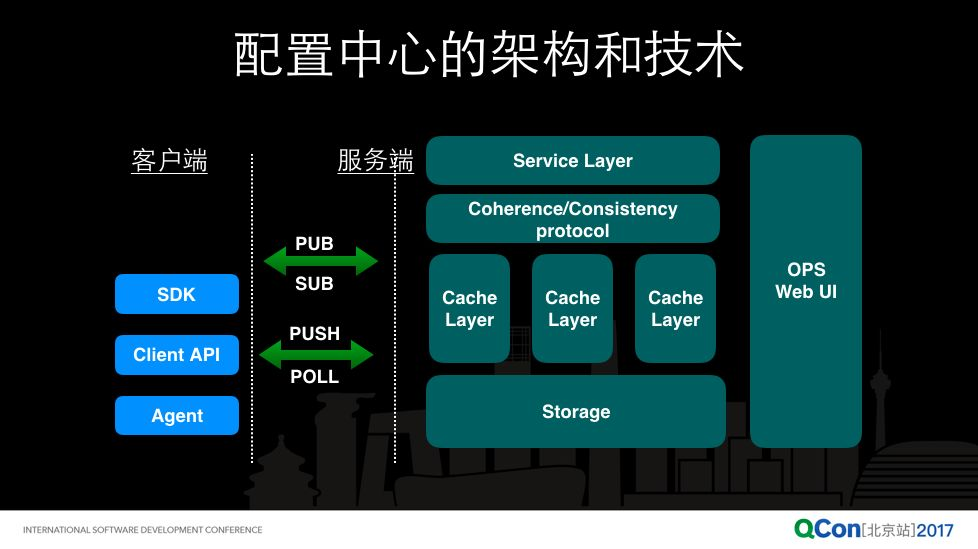
这里我们没有具体的讲某个技术栈,因为我觉得很多的选型时根据自己的需要,选什么都可以。但是作为一个可以上大规模生产的配置中心,我觉得这些一定是要有,一个是配置的存储,刚才讲过配置是不能丢的,所以如果说完全基于内存缓存做肯定是不靠谱的,比如我们几个配置的副本,怎么做配置存储的容灾的切换。
第二个,当基于微服务的架构起来之后,所有的业务系统都依赖配置中心的时候,可能数据中心的所有机器都与配置中心有连接,如果只选一个存储,可能是无法支持这么大量的读的,所以上面可能需要一个可以横向扩展的缓存集群里,再上面你要解决的是配置一定要有一致性,能在各个缓存节点上快速的将配置值达到一个一致的一个状态,然后你需要把配置中心的服务开放成一个 service。
在客户端来讲基本上有 2 种模式,一种是 SDK 或者说客户端 API,这个为什么我们一般不通过配置中心暴露 Restful 服务,让业务方直接调用 Restful 接口呢?就像刚才说的,客户端从容灾的角度来说,你是需要客户端缓存的。这种场景下,配置中心最好提供成熟的客户端 SDK,把客户端容灾考虑好,不用每个业务方自己都要考虑容灾。
考虑客户端缓存,第二种模式是 agent 模式。现在这种模式是越来越重要的,它会在每个业务机器上有一个自己的 agent,业务的进程和 agent 之间要么通过进程间通信,要么通过本地一个标准的目录,通过本地文件来做配置变更的消费。配置中心客户端与服务端之间,除了我们常见的拉取的模式,配置中心一定要实现推的模式,技术实现方式无所谓,可以用 http2.0、long polling、websocket,但推的模型一定要有。因为配置有了变更之后,你是要推送到业务放的,以为这样是最实时的,另外客户端要实现订阅的模式,跟消息系统很类似的,一般配置中心也是一个 PUB-SUB 系统,那他跟消息系统的区别是什么呢?消息系统是一个消息消费完了,会从消息服务器上删掉了,但是配置有可能存 3 年 5 年,配置变更消费完,配置还是在的。
接下来我们看一下,业界的现状。业界的现状也是在从配置文件逐渐转向中心化的管理配置,然后逐渐发展到不再是以文件的思路去管理配置,这里左边是一些业界著名的客户端 SDK,比如像第一个 OWNER,最早的时候它也是以配置文件的方式在做一些配置方面的编程的模型,后来它也逐渐地跟像 zookeeper 这些做相应的集成,也就是说开始支持配置中心的这种模式。
业界也是近年开始逐渐进行配置中心的实践,可能没有我们开始地那么早,比如像 Spring Cloud Config,但是我目前还没有看到大规模采用它到生产上的一些分享,所以不知道在我上面提到的一些比如容灾,比如 SLA 以及关于配置的一些关键的特性的表现,它只是把以前应用自己管理配置搬到了 git 集中化管理,可能你可以通过它提供的 Spring Cloud Bus 做一些配置的推送,配置的存储这一块的选型很多都是 ok 的,也五花八门,有 etcd,redis,s3,git 这些都有。