http://192.168.2.51:4041
http://hadoop1:8088/proxy/application_1512362707596_0006/executors/

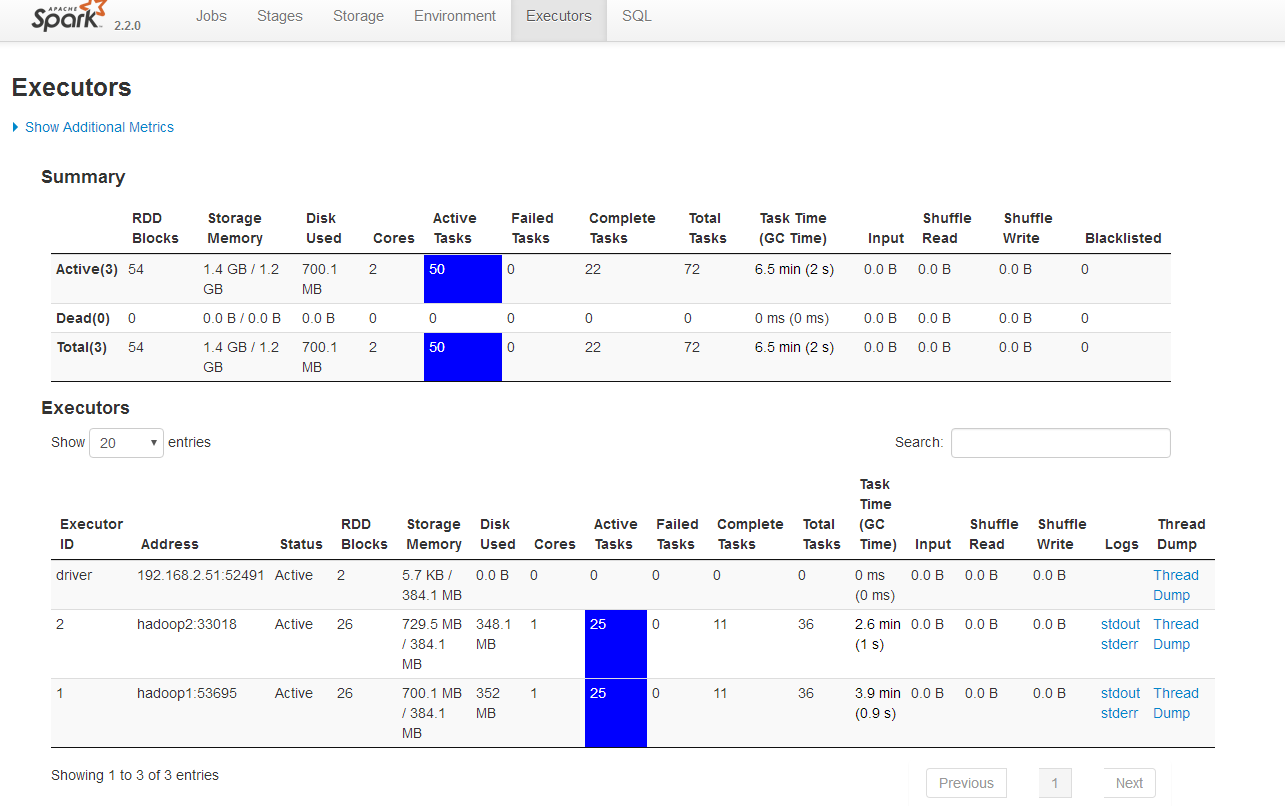
Executors
Summary
| RDD Blocks | Storage Memory | Disk Used | Cores | Active Tasks | Failed Tasks | Complete Tasks | Total Tasks | Task Time (GC Time) | Input | Shuffle Read | Shuffle Write | Blacklisted | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Active(3) | 54 | 1.4 GB / 1.2 GB | 700.1 MB | 2 | 50 | 0 | 22 | 72 | 6.5 min (2 s) | 0.0 B | 0.0 B | 0.0 B | 0 |
| Dead(0) | 0 | 0.0 B / 0.0 B | 0.0 B | 0 | 0 | 0 | 0 | 0 | 0 ms (0 ms) | 0.0 B | 0.0 B | 0.0 B | 0 |
| Total(3) | 54 | 1.4 GB / 1.2 GB | 700.1 MB | 2 | 50 | 0 | 22 | 72 | 6.5 min (2 s) | 0.0 B | 0.0 B | 0.0 B | 0 |
Executors
| Executor ID | Address | Status | RDD Blocks | Storage Memory | Disk Used | Cores | Active Tasks | Failed Tasks | Complete Tasks | Total Tasks | Task Time (GC Time) | Input | Shuffle Read | Shuffle Write | Logs | Thread Dump |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| driver | 192.168.2.51:52491 | Active | 2 | 5.7 KB / 384.1 MB | 0.0 B | 0 | 0 | 0 | 0 | 0 | 0 ms (0 ms) | 0.0 B | 0.0 B | 0.0 B | Thread Dump | |
| 2 | hadoop2:33018 | Active | 26 | 729.5 MB / 384.1 MB | 348.1 MB | 1 | 25 | 0 | 11 | 36 | 2.6 min (1 s) | 0.0 B | 0.0 B | 0.0 B | Thread Dump | |
| 1 | hadoop1:53695 | Active | 26 | 700.1 MB / 384.1 MB | 352 MB | 1 | 25 | 0 | 11 | 36 | 3.9 min (0.9 s) | 0.0 B | 0.0 B | 0.0 B | Thread Dump |
from pyspark.sql import SparkSession
my_spark = SparkSession
.builder
.appName("myAppYarn-10g")
.master('yarn')
.config("spark.mongodb.input.uri", "mongodb://pyspark_admin:admin123@192.168.2.50/recommendation.article")
.config("spark.mongodb.output.uri", "mongodb://pyspark_admin:admin123@192.168.2.50/recommendation.article")
.getOrCreate()
db_rows = my_spark.read.format("com.mongodb.spark.sql.DefaultSource").load().collect()
Summary
| RDD Blocks | Storage Memory | Disk Used | Cores | Active Tasks | Failed Tasks | Complete Tasks | Total Tasks | Task Time (GC Time) | Input | Shuffle Read | Shuffle Write | Blacklisted | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Active(3) | 31 | 748.4 MB / 1.2 GB | 75.7 MB | 2 | 27 | 0 | 0 | 27 | 0 ms (0 ms) | 0.0 B | 0.0 B | 0.0 B | 0 |
| Dead(2) | 56 | 1.5 GB / 768.2 MB | 790.3 MB | 2 | 0 | 0 | 77 | 77 | 2.7 h (2 s) | 0.0 B | 0.0 B | 0.0 B | 0 |
| Total(5) | 87 | 2.3 GB / 1.9 GB | 865.9 MB | 4 | 27 | 0 | 77 | 104 | 2.7 h (2 s) | 0.0 B | 0.0 B | 0.0 B | 0 |
Executors
| Executor ID | Address | Status | RDD Blocks | Storage Memory | Disk Used | Cores | Active Tasks | Failed Tasks | Complete Tasks | Total Tasks | Task Time (GC Time) | Input | Shuffle Read | Shuffle Write | Logs | Thread Dump |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| driver | 192.168.2.51:52491 | Active | 2 | 5.7 KB / 384.1 MB | 0.0 B | 0 | 0 | 0 | 0 | 0 | 0 ms (0 ms) | 0.0 B | 0.0 B | 0.0 B | Thread Dump | |
| 4 | hadoop2:34394 | Active | 12 | 315.9 MB / 384.1 MB | 0.0 B | 1 | 11 | 0 | 0 | 11 | 0 ms (0 ms) | 0.0 B | 0.0 B | 0.0 B | Thread Dump | |
| 3 | hadoop1:39620 | Active | 17 | 432.5 MB / 384.1 MB | 75.7 MB | 1 | 16 | 0 | 0 | 16 | 0 ms (0 ms) | 0.0 B | 0.0 B | 0.0 B | Thread Dump | |
| 2 | hadoop2:33018 | Dead | 27 | 758.7 MB / 384.1 MB | 390.4 MB | 1 | 0 | 0 | 38 | 38 | 1.3 h (1 s) | 0.0 B | 0.0 B | 0.0 B | Thread Dump | |
| 1 | hadoop1:53695 | Dead | 29 | 775.9 MB / 384.1 MB | 399.9 MB | 1 | 0 | 0 | 39 | 39 | 1.4 h (0.9 s) | 0.0 B | 0.0 B | 0.0 B | Thread Dump |
Showing 1 to 5 of 5 entries
Logs for container_1512362707596_0006_02_000002 http://hadoop1:8042/node/containerlogs/container_1512362707596_0006_02_000002/root/stderr?start=-4096
Logs for container_1512362707596_0006_02_000002 |
|
|
Showing 4096 bytes. Click here for full log Manager: Dropping block taskresult_48 from memory
17/12/04 13:14:32 INFO storage.BlockManager: Writing block taskresult_48 to disk
17/12/04 13:14:32 INFO memory.MemoryStore: After dropping 1 blocks, free memory is 38.5 MB
17/12/04 13:14:32 INFO memory.MemoryStore: Block taskresult_73 stored as bytes in memory (estimated size 32.5 MB, free 6.1 MB)
17/12/04 13:14:32 INFO executor.Executor: Finished task 72.0 in stage 1.0 (TID 73). 34033291 bytes result sent via BlockManager)
17/12/04 13:14:32 INFO executor.CoarseGrainedExecutorBackend: Got assigned task 74
17/12/04 13:14:32 INFO executor.Executor: Running task 73.0 in stage 1.0 (TID 74)
17/12/04 13:14:38 INFO memory.MemoryStore: 1 blocks selected for dropping (16.0 MB bytes)
17/12/04 13:14:38 INFO storage.BlockManager: Dropping block taskresult_50 from memory
17/12/04 13:14:38 INFO storage.BlockManager: Writing block taskresult_50 to disk
17/12/04 13:14:38 INFO memory.MemoryStore: After dropping 1 blocks, free memory is 22.1 MB
17/12/04 13:14:38 INFO memory.MemoryStore: Block taskresult_74 stored as bytes in memory (estimated size 14.4 MB, free 7.7 MB)
17/12/04 13:14:38 INFO executor.Executor: Finished task 73.0 in stage 1.0 (TID 74). 15083225 bytes result sent via BlockManager)
17/12/04 13:14:38 INFO executor.CoarseGrainedExecutorBackend: Got assigned task 75
17/12/04 13:14:38 INFO executor.Executor: Running task 74.0 in stage 1.0 (TID 75)
17/12/04 13:14:46 INFO memory.MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 5.2 KB, free 7.7 MB)
17/12/04 13:14:46 INFO memory.MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 433.0 B, free 7.7 MB)
17/12/04 13:14:48 ERROR executor.CoarseGrainedExecutorBackend: RECEIVED SIGNAL TERM
17/12/04 13:14:48 ERROR executor.Executor: Exception in task 74.0 in stage 1.0 (TID 75)
java.lang.OutOfMemoryError: Java heap space
at java.util.Arrays.copyOf(Arrays.java:3236)
at java.io.ByteArrayOutputStream.grow(ByteArrayOutputStream.java:118)
at java.io.ByteArrayOutputStream.ensureCapacity(ByteArrayOutputStream.java:93)
at java.io.ByteArrayOutputStream.write(ByteArrayOutputStream.java:153)
at org.apache.spark.util.ByteBufferOutputStream.write(ByteBufferOutputStream.scala:41)
at java.io.ObjectOutputStream$BlockDataOutputStream.write(ObjectOutputStream.java:1853)
at java.io.ObjectOutputStream.write(ObjectOutputStream.java:709)
at org.apache.spark.util.Utils$.writeByteBuffer(Utils.scala:239)
at org.apache.spark.scheduler.DirectTaskResult$$anonfun$writeExternal$1.apply$mcV$sp(TaskResult.scala:50)
at org.apache.spark.scheduler.DirectTaskResult$$anonfun$writeExternal$1.apply(TaskResult.scala:48)
at org.apache.spark.scheduler.DirectTaskResult$$anonfun$writeExternal$1.apply(TaskResult.scala:48)
at org.apache.spark.util.Utils$.tryOrIOException(Utils.scala:1303)
at org.apache.spark.scheduler.DirectTaskResult.writeExternal(TaskResult.scala:48)
at java.io.ObjectOutputStream.writeExternalData(ObjectOutputStream.java:1459)
at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1430)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1178)
at java.io.ObjectOutputStream.writeObject(ObjectOutputStream.java:348)
at org.apache.spark.serializer.JavaSerializationStream.writeObject(JavaSerializer.scala:43)
at org.apache.spark.serializer.JavaSerializerInstance.serialize(JavaSerializer.scala:100)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:403)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
17/12/04 13:14:48 INFO connection.MongoClientCache: Closing MongoClient: [192.168.2.50:27017]
17/12/04 13:14:48 INFO driver.connection: Closed connection [connectionId{localValue:4, serverValue:42}] to 192.168.2.50:27017 because the pool has been closed.
|
|