requests-html模块
请求数据
from requests_html import HTMLSession
session = HTMLSession()
requests-html发出的请求是由session发出来的
发送Get请求
url = 'https://baidu.com'
res= session.get(url = url)
发送post请求
url = 'https://baidu.com'
res= session.post(url = url)
也可以使用request方法,指定GET,或者是POST参数来指定,这个使用方法就和使用requests中的session方法类封装的
url = 'http://ww.baidu.com'
res = session.request(method = 'GET',url = url)
print(res.html.html)
get方法和post还有request的方法和requests的模块中的方法一致,至于为什么,因为这两个模块是一个人写的
自定义HTML对象
from requests_html import HTML
doc = """<a href='https://httpbin.org'>"""
html = HTML(html=doc)
print(html.links)
{'https://httpbin.org'}
HTML对象属性
url = 'https://www.zhihu.com/signin?next=%2F'
res = session.get(url = url)
在ipython中检查res类型
In [15]: res
Out[15]: <Response [200]>
In [16]: type(res)
Out[16]: requests_html.HTMLResponse
In [17]: res.html
Out[17]: <HTML url='https://www.zhihu.com/signin?next=%2F'>
In [18]: type(res.html)
Out[18]: requests_html.HTML
可以看到requests_html.HTML 和requests_html.HTMLResponse 模块自己实现的类
In [19]: dir(res.html)
Out[20]:
['absolute_links', 'add_next_symbol', 'arender', 'base_url', 'default_encoding', 'element', 'encoding', 'find', 'full_text', 'html', 'links', 'lxml', 'next', 'next_symbol', 'page', 'pq', 'raw_html', 'render', 'search', 'search_all', 'session', 'skip_anchors', 'text', 'url', 'xpath]
除去掉模块内部封装的属性和方法之外有这么多的方法和属性,下面我们一步一步类进行介绍。
html对象属性
absolute_links
输入页面中的绝对路径,如果页内连接是相对路径也会被自动转换为绝对路径
url = 'https://www.zhihu.com/signin?next=%2F'
res = session.get(url = url)
这里我们请求知乎首页,可以底部检查网址,
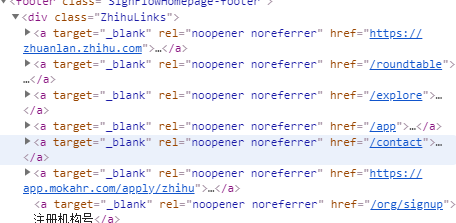
In:res.html.absolute_links
Out:
{
'https://www.zhihu.com/app',
'https://www.zhihu.com/contact',
'https://www.zhihu.com/explore',
'https://www.zhihu.com/jubao',
'https://www.zhihu.com/org/signup',
'https://www.zhihu.com/question/waiting',
}
相对路径被转换为绝对路径
links
原样连接,页面中是绝对路径的输出就是绝对路径,是相对路径输出就是相对路径
In : res.html.links
Out:
{
'/app',
'/contact',
'/explore',
'/jubao',
'https://www.zhihu.com/org/signup',
'https://www.zhihu.com/term/privacy',
'https://www.zhihu.com/terms',
'}
base_url
基础连接
html
返回响应页面的html代码
raw_html
返回页面的二进制流
text
输入响应中所有的文字,结果如下,
In [21]: res.html.text
Out[21]: '知乎 - 有问题,上知乎
.u-safeAreaInset-top { height: constant(safe-area-inset-top) !important; height: env(safe-
area-inset-top) !important; } .u-safeAreaInset-bottom { height: constant(safe-area-inset-bottom) !important; height: env(safe-area-inset-bottom) !important; }
if (window.requestAnimationFrame) { window.requestAnimationFrame(function() { window.FIRST_ANIMATION_FRAME = Date.now(); }); }
首页
发现
等你来答
登录加入知乎
有问题,上知乎
免密码登录
密码登录
获取短
信验证码
接收语音验证码
注册/登录
未注册手机验证后自动登录
注册即代表同意《知乎协议》《隐私保护指引》
注册机构号
社交
帐号登录
微信
QQ
QQ
微博
下载知乎 App
知乎专栏圆桌发现移动应用联系我们来知乎工作注册机构号
© 2019 知乎京 ICP 证 1107
45 号京公网安备 11010802010035 号出版物经营许可证
侵权举报网上有害信息举报专区儿童色情信息举报专区违法和不良信息举报:010-
82716601
encoding
字符编码
可以通过以下方法设置字符编码
res.html.encoding = 'gbk'
html对象方法
find
参数:
:param selector: css 选择器
:param clean: 是否去除页面中的<scpript>和<style>标签,默认False
:param containing:如果指定有值,只返回包含所给文本的Element对象,默认False
:param first: 是否返回第一个对象,默认False
:param _encoding: 字符编码
返回结果
[Element,Element……]
当First为True的时候,只返回第一个Element
xpath
:param selector: xpath 选择器
其他和find方法一致
search
res.html.search(xxx{}yyy)[0] // 只搜索一次
res.html.search(xxx{name}yyy{pwd}zzz)[name] // 只搜索一次
search_all
查找所有符合template对象,返回结果是result对象组成的list
Element对象
'absolute_links', 'attrs', 'base_url', 'default_encoding', 'element', 'encoding', 'find', 'full_text', 'html', 'lineno', 'links', 'lxml', 'pq', 'raw_html', 'search', 'search_all', 'session', 'skip_anchors', 'tag', 'text', 'url', 'xpath'
text
去掉
之后的文本
full_text
没有去掉
之后的文本值
attrs
返回以字典的形式Element对象的属性和属性名,