一、reponse解析
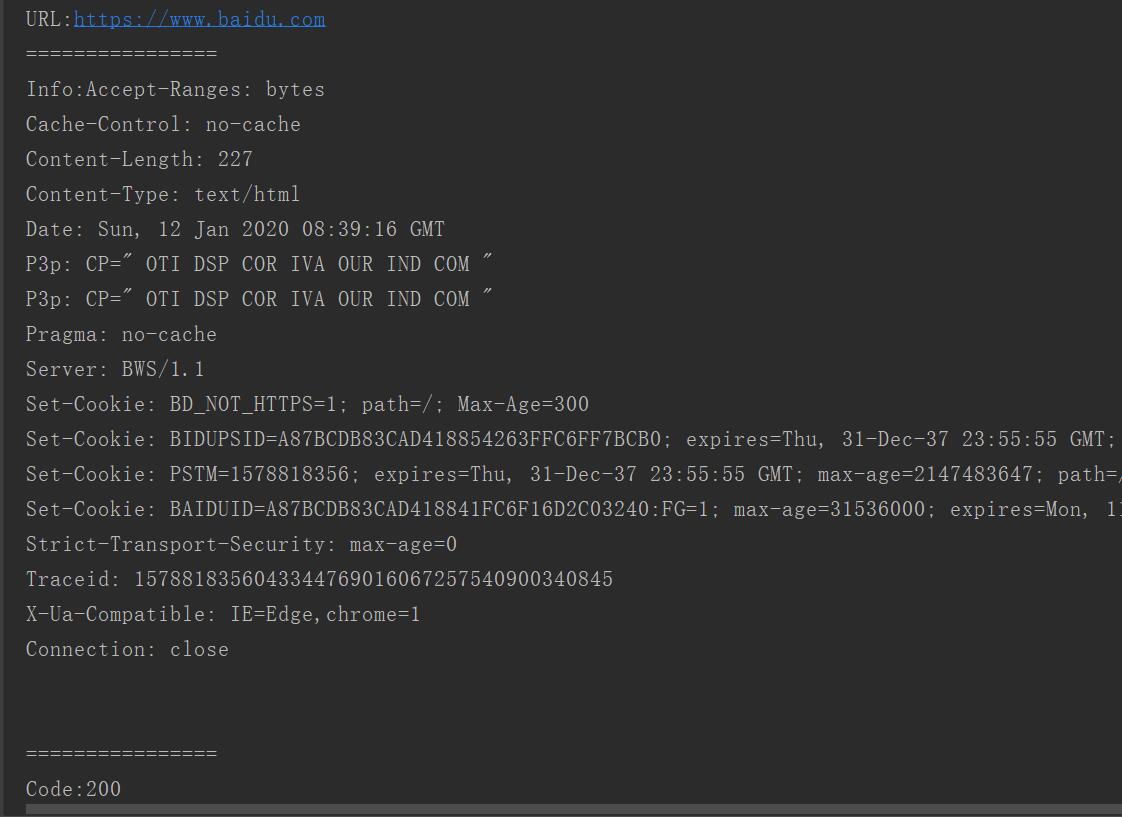
urlopen的返回对象
(1)geturl:返回网页地址
(2)info:请求反馈对象的meta信息
(3)getcode:返回的http code
from urllib import request import chardet """ 解析reponse """ if __name__ == "__main__": url = "https://www.baidu.com" rsp = request.urlopen(url) print("URL:{0}".format(rsp.geturl()))#网页地址 print("================") print("Info:{0}".format(rsp.info()))#网页头信息 print("================") print("Code:{0}".format(rsp.getcode()))#请求后返回的状态码
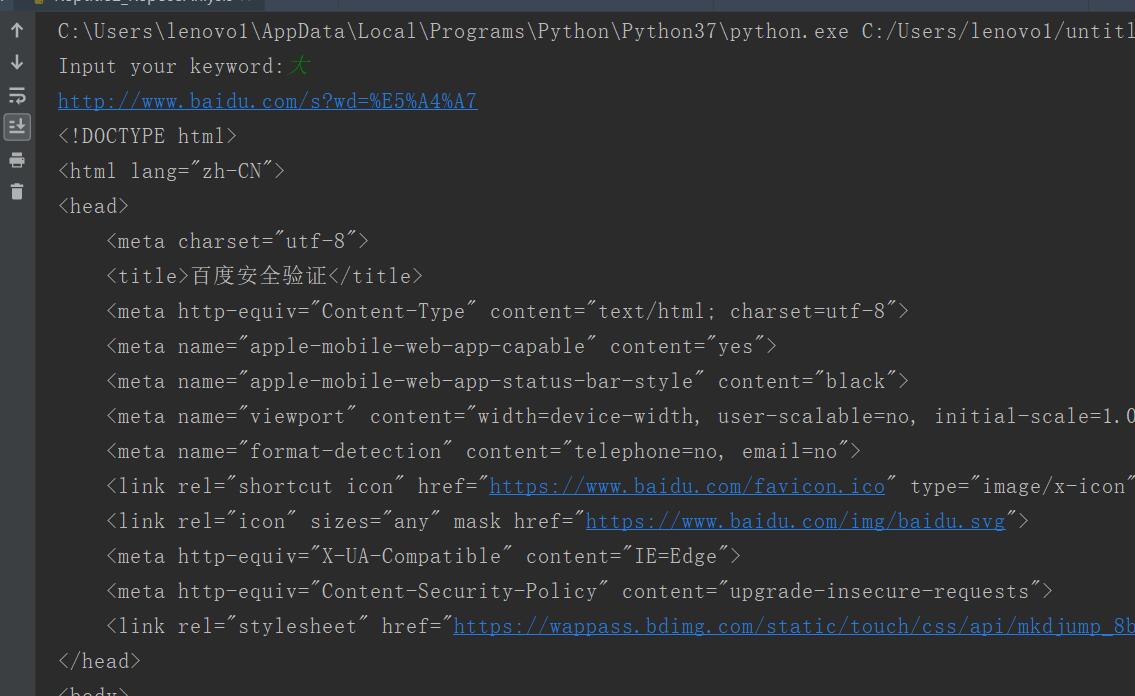
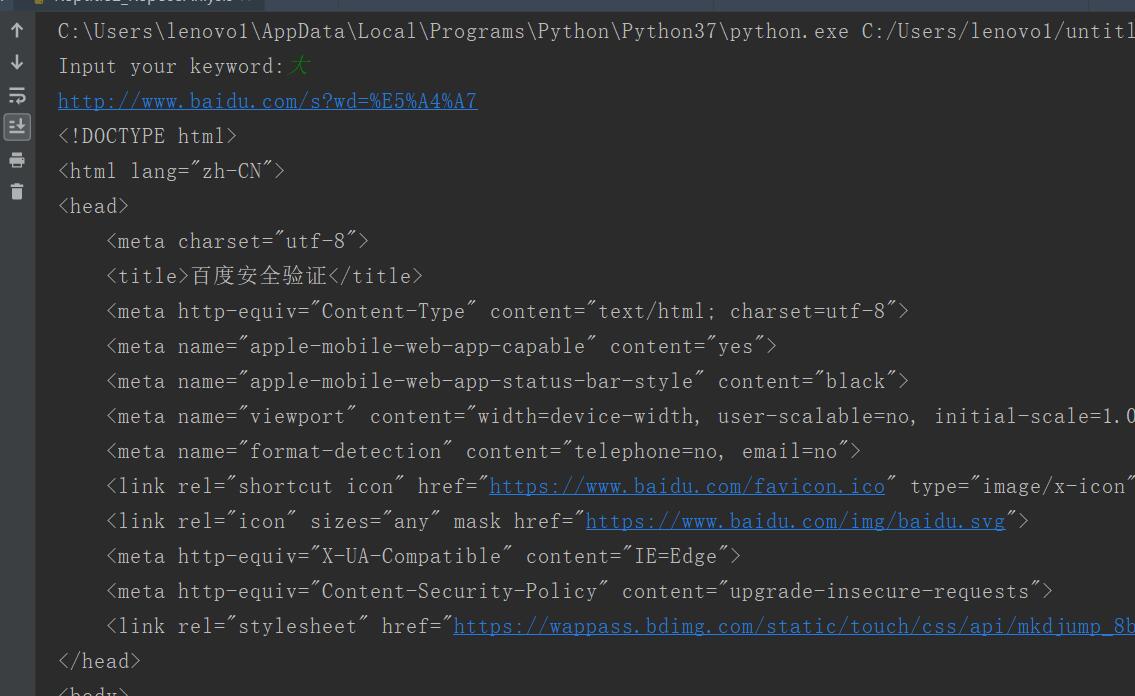
二、parse
1.request.date的使用
访问网络的两种方式
(1)get(2)post
2.url.parse用来解析url
from urllib import request,parse import chardet """ 解析reponse """ if __name__ == "__main__": url = "http://www.baidu.com/s?" wd = input("Input your keyword:") #要想使用data,需要使用字典结构 qs = { "wd":wd } #转换url编码 qs = parse.urlencode(qs)#对关键字进行编码 fullurl = url + qs#百度搜索传入的地址是基础地址加上关键字的编码形式 print(fullurl) rsp = request.urlopen(fullurl) html = rsp.read() html = html.decode()#解码 #使用get取值保证不会出错 print(html)
三、源码
Reptile2_ReposeAnlysis.py
https://github.com/ruigege66/PythonReptile/blob/master/Reptile2_ReposeAnlysis.py
2.CSDN:https://blog.csdn.net/weixin_44630050(心悦君兮君不知-睿)
3.博客园:https://www.cnblogs.com/ruigege0000/
4.欢迎关注微信公众号:傅里叶变换,个人公众号,仅用于学习交流,后台回复”礼包“,获取大数据学习资料