1、磁盘基础知识
1.1 物理结构
硬盘的物理结构一般由磁头与碟片、电动机、主控芯片与排线等部件组成;当主电动机带动碟片旋转时,副电动机带动一组(磁头)到相对应的碟片上并确定读取正面还是反面的碟面,磁头悬浮在碟面上画出一个与碟片同心的圆形轨道(磁轨或称柱面),这时由磁头的磁感线圈感应碟面上的磁性与使用硬盘厂商指定的读取时间或数据间隔定位扇区,从而得到该扇区的数据内容。所有的盘片都固定在一个旋转轴上,这个轴即盘片主轴。而所有盘片之间是绝对平行的,在每个盘片的存储面上都有一个磁头,磁头与盘片之间的距离比头发 丝的直径还小。所有的磁头连在一个磁头控制器上,由磁头控制器负责各个磁头的运动。磁头可沿盘片的半径方向动作,而盘片以每分钟数千转到上万转的速度在高 速旋转,这样磁头就能对盘片上的指定位置进行数据的读写操作。
- 磁道(Track)
当磁盘旋转时,磁头若保持在一个位置上,则每个磁头都会在磁盘表面划出一个圆形轨迹,这些圆形轨迹就叫做磁道(Track)。信息以脉冲串的形式记录在这些轨迹中,这些同心圆不是连续记录数据,而是被划分成一段段的圆弧(扇区),这些圆弧 的角速度一样。
- 柱面 (Cylinder)
在有多个盘片构成的盘组中,由不同盘片的面,但处于同一半径圆的多个磁道组成的一个圆柱面(Cylinder)。所有盘面上的同一磁道构成一个圆柱,通常称做柱面(Cylinder),每个圆柱上的磁头由上而下从“0”开始编号。数据的读/写按柱面进行,即磁 头读/写数据时首先在同一柱面内从“0”磁头开始进行操作,依次向下在同一柱面的不同盘面即磁头上进行操作,只在同一柱面所有的磁头全部读/写完毕后磁头 才转移到下一柱面,因为选取磁头只需通过电子切换即可,而选取柱面则必须通过机械切换。电子切换相当快,比在机械上磁头向邻近磁道移动快得多,所以,数据 的读/写按柱面进行,而不按盘面进行。也就是说,一个磁道写满数据后,就在同一柱面的下一个盘面来写,一个柱面写满后,才移到下一个扇区开始写数据。读数 据也按照这种方式进行,这样就提高了硬盘的读/写效率。
- 扇区(Sector)
磁盘上的每个磁道被等分为若干个弧段,这些弧段便是硬盘的扇区(Sector)。硬盘的第一个扇区,叫做引导扇区。操作系统以扇区(Sector)形式将信息存储在硬盘上,每个扇区包括512个字节的数据和一些其他信息。
- 磁头(Head)
在硬盘系 统中,硬盘的每一个盘片都有两个盘面(Side),即上、下盘面,一般每个盘面都会利 用,都可以存储数据。盘面号又叫磁头号,因为每一个有效盘面都有一个对应的读写磁头。

.png)
在 linux 中可以使用 fdisk -l 查看一个磁盘的物理结构:

.png)
该磁盘有255个heads,也就是说共有255个盘面。3263个柱面(cylinders),也就是说每个盘面上都有3263个磁道, 63 sectors/track说的是每个磁道上共有63个扇区。命令结果也给出了Sector size的值是512bytes。那我们动笔算一下该磁盘的大小吧。
255盘面 * 3263柱面 * 63扇区 * 每个扇区512bytes = 26839088640byte。
结果是26.8G,和磁盘的总大小相符。
1.2 磁盘的读写原理
系统将文件存储到磁盘上时,按柱面、磁头、扇区的方式进行,即最先是第1磁道的第一磁头下(也就是第1盘面的第一磁道)的所有扇区,然后,是同一柱面的下一磁头,……,一个柱面存储满后就推进到下一个柱面,直到把文件内容全部写入磁盘。
系统也以相同的顺序读出数据。读出数据时通过告诉磁盘控制器要读出扇区所在的柱面号、磁头号和扇区号(物理地址的三个组成部分)进行。磁盘控制器则直接使磁头部件步进到相应的柱面,选通相应的磁头,等待要求的扇区移动到磁头下。在扇区到来时,磁盘控制器读出每个扇区的头标,把这些头标中的地址信息与 期待检出的磁头和柱面号做比较(即寻道),然后,寻找要求的扇区号。待磁盘控制器找到该扇区头标时,根据其任务是写扇区还是读扇区,来决定是转换写电路, 还是读出数据和尾部记录。找到扇区后,磁盘控制器必须在继续寻找下一个扇区之前对该扇区的信息进行后处理。如果是读数据,控制器计算此数据的ECC码,然 后,把ECC码与已记录的ECC码相比较。如果是写数据,控制器计算出此数据的ECC码,与数据一起存储。在控制器对此扇区中的数据进行必要处理期间,磁 盘继续旋转。其实我们的文件大多数的时候都是破碎的,在文件没有破碎的时候,摇臂只需要寻找1次磁道并由磁头进行读取,只需要1次就可以成功读取;但是如果文件破碎成11处,那么摇臂要来回寻找11次磁道磁头进行11次读取才能完整的读取这个文件,读取时间相对没有破碎的时候就变得冗长。
因此,磁盘IO时的过程包括:
- 第一步,首先是磁头径向移动来寻找数据所在的磁道。这部分时间叫寻道时间。
- 第二步,找到目标磁道后通过盘面旋转,将目标扇区移动到磁头的正下方。
- 第三步,向目标扇区读取或者写入数据。到此为止,一次磁盘IO完成,故:
所以,单次磁盘IO时间 = 寻道时间 + 旋转延迟 + 存取时间。
- 对于旋转延时,现在主流服务器上经常使用的是1W转/分钟的磁盘,每旋转一周所需的时间为60*1000/10000=6ms,故其旋转延迟为(0-6ms)。
- 对于存取时间,一般耗时较短,为零点几ms。
- 对于寻道时间,现代磁盘大概在3-15ms,其中寻道时间大小主要受磁头当前所在位置和目标磁道所在位置相对距离的影响。
候选的磁盘分区方案:
- 方案一: 255个盘面,C盘是0-100盘面, D盘是101-200个盘面,……
- 方案二:3263个柱面,C盘0-1000个柱面,D盘1001-20001个柱面,……
其实采用哪一种,最主要看的是那种方式性能更快。因为同一分区下的数据经常会一起读取,假如采用第一种,那么这样磁头就需要在3000多个track间不停地跳来跳去,这样磁盘的寻道时间就会翻倍,磁盘性能就会下降。而对于方案二,假如对于磁盘C,只需要在磁头在1-1000个磁道间移动就可以了,大大降低了寻道时间。(实际上分区并不是从0开始的,磁盘的第一个磁道对应的柱面会被用来安装引导加载程序以及磁盘分区表)。所以,方案二的分区方式可以降低磁盘IO时间中的寻道时间部分,所以所有的操作系统采用的都是方案二,没有用方案一的。
2. Linux 下磁盘命名和分区
在为主机添加硬盘前,首先要了解Linux系统下对硬盘和分区的命名方法。
2.1 磁盘命名
在Linux下对 SCSI 和 SATA 设备是以 sd 命名的,第一个 scsi 设备是 sda,第二个是 sdb,依此类推。一般主板上有两个SCSI接口,因此一共可以安装四个SCSI设备。主 SCSI 上的两个设备分别对应 sda 和 sdb,第二个 SCSI 口上的两个设备对应 sdc 和 sdd。一般硬盘安装在主 SCSI 的主接口上,所以是 sda 或者 sdb,而光驱一般安装在第二个SCSI的主接口上,所以是 sdc。(IDE接口设备是用 hd 命名的,第一个设备是hda,第二个是hdb,依此类推。)
| IDE 磁盘 | 描述 | 配置 |
|---|---|---|
| /dev/hda | 1st (Primary) IDE controller | Master |
| /dev/hdb | 1st (Primary) IDE controller | Slave |
| /dev/hdc | 2nd (Secondary) IDE controller | Master |
| /dev/hdd | 2nd (Secondary) IDE controller | Slave |
2.2 分区命名
所谓的磁盘分区指的是告诉操作系统『我这颗磁盘在此分割槽可以存取的区域是由 A 磁柱到 B 磁柱之间的区块』, 如此一来操作系统就能够知道他可以在所指定的区块内进行文件数据的读/写/搜寻等动作了。 也就是说,磁盘分区意即指定分割槽的启始与结束磁柱就是了。
分区是用设备名称加数字命名的。例如 hda1 代表hda这个硬盘设备上的第一个分区。 每个硬盘可以最多有四个主分区,作用是 1-4 命名硬盘的主分区。多个主分区中只能有一个active 主分区作为启动分区。逻辑分区是从5开始的,每多一个分区,每个磁盘上最多可以有 24个扩展分区。
2.3 分区步骤
1. 运行 fdisk 来分区:

.png)
其中第一个框和第二个框,是已经分好区的磁盘,第三个硬盘没有分区。
[root]# fdisk /dev/sdb
Command (m for help): m (Enter the letter "m" to get list of commands)
Command action
a toggle a bootable flag
b edit bsd disklabel
c toggle the dos compatibility flag
d delete a partition
l list known partition types
m print this menu
n add a new partition
o create a new empty DOS partition table
p print the partition table
q quit without saving changes
s create a new empty Sun disklabel
t change a partition's system id
u change display/entry units
v verify the partition table
w write table to disk and exit
x extra functionality (experts only)
Command (m for help): n
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 1
First cylinder (1-9729, default 1):
Using default value 1
Last cylinder, +cylinders or +size{K,M,G} (1-9729, default 9729):
Using default value 9729
Command (m for help): w (Write and save partition table)
[root]# mkfs.ext4 -L disk2 /dev/sdb
|
分多个区有以下几个目的:
- 在不损失数据的情况下重装系统,比如独立设置 /home 挂载点,重装系统的时候直接标记回 /home,数据不会有任何损失。
- 针对不同的挂载点的特性分配合适的文件系统以合理发挥性能,比如对 /var 使用reiserfs,对 /home 使用xfs,对 / 使用ext4。
- 针对不同的挂载点开启不同的挂载选项,如是否需要即时同步,是否开启日志,是否启用压缩。
- 大硬盘搜索范围大,效率低
- 磁盘配额只能对分区做设定
- /home、/var、/usr/local 经常是单独分区,因为经常会操作,容易产生碎片
2. 格式化分区:mkfs -t ext3 /dev/sda1
每块硬盘都分为若干个分区,每个分区都有自己的文件系统。Windows为这些文件系统各自指定了一个字母。不过 GNU/Linux 使用唯一的树形结构来管理文件,而每个文件系统都挂载于树形结构的某个位置。
正如 Windows 需要有 C: 驱动器一样,GNU/Linux 必须能够将根文件系统挂载于文件树的根(/)上。当根挂载完成之后,您就可以将其它文件系统挂载于树形结构各种挂载点上。根结构下的任何目录都可以作为挂载点,而您也可以将同一文件系统同时挂载于不同的挂载点上。挂载点实际上就是linux中的磁盘文件系统的入口目录:
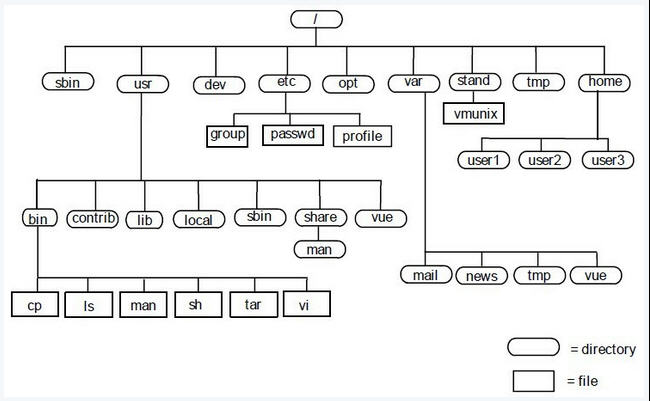
关于文件系统的三个易混淆的概念:
- 创建:以某种方式格式化磁盘的过程就是在其之上建立一个文件系统的过程。创建文件系统时,会在磁盘的特定位置写入关于该文件系统的控制信息。
- 注册:向内核报到,声明自己能被内核支持。一般在编译内核的时侯注册;也可以加载模块的方式手动注册。注册过程实 际上是将表示各实际文件系统的数据结构struct file_system_type 实例化。
- 安装:也就是我们熟悉的mount操作,将文件系统加入到 Linux 的根文件系统的目录树结构上;这样文件系统才能被访问。
linux 下一切皆文件!换言之就是linux操作系统将系统中的一切都作为文件来管理。在windows中我们常见的硬件设备(打印机、网卡、声卡...)、磁盘分区等,在linux中统统都被视作文件,对设备、分区的访问就是读写对应的文件。
格式化命令:
mkfs.ext3 /dev/sdb1 //格式化分区成 ext3
mkfs.ext2 /dev/sdb1 //格式化分区成 ext2
3. 挂载 mount /dev/sda1 /test
df 命令用于查看已挂载磁盘的总容量、使用容量、剩余容量等,可以不加任何参数,默认是按k为单位显示的。
du 命令用来查看某个目录所占空间大小。
.png)

4. 开机直接挂载
编辑 /etc/fstab 文件,添加:/dev/sda1 /test ext3 defaults 1 1,重启则发选已经挂载上去。
5. 总结
- 挂载点必须是一个目录。
- 一个分区挂载在一个已存在的目录上,这个目录可以不为空,但挂载后这个目录下以前的内容将不可用。对于其他操作系统建立的文件系统的挂载也是这样,卸载后,目录以前的文件都还在,不会有任何丢失。
- 目录只占磁盘里的一个inode,存放文件属性等信息。
- 任何一个分区都必须挂载到某个目录上。
- 目录是逻辑上的区分。分区是物理上的区分。
- 磁盘Linux分区都必须挂载到目录树中的某个具体的目录上才能进行读写操作。
- 根目录是所有Linux的文件和目录所在的地方,需要挂载上一个磁盘分区。
- 一个分区可以挂在多个目录,但反过来一个目录只能是一个分区的挂载点。
3. Linux 文件系统
文件系统是对一个存储设备上的数据和元数据进行组织的机制。它的最终目的是把大量数据有组织的放入持久性(persistant)的存储设备中,比如硬盘和磁盘。文件系统(file system)是就是文件在逻辑上组织形式,它以一种更加清晰的方式来存放各个文件。数据被存入到某个分区中。一个典型的Linux分区(partition)包含有下面各个部分:

.png)
文件是文件系统对数据的分割单元。文件系统用目录来组织文件,赋予文件以上下分级的结构。在硬盘上实现这一分级结构的关键,是使用 inode 来虚拟普通文件和目录文件对象。在Linux系统中,目录也是一种文件。所以/home/sammy 是指向目录文件 sammy 的绝对路径。
磁盘与文件系统:
.png)
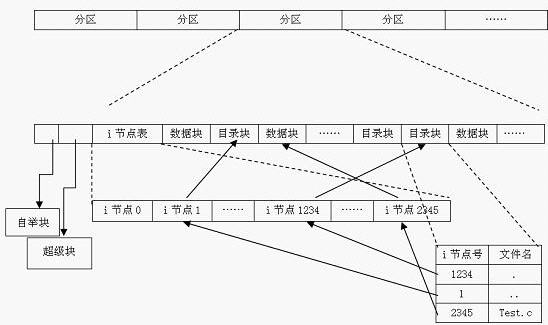
3.1 inode
inodes 是实现文件存储的关键。在 Linux 中,文件系统中管理的每个对象(文件或目录)表示为一个 inode。inode 包含管理文件系统中的对象所需的所有元数据(包括可以在对象上执行的操作)。在 Linux 系统中,一个文件可以分成几个数据块存储在分区内。为了搜集各数据块,我们需要该文件对应的inode。每个文件对应一个 inode。这个 inode 中包含多个指针,指向属于该文件各个数据块。当操作系统需要读取文件时,只需要找到对应 inode,收集分散的数据块,就可以收获我们的文件了。

.png)
读取文件:
在Linux中,我们通过解析路径,根据沿途的目录文件来找到某个文件。目录中的条目除了所包含的文件名,还有对应的inode编号。当我们输入$cat /var/test.txt时,Linux 将在根目录文件中找到 var 这个目录文件的inode编号,然后根据 inode 合成 var 的数据。随后,根据 var 中的记录,找到 text.txt 的 inode 编号,沿着 inode 中的指针,收集数据块,合成 text.txt 的数据。整个过程中,会参考三个inode:
- 根目录文件的 inode:2,用于找到 var 的 inode id
- var 目录文件的 inode:10747905,用于找到 test.txt 的 inode id
- text.txt 文件的 inode: 10749034,用于找到 data blocks

.png)
因此,当我们读取一个文件时,实际上是在目录中找到了这个文件的inode编号,然后根据inode的指针,把数据块组合起来,放入内存供进一步的处理。当我们创建一个文件时,是分配一个空白 inode 给该文件,将其 inode 编号记入该文件所属的目录,然后选取空白的数据块,让 inode 的指针指向这些数据块,并放入内存中的数据。
3.2 循环设备
- 用一个循环设备节点连接文件。
- 在目录上挂载该循环设备
具体步骤:
dd if=/dev/zero of=file.img bs=1k count=10000 //创建一个初始化文件 losetup /dev/loop0 file.img //创建一个循环设备 mke2fs -c /dev/loop0 10000 //创建文件系统 mkdir /mnt/point1 //创建挂载点 mount -t ext2 /dev/loop0 /mnt/point1 //挂载
3.3 文件系统的结构

.png) 用户空间包含一些应用程序(例如,文件系统的使用者)和 GNU C 库(glibc),它们为文件系统调用(打开、读取、写和关闭)提供用户接口。系统调用接口的作用就像是交换器,它将系统调用从用户空间发送到内核空间中的适当端点。
用户空间包含一些应用程序(例如,文件系统的使用者)和 GNU C 库(glibc),它们为文件系统调用(打开、读取、写和关闭)提供用户接口。系统调用接口的作用就像是交换器,它将系统调用从用户空间发送到内核空间中的适当端点。VFS 是底层文件系统的主要接口,它是 Linux 内核中的一个软件抽象层。。这个组件导出一组接口,然后将它们抽象到各个文件系统,各个文件系统的行为可能差异很大。有两个针对文件系统对象的缓存(inode 和 dentry)。它们缓存最近使用过的文件系统对象。因为有 VFS 存在,Linux 允许众多不同的文件系统共存,并支持跨文件系统的文件操作。它通过一些数据结构及其方法向实际的文件系统如 ext2,vfat 提供接口机制。
每个文件系统实现(比如 ext2、JFS 等等)导出一组通用接口,供 VFS 使用。缓冲区缓存会缓存文件系统和相关块设备之间的请求。例如,对底层设备驱动程序的读写请求会通过缓冲区缓存来传递。这就允许在其中缓存请求,减少访问物理设备的次数,加快访问速度。可以使用
sync 命令将缓冲区缓存中的请求发送到存储媒体(迫使所有未写的数据发送到设备驱动程序,进而发送到存储设备)。 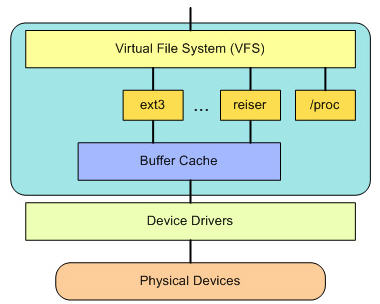
3.4 VFS (虚拟文件系统)
Linux 中允许众多不同的文件系统共存,如 ext2, ext3, vfat 等。通过使用同一套文件 I/O 系统调用即可对 Linux 中的任意文件进行操作而无需考虑其所在的具体文件系统格式;更进一步,对文件的 操作可以跨文件系统而执行。如下图所示,我们可以使用 cp 命令从 vfat 文件系统格式的硬盘拷贝数据到 ext3 文件系统格式的硬盘;而这样的操作涉及到两个不同的文件系统。

.png)
过程:VFS调用 vfat 的读文件方法将 a.txt 的数据读入内存;再将 a.txt 在内存中的数据映射到b.txt对应的内存空间后,VFS调用ext3的写文件方法将b.txt写入磁盘;从而实现了最终的跨文件系统的复制操作。
“一切皆是文件”是 Unix/Linux 的基本哲学之一。不仅普通的文件,目录、字符设备、块设备、 套接字等在 Unix/Linux 中都是以文件被对待;它们虽然类型不同,但是对其提供的却是同一套操作界面。操作文件时需先打开;打开文件时,VFS 会知道该文件对应的文件系统格式;当VFS把控制权传给实际的文件系统时,实际的文件系统再做出具体区分,对不同的文件类型执行不同的操作。这也就是“一切皆是文件”的根本所在。

.png)
从物理介质读文件的具体过程:

.png)
当在用户应用程序调用文件 I/O read()操作时,系统调用 sys_read() 被激发,sys_read() 找到文件所在的具体文件系统,把控制权传给该文件系统,最后由具体文件系统与物理介质交互,从介质中读出数据。
3.5 Linux 文件系统类型
3.5.1 ReiserFS
ReiserFS 是一种文件系统格式。Linux内核从2.4.1版本开始支持ReiserFS。ReiserFS原先是Novell公司的SuSE Linux Enterprise采用的默认文件系统,直到2006年10月12日其宣称将在未来的版本改采 ext3 为默认。和同样在 Linux Kernel 2.4 版本下的 ext2 及 ext3 相比较,处理 4KB 以下的小文件时(tail packing enable),ReiserFS 的速度快了 10 到 15 倍[3]。但是,有些目录的操作在 ReiserFS 上面并不同步,(包括像 unlink(2)),可能会导致一些重度依赖文件锁(file-based lock)机制的应用程序上面数据的毁损。ReiserFS 在一个单一复合B+树中存储文件的亚数据信息(stat item)、目录文件信息(directory items)、索引节点中的块列表(indirect items),这些信息都有唯一的标识号作为B+树的索引值。
3.5.2 ext2 文件系统
ext2 文件系统(也称为第二扩展文件系统)旨在克服早期 Linux 版本中使用的 Minix 文件系统的缺点。多年来,该文件系统一直广泛应用于 Linux。但 ext2 中没有日志,现在基本上已被 ext3 和最新的 ext4 所取代。
3.5.3 ext3 文件系统
ext3 文件系统向标准 ext2 文件系统添加了日志功能,因此是一个非常稳定的文件系统的一个演化发展。它在大多数情况下提供合理的性能并且仍旧在改进。由于它在可靠的 ext2 文件系统上添加了日志功能,因此可以将现有 ext2 文件系统转换为 ext3 文件系统,并且在必要时还可以转换回来。
3.5.4 ext4 文件系统
ext4 是作为 ext3 的扩展来启动的,它通过增加存储限制和提高性能来满足更大文件系统的需求。为了保留 ext3 的稳定性,在2006 年 6 月,该扩展被拆分成一个新的文件系统,即 ext4。ext4 文件系统在 2008 年 12 月正式发布,包含在 2.6.28 内核中。
3.5.5 vfat 文件系统
vfat 文件系统(也称为 FAT32)没有日志功能,且缺乏完整的 Linux 文件系统实现所需的许多特性。它可用于在 Windows 和 Linux 系统之间交换数据,因为 Windows 和 Linux 都能读取它。不要将这个文件系统用于 Linux,除非要在 Windows 和 Linux 之间共享数据。
3.5.6 XFS 文件系统
XFS 文件系统拥有日志功能,包含一些健壮的特性,并针对可伸缩性进行了优化。XFS 通常是相当快的。在大文件操作方面,XFS 在所有测试中一直处于领先地位。XFS 的性能非常接近 ReiserFS,并在大多数测试指标上都超过了 ext3。
3.5.7 IBM JFS 文件系统
IBM 的 Journaled File System (JFS),目前用于 IBM 企业服务器,专为高吞吐量服务器环境而设计。它可用于 Linux,包含在几个发行版中。要创建 JFS 文件系统,使用 mkfs.jfs 命令。
3.6 选择文件系统
选择合适的下一代 Linux 文件系统一直很简单。那些只寻求原始性能的人通常倾向于使用 ReiserFS,而那些更关心数据完整性特性的人则首选 ext3/4。然而,随着 XFS 的 Linux 版的发布,事情突然变得令人困惑。尤其是,对于 ReiserFS 是否依然是下一代文件系统性能方面的佼佼者,人们开始感到疑惑。
- XFS 的性能非常接近 ReiserFS,并在大多数测试指标上都超过了 ext3。
- 目前,ReiserFS 和 ext3 删除文件要比 XFS 快得多。
3.7 创建文件系统
Linux 使用
mkfs 命令来创建文件系统,使用 mkswap 命令创建交换空间。mkfs 命令实际上是几个特定文件系统的命令的前端,比如面向 ext3 的 mkfs.ext3,面向 ext4 的 mkfs.ext4 以及面向 ReiserFS 的 mkfs.reiserfs。你的文件系统上安装的是什么文件系统支持?使用 ls /sbin/mk* 命令即可得到答案。参考文档: