20172305 2018-2019-1 蓝墨云班课实验--哈夫曼树的编码
实验要求
- 设有字符集:S={a,b,c,d,e,f,g,h,i,j,k,l,m,n.o.p.q,r,s,t,u,v,w,x,y,z}。
给定一个包含26个英文字母的文件,统计每个字符出现的概率,根据计算的概率构造一颗哈夫曼树。
并完成对英文文件的编码和解码。 - 要求:
- (1) 准备一个包含26个英文字母的英文文件(可以不包含标点符号等),统计各个字符的概率
- (2) 构造哈夫曼树
- (3) 对英文文件进行编码,输出一个编码后的文件
- (4) 对编码文件进行解码,输出一个解码后的文件
- (5) 撰写博客记录实验的设计和实现过程,并将源代码传到码云
- (6) 把实验结果截图上传到云班课
哈夫曼编码
- 哈夫曼编码(Huffman Coding),又称霍夫曼编码,是一种编码方式,哈夫曼编码是可变字长编码(VLC)的一种。Huffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码,一般就叫做Huffman编码(有时也称为霍夫曼编码)。
步骤:
- 对给定的n个权值{W1,W2,W3,...,Wi,...,Wn}构成n棵二叉树的初始集合F= {T1,T2,T3,...,Ti,...,Tn},其中每棵二叉树Ti中只有一个权值为Wi的根结点,它的左右子树均为空。(为方便在计算机上实现算 法,一般还要求以Ti的权值Wi的升序排列。)
- 在F中选取两棵根结点权值最小的树作为新构造的二叉树的左右子树,新二叉树的根结点的权值为其左右子树的根结点的权值之和。
- 从F中删除这两棵树,并把这棵新的二叉树同样以升序排列加入到集合F中。
- 重复上两步的操作,直到集合F中只有一棵二叉树为止,即为哈夫曼树
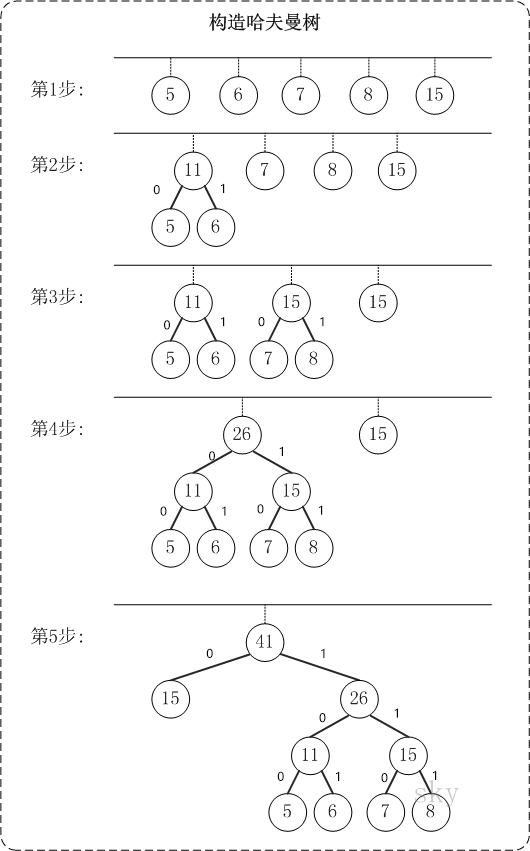
- 第1步:创建森林,森林包括5棵树,这5棵树的权值分别是5,6,7,8,15。
- 第2步:在森林中,选择根结点权值最小的两棵树,即“树5”和“树6”来进行合并,将它们作为一颗新树的左右子结点(谁左谁右无关紧要,这里,我们选择较小的作为左孩子),并且新树的权值是左右子结点的权值之和。即,新树的权值是11。然后,将"树5"和"树6"从森林中删除,并将新的“树11”添加到森林中。
- 第3步:在森林中,选择根结点权值最小的两棵树即“树7”和“树8”来进行合并,得到的新树的权值是15。然后,将"树7"和"树8"从森林中删除,并将新的“树15”添加到森林中。
- 第4步:在森林中,选择根节点权值最小的两棵树(11和15)来进行合并。得到的新树的权值是26。然后,将"树11"和"树15"从森林中删除,并将新的树(树26)添加到森林中。
- 第5步:在森林中,选择根节点权值最小的两棵树即“树15”和“树26”来进行合并,得到的新树的权值是41。然后,将"树15"和"树26"从森林中删除,并将新的“树41”添加到森林中。
- 此时,森林中只有一棵树(树41)。这棵树就是我们需要的哈夫曼树!
- 各字符对应的编码为:“15”->0, “26”->1, “5”->100, “6”->101, “7”->110, "8"->111
Java实现哈夫曼编码
- 构造哈夫曼树的结点类
- 在实现这个部分的时候,根据老师的PPT所示,需要添加元素信息、权值、双亲、左孩子和右孩子,通过实现接口Comparable就利用权值进行比较,来确定是放在哈夫曼树的左侧还是右侧,针对建立的问题可以仿照之前的建立二叉树的结点差不多,给大家推荐一篇有关哈夫曼树的博客。在此基础上,为了方便输出它的0/1编码,需要见一个code变量,用来确定每一个的编码值。
public class HuffmanNode<T> implements Comparable<HuffmanNode<T>>{
private T letter;
private double weight;
private HuffmanNode lChild, rChild;
private String code;
public HuffmanNode(T letter, double weight){
this.letter = letter;
this.weight = weight;
code = "";
}
public T getLetter() {
return letter;
}
public double getWeight() {
return weight;
}
public HuffmanNode getlChild() {
return lChild;
}
public HuffmanNode getrChild() {
return rChild;
}
public String getCode() {
return code;
}
public void setLetter(T letter) {
this.letter = letter;
}
public void setWeight(double weight) {
this.weight = weight;
}
public void setlChild(HuffmanNode lChild) {
this.lChild = lChild;
}
public void setrChild(HuffmanNode rChild) {
this.rChild = rChild;
}
public void setCode(String code) {
this.code = code;
}
@Override
public String toString() {
return "Huffman: " + letter + " 权值:" + weight + "编码:" + code;
}
@Override
public int compareTo(HuffmanNode<T> huffmanNode) {
if(this.weight > huffmanNode.getWeight())
return -1;
else
return 1;
}
}
-
构造哈夫曼树
- 哈夫曼树的构造,并不需要像创建二叉树的那么多的方法,满足形成哈夫曼编码的部分就好。分享的那篇博客有相关的内容,我们只需要在此基础上添加每次创建的的编码值就可以,左侧0右侧1就可以。
- 创建树,先将结点进行排序,利用结点类中实现的比较方法,分别将左孩子定义为列表中的倒数第二个,因为左侧编码为0,所以让该结点的编码为0;右孩子为列表中的倒数第一个,因为右侧编码为1,所以让该结点的编码为1,双亲结点根据所讲内容为左右结点权重相加之和,把双亲结点加入列表中,然后删除倒数两个结点并添加双亲结点,再次进行循环,排序,不断从列表中把倒数两个结点删除,直至跳出循环,此时列表中的结点只剩一个,该结点的左右部分包含了所有按照编码进行添加的元素内容。
public HuffmanNode<T> createTree(List<HuffmanNode<T>> nodes) { while (nodes.size() > 1) { Collections.sort(nodes); HuffmanNode<T> left = nodes.get(nodes.size() - 2);//令其左孩子的编码为0 left.setCode("0"); HuffmanNode<T> right = nodes.get(nodes.size() - 1);//令其右孩子的编码为1 right.setCode("1"); HuffmanNode<T> parent = new HuffmanNode<T>(null, left.getWeight() + right.getWeight()); parent.setlChild(left); parent.setrChild(right); nodes.remove(left); nodes.remove(right); nodes.add(parent); } return nodes.get(0); }- 输出编码,利用哈夫曼树的createTree方法来实现编码内容,然后输出每一个结点的编码值,按照每个分支的0/1进行,左侧0右侧1进行。
public List<HuffmanNode<T>> breath(HuffmanNode<T> root) { List<HuffmanNode<T>> list = new ArrayList<HuffmanNode<T>>(); Queue<HuffmanNode<T>> queue = new LinkedList<>(); if (root != null) { queue.offer(root); root.getlChild().setCode(root.getCode() + "0"); root.getrChild().setCode(root.getCode() + "1"); } while (!queue.isEmpty()) { list.add(queue.peek()); HuffmanNode<T> node = queue.poll(); if (node.getlChild() != null) node.getlChild().setCode(node.getCode() + "0"); if (node.getrChild() != null) node.getrChild().setCode(node.getCode() + "1"); if (node.getlChild() != null) queue.offer(node.getlChild()); if (node.getrChild() != null) queue.offer(node.getrChild()); } return list; } -
编码与解码
- 编码部分,需要按照读取的内容进行添加每一个的编码值,变量result即为编码之后的内容,将这部分内容写入一个文件。
String result = ""; for(int f = 0; f < sum; f++){ for(int j = 0;j<letter.length;j++){ if(neirong.charAt(f) == letter[j].charAt(0)) result += code[j]; } }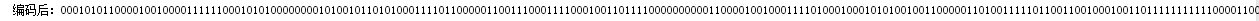
- 解码部分,需要每次调出编码内容的一个0/1,然后每读出一位就要判断一次是否有对应的编码值,如果有就输出,如果没有就不断往下读取内容,并删除读出的内容避免重复读取,直至将编码的内容全部读完解码完成。利用两个循环,外层循环进行每一次的添加一个编码位,内层循环将添加一位的内容进行对比,符合就为编码值,不符合就需要在添加一位。
for(int h = list4.size(); h > 0; h--){ string1 = string1 + list4.get(0); list4.remove(0); for(int i=0;i<code.length;i++){ if (string1.equals(code[i])) { string2 = string2+""+letter[i]; string1 = ""; } } }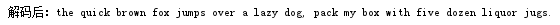
-
计算概率和重复次数
- 从文件中进行读取,并按照英文字母的种类进行记录每一个字母的出现次数,这里我添加了一个记录空格、逗号和句号,便于编写文件内容。针对文件中的内容总不能针对每一个位置都要循环确定一遍是否含有那个字母,利用我在实验室尝试过的代码,
Collections.frequency();来实现,里面的两个形式参数,按照第二个形式参数表现的内容,记录其在第一个列表内的重复次数,这样只需要将文件内容一每个字符的形式存放在一个列表中就行,然后进行比对即可。总的字符数目就是每一个字母的重复次数。
for(int a = 0; a <= getFileLineCount(file); a++){ String tp = bufferedReader.readLine(); neirong += tp; for(int b = 0; b < tp.length(); b++){ list2.add(String.valueOf(tp.charAt(b))); } Esum[0] += Collections.frequency(list2, list1.get(0)); Esum[1] += Collections.frequency(list2, list1.get(1)); Esum[2] += Collections.frequency(list2, list1.get(2)); Esum[3] += Collections.frequency(list2, list1.get(3)); Esum[4] += Collections.frequency(list2, list1.get(4)); Esum[5] += Collections.frequency(list2, list1.get(5)); Esum[6] += Collections.frequency(list2, list1.get(6)); Esum[7] += Collections.frequency(list2, list1.get(7)); Esum[8] += Collections.frequency(list2, list1.get(8)); Esum[9] += Collections.frequency(list2, list1.get(9)); Esum[10] += Collections.frequency(list2, list1.get(10)); Esum[11] += Collections.frequency(list2, list1.get(11)); Esum[12] += Collections.frequency(list2, list1.get(12)); Esum[13] += Collections.frequency(list2, list1.get(13)); Esum[14] += Collections.frequency(list2, list1.get(14)); Esum[15] += Collections.frequency(list2, list1.get(15)); Esum[16] += Collections.frequency(list2, list1.get(16)); Esum[17] += Collections.frequency(list2, list1.get(17)); Esum[18] += Collections.frequency(list2, list1.get(18)); Esum[19] += Collections.frequency(list2, list1.get(19)); Esum[20] += Collections.frequency(list2, list1.get(20)); Esum[21] += Collections.frequency(list2, list1.get(21)); Esum[22] += Collections.frequency(list2, list1.get(22)); Esum[23] += Collections.frequency(list2, list1.get(23)); Esum[24] += Collections.frequency(list2, list1.get(24)); Esum[25] += Collections.frequency(list2, list1.get(25)); Esum[26] += Collections.frequency(list2, list1.get(26)); Esum[27] += Collections.frequency(list2, list1.get(27)); Esum[28] += Collections.frequency(list2, list1.get(28)); }

- 总个数
for(int c = 0; c < Esum.length; c++) sum += Esum[c]; System.out.println("总字母个数:" + sum);在此部分我用了一个可以确定文件内容行数的方法,便于当文件出现多行的时候的读写和编码、解码的相关操作。

- 从文件中进行读取,并按照英文字母的种类进行记录每一个字母的出现次数,这里我添加了一个记录空格、逗号和句号,便于编写文件内容。针对文件中的内容总不能针对每一个位置都要循环确定一遍是否含有那个字母,利用我在实验室尝试过的代码,
-
读写文件
- 读写文件的部分只需要调用File相关类进行编写即可,我直接用了字符流直接将String类型的内容进行添加。
File file = new File("英文文件.txt"); File file1 = new File("编码文件.txt"); File file2 = new File("解码文件.txt"); if (!file1.exists() && !file2.exists()) { file1.createNewFile(); file2.createNewFile(); } FileReader fileReader = new FileReader(file); BufferedReader bufferedReader = new BufferedReader(fileReader); FileWriter fileWriter1 = new FileWriter(file1); FileWriter fileWriter2 = new FileWriter(file2); fileWriter1.write(result); fileWriter2.write(string2); fileWriter1.close(); fileWriter2.close();
码云链接
感悟
- 哈夫曼编码在刚开始的时候编得很混乱,在看过参考资料和同学的之后才理清思路,对于这种编码形式,很大程度上的解决了数据压缩的问题,便于存储数据。