文档下载,导入jsoup的jar包,处理html代码
<dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.7.3</version> </dependency>
以下是几个必要的文件:
RichHtmlHandler.java
import java.io.File; import java.io.FileNotFoundException; import java.io.FileWriter; import java.io.IOException; import java.util.ArrayList; import java.util.List; import java.util.UUID; import org.apache.commons.lang3.StringUtils; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; /** * @Description:富文本Html处理器,主要处理图片及编码 * */ public class RichHtmlHandler { private Document doc = null; private String html; private String docSrcParent = "paper.files"; //在paper.ftl文件里面找到,检索“Content-Location” private String docSrcLocationPrex = "file:///C:/D1324D12"; //在paper.ftl文件里面找到,检索“Content-Location” private String nextPartId = "01D2EB53.503F62F0"; //在paper.ftl文件里面找到,最末行 private String shapeidPrex = "_x56fe__x7247__x0020"; private String spidPrex = "_x0000_i"; private String typeid = "#_x0000_t75"; private String handledDocBodyBlock; private List<String> docBase64BlockResults = new ArrayList<String>(); private List<String> xmlImgRefs = new ArrayList<String>(); private String srcPath = ""; public RichHtmlHandler(){} public String getDocSrcLocationPrex() { return docSrcLocationPrex; } public void setDocSrcLocationPrex(String docSrcLocationPrex) { this.docSrcLocationPrex = docSrcLocationPrex; } public String getNextPartId() { return nextPartId; } public void setNextPartId(String nextPartId) { this.nextPartId = nextPartId; } public String getHandledDocBodyBlock() { String raw= WordHtmlGeneratorHelper.string2Ascii(doc.getElementsByTag("body").html()); return raw.replace("=3D", "=").replace("=", "=3D"); } public String getRawHandledDocBodyBlock() { String raw= doc.getElementsByTag("body").html(); return raw.replace("=3D", "=").replace("=", "=3D"); } public List<String> getDocBase64BlockResults() { return docBase64BlockResults; } public List<String> getXmlImgRefs() { return xmlImgRefs; } public String getShapeidPrex() { return shapeidPrex; } public void setShapeidPrex(String shapeidPrex) { this.shapeidPrex = shapeidPrex; } public String getSpidPrex() { return spidPrex; } public void setSpidPrex(String spidPrex) { this.spidPrex = spidPrex; } public String getTypeid() { return typeid; } public void setTypeid(String typeid) { this.typeid = typeid; } public String getDocSrcParent() { return docSrcParent; } public void setDocSrcParent(String docSrcParent) { this.docSrcParent = docSrcParent; } public String getHtml() { return html; } public void setHtml(String html) { this.html = html; } public RichHtmlHandler(String html, String srcPath) { this.html = html; this.srcPath = srcPath; doc = Jsoup.parse(wrappHtml(this.html)); try { handledHtml(false); } catch (IOException e) { e.printStackTrace(); } } public void re_init(String html){ doc=null; doc = Jsoup.parse(wrappHtml(html)); docBase64BlockResults.clear(); xmlImgRefs.clear(); } /** * @Description: 获得已经处理过的HTML文件 * @param @return * @return String * @throws IOException * @throws */ public void handledHtml(boolean isWebApplication) throws IOException { Elements imags = doc.getElementsByTag("img"); System.out.println("doc: "+doc); if (imags == null || imags.size() == 0) { // 返回编码后字符串 return; //handledDocBodyBlock = WordHtmlGeneratorHelper.string2Ascii(html); } // 转换成word mht 能识别图片标签内容,去替换html中的图片标签 for (Element item : imags) { // 把文件取出来 String src = item.attr("src"); String srcRealPath = srcPath + src; // String thepaths = RichHtmlHandler.class.getClassLoader().getResource("").toString(); // System.out.println("src="+src+" thepaths="+thepaths); if (isWebApplication) { // String contentPath=RequestResponseContext.getRequest().getContextPath(); // if(!StringUtils.isEmpty(contentPath)){ // if(src.startsWith(contentPath)){ // src=src.substring(contentPath.length()); // } // } // // srcRealPath = RequestResponseContext.getRequest().getSession() // .getServletContext().getRealPath(src); } File imageFile = new File(srcRealPath); String imageFielShortName = imageFile.getName(); String fileTypeName = WordImageConvertor.getFileSuffix(srcRealPath); String docFileName = "image" + UUID.randomUUID().toString() + "."+ fileTypeName; String srcLocationShortName = docSrcParent + "/" + docFileName; String styleAttr = item.attr("style"); // 样式 //高度 String imagHeightStr=item.attr("height"); if(StringUtils.isEmpty(imagHeightStr)){ imagHeightStr = getStyleAttrValue(styleAttr, "height"); } //宽度 String imagWidthStr=item.attr("width");; if(StringUtils.isEmpty(imagWidthStr)){ imagWidthStr = getStyleAttrValue(styleAttr, "width"); } imagHeightStr = imagHeightStr.replace("px", ""); imagWidthStr = imagWidthStr.replace("px", ""); if(StringUtils.isEmpty(imagHeightStr)){ //去得到默认的文件高度 imagHeightStr="0"; } if(StringUtils.isEmpty(imagWidthStr)){ imagWidthStr="0"; } int imageHeight = Integer.parseInt(imagHeightStr); int imageWidth = Integer.parseInt(imagWidthStr); // 得到文件的word mht的body块 String handledDocBodyBlock = WordImageConvertor.toDocBodyBlock(srcRealPath, imageFielShortName, imageHeight, imageWidth,styleAttr, srcLocationShortName, shapeidPrex, spidPrex, typeid); //这里的顺序有点问题:应该是替换item,而不是整个后面追加 //doc.rreplaceAll(item.toString(), handledDocBodyBlock); item.after(handledDocBodyBlock); // item.parent().append(handledDocBodyBlock); item.remove(); // 去替换原生的html中的imag String base64Content = WordImageConvertor.imageToBase64(srcRealPath); String contextLoacation = docSrcLocationPrex + "/" + docSrcParent + "/" + docFileName; String docBase64BlockResult = WordImageConvertor.generateImageBase64Block(nextPartId, contextLoacation, fileTypeName, base64Content); docBase64BlockResults.add(docBase64BlockResult); String imagXMLHref = "<o:File HRef=3D"" + docFileName + ""/>"; xmlImgRefs.add(imagXMLHref); } } private String getStyleAttrValue(String style, String attributeKey) { if (StringUtils.isEmpty(style)) { return ""; } // 以";"分割 String[] styleAttrValues = style.split(";"); for (String item : styleAttrValues) { // 在以 ":"分割 String[] keyValuePairs = item.split(":"); if (attributeKey.equals(keyValuePairs[0])) { return keyValuePairs[1]; } } return ""; } private String wrappHtml(String html){ // 因为传递过来都是不完整的doc StringBuilder sb = new StringBuilder(); sb.append("<html>"); sb.append("<body>"); sb.append(html); sb.append("</body>"); sb.append("</html>"); return sb.toString(); } public String getData(List<String> list){ String data = ""; if (list != null && list.size() > 0) { for (String string : list) { data += string + " "; } } return data; } }
WordHtmlGeneratorHelper.java
import java.lang.reflect.Field; import java.util.ArrayList; import java.util.Collection; import java.util.Date; import java.util.List; import java.util.Map; import org.apache.commons.beanutils.PropertyUtils; import org.springframework.util.ReflectionUtils; import org.apache.commons.lang3.StringUtils; import org.springframework.util.ReflectionUtils.FieldCallback; /** * @Description:word 网页导出(单文件网页导出,mht文件格式) * */ public class WordHtmlGeneratorHelper { /** * @Description: 将字符换成3Dus-asci,十进制Accsii码 * @param @param source * @param @return * @return String * @throws */ public static String string2Ascii(String source){ if(source==null || source==""){ return null; } StringBuilder sb=new StringBuilder(); char[] c=source.toCharArray(); for(char item : c){ String itemascii=""; if(item>=19968 && item<40623){ itemascii=itemascii="&#"+(item & 0xffff)+";"; }else{ itemascii=item+""; } sb.append(itemascii); } return sb.toString(); } /** * @Description: 将object的所有属性值转成成3Dus-asci编码值 * @param @param object * @param @return * @return T * @throws */ public static <T extends Object> T handleObject2Ascii(final T toHandleObject){ class myFieldsCallBack implements FieldCallback{ @Override public void doWith(Field f) throws IllegalArgumentException, IllegalAccessException { if(f.getType().equals(String.class)){ //如果是字符串类型 f.setAccessible(true); String oldValue=(String)f.get(toHandleObject); if(!StringUtils.isEmpty(oldValue)){ f.set(toHandleObject, string2Ascii(oldValue)); } //f.setAccessible(false); } } } ReflectionUtils.doWithFields(toHandleObject.getClass(), new myFieldsCallBack()); return toHandleObject; } public static <T extends Object> List<T> handleObjectList2Ascii(final List<T> toHandleObjects){ for (T t : toHandleObjects) { handleObject2Ascii(t); } return toHandleObjects; } public static void handleAllObject(Map<String, Object> dataMap){ //去处理数据 for (Map.Entry<String, Object> entry : dataMap.entrySet()){ Object item=entry.getValue(); //判断object是否是primitive type if(isPrimitiveType(item.getClass())){ if(item.getClass().equals(String.class)){ item=WordHtmlGeneratorHelper.string2Ascii((String)item); entry.setValue(item); } }else if(isCollection(item.getClass())){ for (Object itemobject : (Collection)item) { WordHtmlGeneratorHelper.handleObject2Ascii(itemobject); } }else{ WordHtmlGeneratorHelper.handleObject2Ascii(item); } } } public static String joinList(List<String> list,String join ){ StringBuilder sb=new StringBuilder(); for (String t : list) { sb.append(t); if(!StringUtils.isEmpty(join)){ sb.append(join); } } return sb.toString(); } private static boolean isPrimitiveType(Class<?> clazz){ return clazz.isEnum() || CharSequence.class.isAssignableFrom(clazz) || Number.class.isAssignableFrom(clazz) || Date.class.isAssignableFrom(clazz); } private static boolean isCollection(Class<?> clazz){ return Collection.class.isAssignableFrom(clazz); } }
WordImageConvertor.java
import java.awt.image.BufferedImage; import java.io.ByteArrayOutputStream; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.math.BigDecimal; import java.util.UUID; import javax.imageio.ImageIO; import org.apache.commons.codec.binary.Base64; import sun.misc.BASE64Encoder; /** * @Description:WORD 文档图片转换器 * */ public class WordImageConvertor { //private static Const WORD_IMAGE_SHAPE_TYPE_ID=""; /** * @Description: 将图片转换成base64编码的字符串 * @param @param imageSrc 文件路径 * @param @return * @return String * @throws IOException * @throws */ public static String imageToBase64(String imageSrc) throws IOException{ //判断文件是否存在 File file=new File(imageSrc); if(!file.exists()){ throw new FileNotFoundException("文件不存在!"); } StringBuilder pictureBuffer = new StringBuilder(); FileInputStream input=new FileInputStream(file); ByteArrayOutputStream out = new ByteArrayOutputStream(); //读取文件 //BufferedInputStream bi=new BufferedInputStream(in); Base64 base64=new Base64(); BASE64Encoder encoder=new BASE64Encoder(); byte[] temp = new byte[1024]; for(int len = input.read(temp); len != -1;len = input.read(temp)){ out.write(temp, 0, len); //out(pictureBuffer.toString()); //out.reset(); } pictureBuffer.append(new String( base64.encodeBase64Chunked(out.toByteArray()))); //pictureBuffer.append(encoder.encodeBuffer(out.toByteArray())); /*byte[] data=new byte[input.available()]; input.read(data); pictureBuffer.append(base64.encodeBase64String (data));*/ input.close(); /*BASE64Decoder decoder=new BASE64Decoder(); FileOutputStream write = new FileOutputStream(new File("c:\test2.jpg")); //byte[] decoderBytes = decoder.decodeBuffer (pictureBuffer.toString()); byte[] decoderBytes = base64.decodeBase64(pictureBuffer.toString()); write.write(decoderBytes); write.close();*/ return pictureBuffer.toString(); } public static String toDocBodyBlock( String imageFilePath, String imageFielShortName, int imageHeight, int imageWidth, String imageStyle, String srcLocationShortName, String shapeidPrex,String spidPrex,String typeid){ //shapeid //mht文件中针对shapeid的生成好像规律,其内置的生成函数没法得知,但是只要保证其唯一就行 //这里用前置加32位的uuid来保证其唯一性。 String shapeid=shapeidPrex; shapeid+=UUID.randomUUID().toString(); //spid ,同shapeid处理 String spid=spidPrex; spid+=UUID.randomUUID().toString(); /* <!--[if gte vml 1]><v:shape id=3D"_x56fe__x7247__x0020_0" o:spid=3D"_x0000_i10= 26" type=3D"#_x0000_t75" alt=3D"725017921264249223.jpg" style=3D'456.7= 5pt; height:340.5pt;visibility:visible;mso-wrap-style:square'> <v:imagedata src=3D"file9462.files/image001.jpg" o:title=3D"725017921264= 249223"/> </v:shape><![endif]--><![if !vml]><img width=3D609 height=3D454 src=3D"file9462.files/image002.jpg" alt=3D725017921264249223.jpg v:shapes= =3D"_x56fe__x7247__x0020_0"><![endif]>*/ StringBuilder sb1=new StringBuilder(); sb1.append(" <!--[if gte vml 1]>"); sb1.append("<v:shape id=3D"" + shapeid+"""); sb1.append(" "); sb1.append(" o:spid=3D""+ spid +""" ); sb1.append(" type=3D""+ typeid +"" alt=3D"" + imageFielShortName +"""); sb1.append(" "); sb1.append( " style=3D' " + generateImageBodyBlockStyleAttr(imageFilePath,imageHeight,imageWidth) + imageStyle +"'"); sb1.append(">"); sb1.append(" "); sb1.append(" <v:imagedata src=3D"" + srcLocationShortName +""" ); sb1.append(" "); sb1.append(" o:title=3D"" + imageFielShortName.split("\.")[0]+""" ); sb1.append("/>"); sb1.append("</v:shape>"); sb1.append("<![endif]-->"); //以下是为了兼容游览器显示时的效果,但是如果是纯word阅读的话没必要这么做。 /* StringBuilder sb2=new StringBuilder(); sb2.append(" <![if !vml]>"); sb2.append("<img width=3D"+imageWidth +" height=3D" +imageHeight + " src=3D"" + srcLocationShortName +"" alt=" +imageFielShortName+ " v:shapes=3D"" + shapeid +"">"); sb2.append("<![endif]>");*/ //return sb1.toString()+sb2.toString(); return sb1.toString(); } /** * @Description: 生成图片的base4块 * @param @param nextPartId * @param @param contextLoacation * @param @param ContentType * @param @param base64Content * @param @return * @return String * @throws */ public static String generateImageBase64Block(String nextPartId,String contextLoacation, String fileTypeName,String base64Content){ /*--=_NextPart_01D188DB.E436D870 Content-Location: file:///C:/70ED9946/file9462.files/image001.jpg Content-Transfer-Encoding: base64 Content-Type: image/jpeg base64Content */ StringBuilder sb=new StringBuilder(); sb.append(" "); sb.append(" "); sb.append("------=_NextPart_"+nextPartId); sb.append(" "); sb.append("Content-Location: "+ contextLoacation); sb.append(" "); sb.append("Content-Transfer-Encoding: base64"); sb.append(" "); sb.append("Content-Type: " + getImageContentType(fileTypeName)); sb.append(" "); sb.append(" "); sb.append(base64Content); return sb.toString(); } private static String generateImageBodyBlockStyleAttr(String imageFilePath, int height,int width){ StringBuilder sb=new StringBuilder(); BufferedImage sourceImg; try { sourceImg = ImageIO.read(new FileInputStream(imageFilePath)); if(height==0){ height=sourceImg.getHeight(); } if(width==0){ width=sourceImg.getWidth(); } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } //将像素转化成pt BigDecimal heightValue=new BigDecimal(height*12/16); heightValue= heightValue.setScale(2, BigDecimal.ROUND_HALF_UP); BigDecimal widthValue=new BigDecimal(width*12/16); widthValue= widthValue.setScale(2, BigDecimal.ROUND_HALF_UP); sb.append("height:"+heightValue +"pt;"); sb.append(""+widthValue +"pt;"); sb.append("visibility:visible;"); sb.append("mso-wrap-style:square; "); return sb.toString(); } private static String getImageContentType(String fileTypeName){ String result="image/jpeg"; //http://tools.jb51.net/table/http_content_type if(fileTypeName.equals("tif") || fileTypeName.equals("tiff")){ result="image/tiff"; }else if(fileTypeName.equals("fax")){ result="image/fax"; }else if(fileTypeName.equals("gif")){ result="image/gif"; }else if(fileTypeName.equals("ico")){ result="image/x-icon"; }else if(fileTypeName.equals("jfif") || fileTypeName.equals("jpe") ||fileTypeName.equals("jpeg") ||fileTypeName.equals("jpg")){ result="image/jpeg"; }else if(fileTypeName.equals("net")){ result="image/pnetvue"; }else if(fileTypeName.equals("png") || fileTypeName.equals("bmp") ){ result="image/png"; }else if(fileTypeName.equals("rp")){ result="image/vnd.rn-realpix"; }else if(fileTypeName.equals("rp")){ result="image/vnd.rn-realpix"; } return result; } public static String getFileSuffix(String srcRealPath){ int lastIndex = srcRealPath.lastIndexOf("."); String suffix = srcRealPath.substring(lastIndex + 1); // String suffix = srcRealPath.substring(srcRealPath.indexOf(".")+1); return suffix; } }
Test.java
//content:待处理的富文本内容, 比如: 图片上传对对对 <img src="/../upload/image/20170615/1497500926071064595.jpg" title="1497500926071064595.jpg" _src="/../upload/image/20170615/1497500926071064595.jpg" alt="ie知 识点请求2.jpg" width="178" height="83" style=" 178px; height: 83px;" />不对fdasdfsadfsadffD RichHtmlHandler handler = new RichHtmlHandler(content, appRoot + File.separator); bo.setQuestionContent(handler.getHandledDocBodyBlock()); handledBase64Block += handler.getData(handler.getDocBase64BlockResults()); xmlimaHref += handler.getData(handler.getXmlImgRefs()); dataMap.put("imagesBase64String", handledBase64Block); dataMap.put("imagesXmlHrefString", xmlimaHref);
paper.ftl 里面要有相关的占位符${imagesBase64String} 、${imagesXmlHrefString}
MIME-Version: 1.0 Content-Type: multipart/related; boundary="----=_NextPart_01D2EB53.503F62F0" 此文档为“单个文件网页”,也称为“Web 档案”文件。如果您看到此消息,但是您的浏览器或编辑器不支持“Web 档案”文件。请下载支持“Web 档案”的浏览器,如 Windows? Internet Explorer?。 ------=_NextPart_01D2EB53.503F62F0 Content-Location: file:///C:/D1324D12/paper.htm Content-Transfer-Encoding: quoted-printable Content-Type: text/html; charset=3D"utf-8" <html xmlns:v=3D"urn:schemas-microsoft-com:vml" xmlns:o=3D"urn:schemas-microsoft-com:office:office" xmlns:w=3D"urn:schemas-microsoft-com:office:word" xmlns:m=3D"http://schemas.microsoft.com/office/2004/12/omml" xmlns=3D"http://www.w3.org/TR/REC-html40"> <head> <meta http-equiv=3DContent-Type content=3D"text/html; charset=3Dutf-8"> ---- ---- ---- ----- ----- ------ ------- --------省略。。。。。 </body> </html> ------=_NextPart_01D2EB53.503F62F0 Content-Location: file:///C:/D1324D12/paper.files/filelist.xml Content-Transfer-Encoding: quoted-printable Content-Type: text/xml; charset="utf-8" <xml xmlns:o=3D"urn:schemas-microsoft-com:office:office"> <o:MainFile HRef=3D"../paper.htm"/> <o:File HRef=3D"themedata.thmx"/> <o:File HRef=3D"colorschememapping.xml"/> ${imagesXmlHrefString} <o:File HRef=3D"header.htm"/> <o:File HRef=3D"filelist.xml"/> </xml> ------=_NextPart_01D2EB53.503F62F0--
网页效果: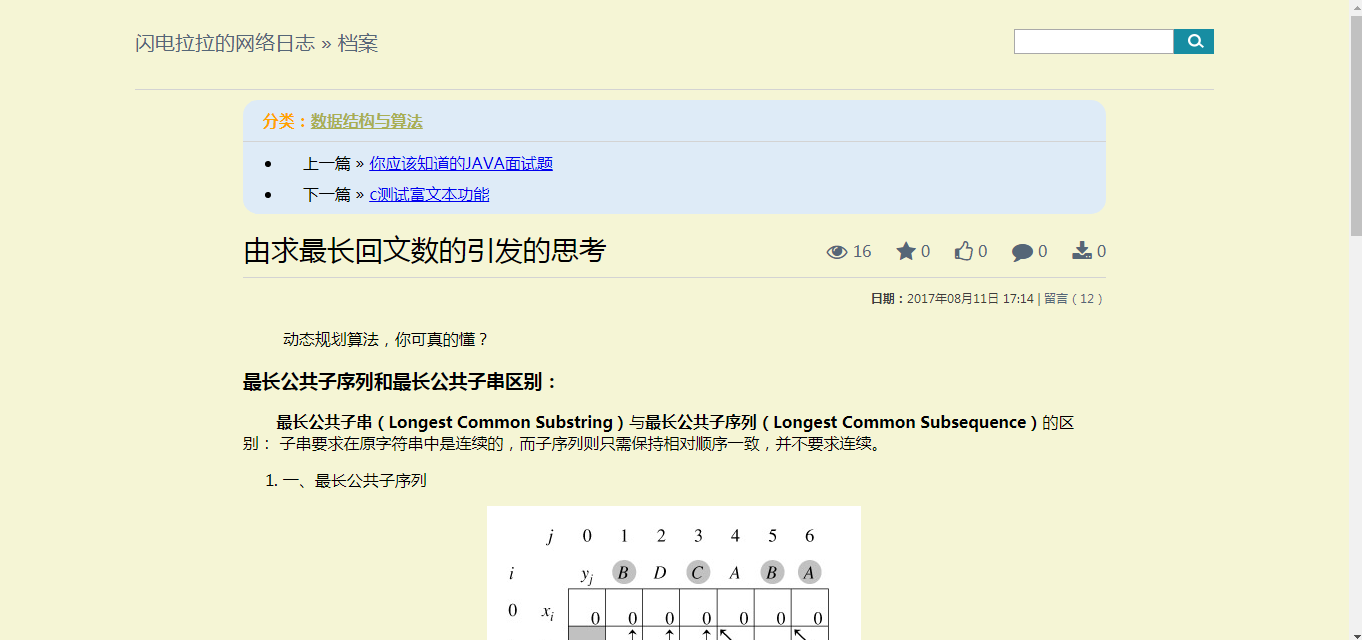
下载效果:
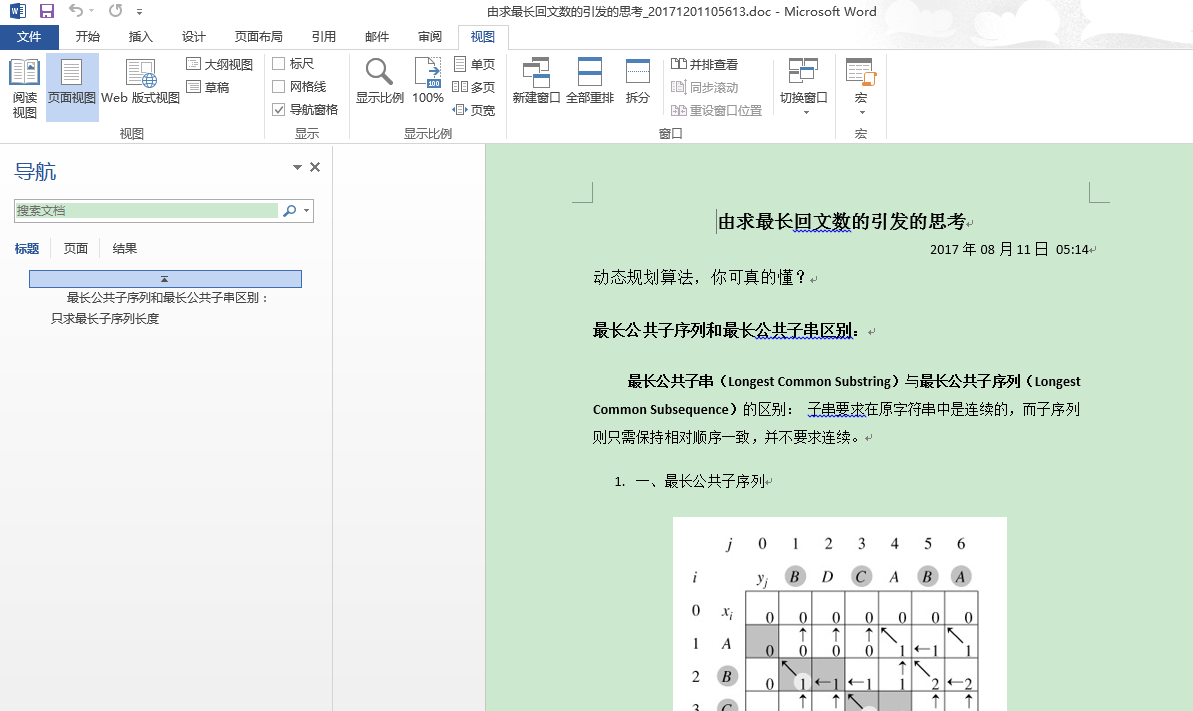
完整代码: https://github.com/shandianlala/sdll-blog
欢迎加入“Java Communication” 交流群,群号:622810880