背景
使用spark开发已有几个月。相比于python/hive,scala/spark学习门槛较高。尤其记得刚开时,举步维艰,进展十分缓慢。不过谢天谢地,这段苦涩(bi)的日子过去了。忆苦思甜,为了避免项目组的其他同学走弯路,决定总结和梳理spark的使用经验。
Spark基础
基石RDD
spark的核心是RDD(弹性分布式数据集),一种通用的数据抽象,封装了基础的数据操作,如map,filter,reduce等。RDD提供数据共享的抽象,相比其他大数据处理框架,如MapReduce,Pegel,DryadLINQ和HIVE等均缺乏此特性,所以RDD更为通用。
简要地概括RDD:RDD是一个不可修改的,分布的对象集合。每个RDD由多个分区组成,每个分区可以同时在集群中的不同节点上计算。RDD可以包含Python,Java和Scala中的任意对象。
Spark生态圈中应用都是基于RDD构建(下图),这一点充分说明RDD的抽象足够通用,可以描述大多数应用场景。
RDD操作类型—转换和动作
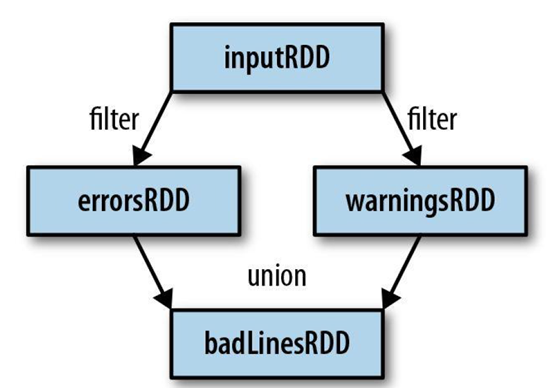
RDD的操作主要分两类:转换(transformation)和动作(action)。两类函数的主要区别是,转换接受RDD并返回RDD,而动作接受RDD但是返回非RDD。转换采用惰性调用机制,每个RDD记录父RDD转换的方法,这种调用链表称之为血缘(lineage);而动作调用会直接计算。
采用惰性调用,通过血缘连接的RDD操作可以管道化(pipeline),管道化的操作可以直接在单节点完成,避免多次转换操作之间数据同步的等待。
使用血缘串联的操作可以保持每次计算相对简单,而不用担心有过多的中间数据,因为这些血缘操作都管道化了,这样也保证了逻辑的单一性,而不用像MapReduce那样,为了竟可能的减少map reduce过程,在单个map reduce中写入过多复杂的逻辑。
RDD使用模式
RDD使用具有一般的模式,可以抽象为下面的几步
-
加载外部数据,创建RDD对象
-
使用转换(如filter),创建新的RDD对象
-
缓存需要重用的RDD
-
使用动作(如count),启动并行计算
RDD高效的策略
Spark官方提供的数据是RDD在某些场景下,计算效率是Hadoop的20X。这个数据是否有水分,我们先不追究,但是RDD效率高的由一定机制保证的:
-
RDD数据只读,不可修改。如果需要修改数据,必须从父RDD转换(transformation)到子RDD。所以,在容错策略中,RDD没有数据冗余,而是通过RDD父子依赖(血缘)关系进行重算实现容错。
-
RDD数据在内存中,多个RDD操作之间,数据不用落地到磁盘上,避免不必要的I/O操作。
-
RDD存放的数据可以是java对象,所以避免的不必要的对象序列化和反序列化。
总而言之,RDD高效的主要因素是尽量避免不必要的操作和牺牲数据的操作精度,用来提高计算效率。
Spark使用技巧
RDD基本函数扩展
RDD虽然提供了很多函数,但是毕竟还是有限的,有时候需要扩展,自定义新的RDD的函数。在spark中,可以通过隐式转换,轻松实现对RDD扩展。画像开发过程中,平凡的会使用rollup操作(类似HIVE中的rollup),计算多个级别的聚合数据。下面是具体实,
|
/** * 扩展spark rdd,为rdd提供rollup方法 */ implicit class RollupRDD[T: ClassTag](rdd: RDD[(Array[String], T)]) extends Serializable { /** * 类似Sql中的rollup操作 * * @param aggregate 聚合函数 * @param keyPlaceHold key占位符,默认采用FaceConf.STAT_SUMMARY * @param isCache,确认是否缓存数据 * @return 返回聚合后的数据 */ def rollup[U: ClassTag]( aggregate: Iterable[T] => U, keyPlaceHold: String = FaceConf.STAT_SUMMARY, isCache: Boolean = true): RDD[(Array[String], U)] = { if (rdd.take(1).isEmpty) { return rdd.map(x => (Array[String](), aggregate(Array[T](x._2)))) } if (isCache) { rdd.cache // 提高计算效率 } val totalKeyCount = rdd.first._1.size val result = { 1 to totalKeyCount }.par.map(untilKeyIndex => { // 并行计算 rdd.map(row => { val combineKey = row._1.slice(0, untilKeyIndex).mkString(FaceConf.KEY_SEP) // 组合key (combineKey, row._2) }).groupByKey.map(row => { // 聚合计算 val oldKeyList = row._1.split(FaceConf.KEY_SEP) val newKeyList = oldKeyList ++ Array.fill(totalKeyCount - oldKeyList.size) { keyPlaceHold } (newKeyList, aggregate(row._2)) }) }).reduce(_ ++ _) // 聚合结果 result } } |
上面代码声明了一个隐式类,具有一个成员变量rdd,类型是RDD[(Array[String], T)],那么如果应用代码中出现了任何这样的rdd对象,并且import当前的隐式转换,那么编译器就会将这个rdd当做上面的隐式类的对象,也就可以使用rollup函数,和一般的map,filter方法一样。
RDD操作闭包外部变量原则

RDD相关操作都需要传入自定义闭包函数(closure),如果这个函数需要访问外部变量,那么需要遵循一定的规则,否则会抛出运行时异常。闭包函数传入到节点时,需要经过下面的步骤:
- 驱动程序,通过反射,运行时找到闭包访问的所有变量,并封成一个对象,然后序列化该对象
- 将序列化后的对象通过网络传输到worker节点
- worker节点反序列化闭包对象
- worker节点执行闭包函数,
注意:外部变量在闭包内的修改不会被反馈到驱动程序。
简而言之,就是通过网络,传递函数,然后执行。所以,被传递的变量必须可以序列化,否则传递失败。本地执行时,仍然会执行上面四步。
广播机制也可以做到这一点,但是频繁的使用广播会使代码不够简洁,而且广播设计的初衷是将较大数据缓存到节点上,避免多次数据传输,提高计算效率,而不是用于进行外部变量访问。
RDD数据同步
RDD目前提供两个数据同步的方法:广播和累计器。
广播 broadcast
前面提到过,广播可以将变量发送到闭包中,被闭包使用。但是,广播还有一个作用是同步较大数据。比如你有一个IP库,可能有几G,在map操作中,依赖这个ip库。那么,可以通过广播将这个ip库传到闭包中,被并行的任务应用。广播通过两个方面提高数据共享效率:1,集群中每个节点(物理机器)只有一个副本,默认的闭包是每个任务一个副本;2,广播传输是通过BT下载模式实现的,也就是P2P下载,在集群多的情况下,可以极大的提高数据传输速率。广播变量修改后,不会反馈到其他节点。
累加器 Accumulator
累加器是一个write-only的变量,用于累加各个任务中的状态,只有在驱动程序中,才能访问累加器。而且,截止到1.2版本,累加器有一个已知的缺陷,在action操作中,n个元素的RDD可以确保累加器只累加n次,但是在transformation时,spark不确保,也就是累加器可能出现n+1次累加。
目前RDD提供的同步机制粒度太粗,尤其是转换操作中变量状态不能同步,所以RDD无法做复杂的具有状态的事务操作。不过,RDD的使命是提供一个通用的并行计算框架,估计永远也不会提供细粒度的数据同步机制,因为这与其设计的初衷是违背的。
RDD优化技巧
RDD缓存
需要使用多次的数据需要cache,否则会进行不必要的重复操作。举个例子
|
val data = … // read from tdw println(data.filter(_.contains("error")).count) println(data.filter(_.contains("warning")).count) |
上面三段代码中,data变量会加载两次,高效的做法是在data加载完后,立刻持久化到内存中,如下
|
val data = … // read from tdw data.cache println(data.filter(_.contains("error")).count) println(data.filter(_.contains("warning")).count) |
这样,data在第一加载后,就被缓存到内存中,后面两次操作均直接使用内存中的数据。
转换并行化
RDD的转换操作时并行化计算的,但是多个RDD的转换同样是可以并行的,参考如下
|
val dataList:Array[RDD[Int]] = … val sumList = data.list.map(_.map(_.sum)) |
上面的例子中,第一个map是便利Array变量,串行的计算每个RDD中的每行的sum。由于每个RDD之间计算是没有逻辑联系的,所以理论上是可以将RDD的计算并行化的,在scala中可以轻松试下,如下
|
val dataList:Array[RDD[Int]] = … val sumList = data.list.par.map(_.map(_.sum)) |
注意红色代码。
减少shuffle网络传输
一般而言,网络I/O开销是很大的,减少网络开销,可以显著加快计算效率。任意两个RDD的shuffle操作(join等)的大致过程如下,
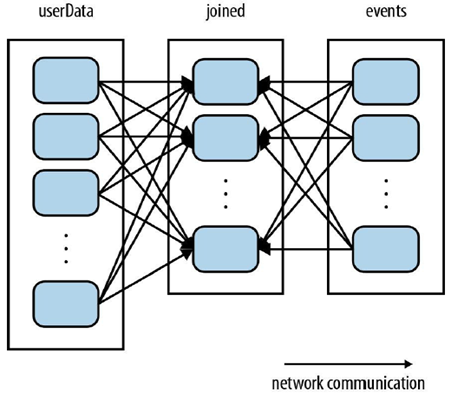
用户数据userData和事件events数据通过用户id连接,那么会在网络中传到另外一个节点,这个过程中,有两个网络传输过程。Spark的默认是完成这两个过程。但是,如果你多告诉spark一些信息,spark可以优化,只执行一个网络传输。可以通过使用、HashPartition,在userData"本地"先分区,然后要求events直接shuffle到userData的节点上,那么就减少了一部分网络传输,减少后的效果如下,
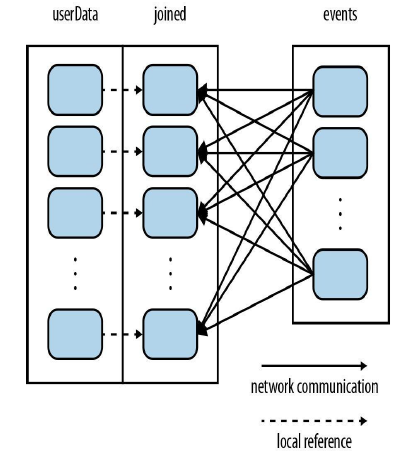
虚线部分都是在本地完成的,没有网络传输。在数据加载时,就按照key进行partition,这样可以经一部的减少本地的HashPartition的过程,示例代码如下
|
val userData = sc.sequenceFile[UserID, UserInfo]("hdfs://…") .partitionBy(new HashPartitioner(100)) // Create 100 partitions .persist() |
注意,上面一定要persist,否则会重复计算多次。100用来指定并行数量。
Spark其他
Spark开发模式
由于spark应用程序是需要在部署到集群上运行的,导致本地调试比较麻烦,所以经过这段时间的经验累积,总结了一套开发流程,目的是为了尽可能的提高开发调试效率,同时保证开发质量。当然,这套流程可能也不是最优的,后面需要持续改进。
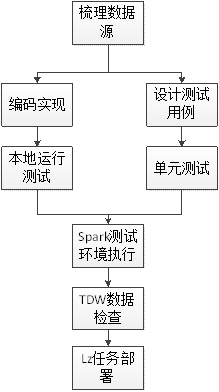
整个流程比较清楚,这里主要谈谈为什么需要单元测试。公司内的大多数项目,一般不提倡单元测试,而且由于项目进度压力,开发人员会非常抵触单元测试,因为会花费"额外"的精力。Bug这东西不会因为项目赶进度而消失,而且恰好相反,可能因为赶进度,而高于平均水平。所以,如果不花时间进行单元测试,那么会花同样多,甚至更多的时间调试。很多时候,往往一些很小的bug,却导致你花了很长时间去调试,而这些bug,恰好是很容易在单元测试中发现的。而且,单元测试还可以带来两个额外的好处:1)API使用范例;2)回归测试。所以,还是单元测试吧,这是一笔投资,而且ROI还挺高!不过凡事需要掌握分寸,单元测试应该根据项目紧迫程度调整粒度,做到有所为,有所不为。
Spark其他功能
前面提到了spark生态圈,spark除了核心的RDD,还提供了之上的几个很使用的应用:
-
Spark SQL: 类似hive,使用rdd实现sql查询
-
Spark Streaming: 流式计算,提供实时计算功能,类似storm
-
MLLib:机器学习库,提供常用分类,聚类,回归,交叉检验等机器学习算法并行实现。
-
GraphX:图计算框架,实现了基本的图计算功能,常用图算法和pregel图编程框架。
后面需要继续学习和使用上面的功能,尤其是与数据挖掘强相关的MLLib。
参考资料