转自:http://www.cnblogs.com/ohuang/p/5807543.html
解决的问题
HBase的Write Ahead Log (WAL)提供了一种高并发、持久化的日志保存与回放机制。每一个业务数据的写入操作(PUT / DELETE)执行前,都会记账在WAL中。
如果出现HBase服务器宕机,则可以从WAL中回放执行之前没有完成的操作。
本文主要探讨HBase的WAL机制,如何从线程模型、消息机制的层面上,解决这些问题:
1. 由于多个HBase客户端可以对某一台HBase Region Server发起并发的业务数据写入请求,因此WAL也要支持并发的多线程日志写入。——确保日志写入的线程安全、高并发。
2. 对于单个HBase客户端,它在WAL中的日志顺序,应该与这个客户端发起的业务数据写入请求的顺序一致。
(对于以上两点要求,大家很容易想到,用一个队列就搞定了。见下文的架构图。)
3. 为了保证高可靠,日志不仅要写入文件系统的内存缓存,而且应该尽快、强制刷到磁盘上(即WAL的Sync操作)。但是Sync太频繁,性能会变差。所以:
(1) Sync应当在多个后台线程中异步执行
(2) 频繁的多个Sync,可以合并为一次Sync——适当放松对可靠性的要求,提高性能。
架构图——线程模型、消息机制
下面是我画的HBase WAL架构图。我在图上加了不少注解,所以这张图应该是自解释的:
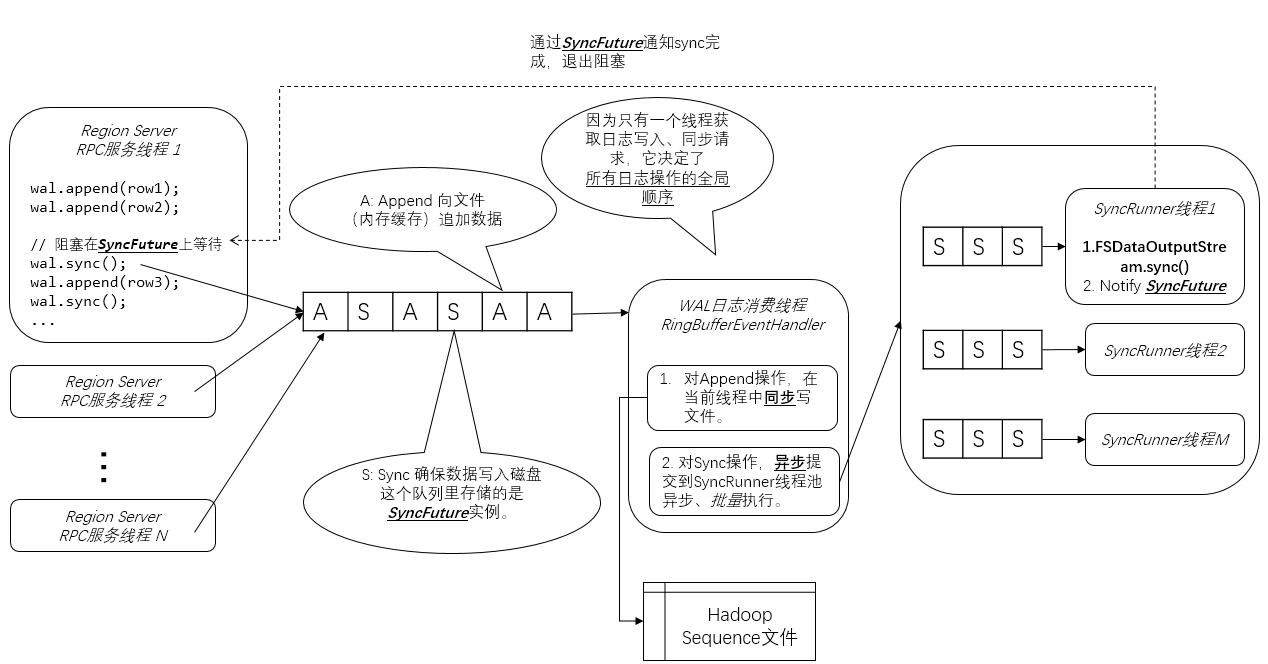
Region Server RPC服务线程
这些线程处理HBase客户端通过RPC服务调用(实际上是Google Protobuf服务调用)发出的业务数据写入请求。在上图的例子中,“Region Server RPC服务线程1” 做了3个Row的Append操作,和一个强制刷磁盘的Sync操作。
Sync操作是为了确保之前的Append操作(包括涉及的业务数据)一定可靠地记录到了磁盘上的日志中,然后HBase才能做后续相对不可靠的复杂操作,比如写入MemStore。——这就是Write Ahead的语义。
从架构图中可见,并发的Append操作只是往队列中增加了Append请求对象。
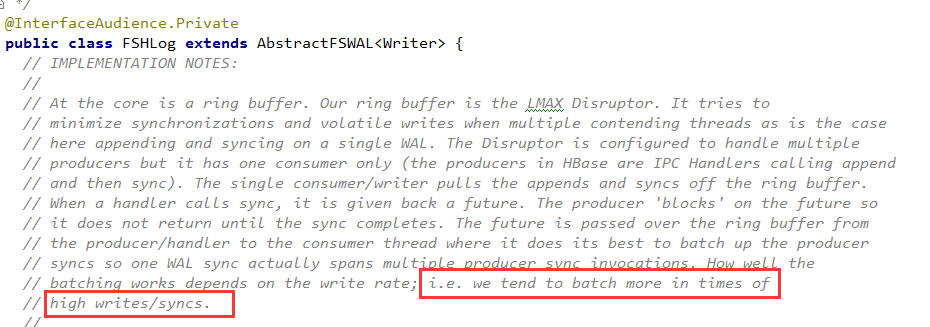
这里的队列是一个LMAX Disrutpor RingBuffer(我的这篇文章作了介绍),你可以简单理解为是一个无锁高并发队列。
Append的具体代码如下:

对于Sync操作:
(1)往队列里放一个SyncFuture对象,代表一次Sync操作请求。
每一个SyncFuture都有一个自增的Sequence ID——这是全局唯一的,由LMAX Disrutpor队列创建。后来的SyncFuture的Sequence ID更高。
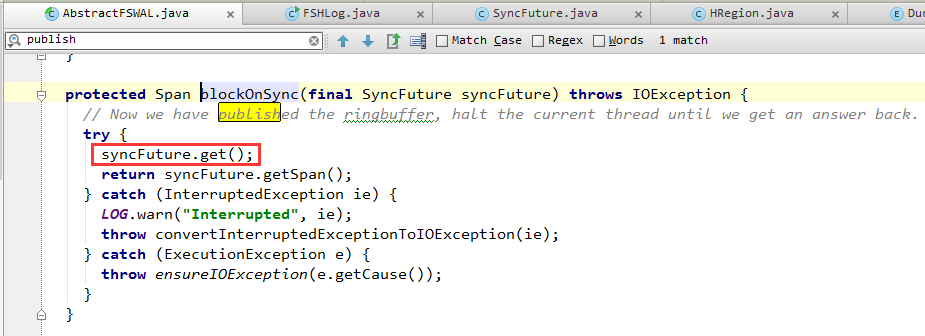
(2)调用SyncFuture.get()阻塞等待,直到后台线程(架构图中的SyncRunner)通知SyncFuture退出阻塞,表明WAL日志已经保存在了磁盘上。
WAL日志消费线程
WAL机制中,只有一个WAL日志消费线程,从队列中获取Append和Sync操作。这样一个多生产者,单消费者的模式,决定了WAL日志并发写入时日志的全局唯一顺序。
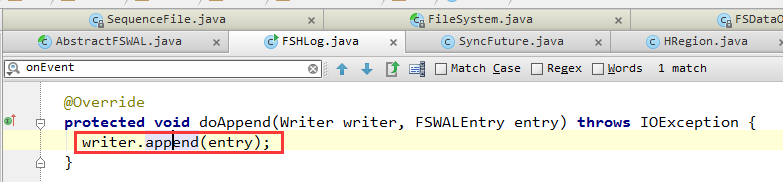
1. 对于获取到的Append操作,直接调用Hadoop Sequence File Writer将这个Append操作(包括元数据和row key, family, qualifier, timestamp, value等业务数据)写入文件。
因此WAL日志文件使用的是Hadoop Sequence文件格式。当然,它也可以替换成其他存储格式,如Avro。
Hadoop Sequence文件格式不再这里累述,其主要特点是:
(1) 二进制格式。row key, family, qualifier, timestamp, value等HBase byte[]数据,都原封不动地顺序写入文件。
(2) Sequence文件中,每隔若干行,会插入一个16字节的魔数作为分隔符。这样如果文件损坏,导致某一行残缺不全,可以通过这个魔数分隔符跳过这一行,继续读取下一个完整的行。
(3) 支持压缩。可以按行压缩。也可以按块压缩(将多行打成一个块)
2. 对于获取到的Sync操作,会提交给后台SyncRunner的线程池(见上文架构图)异步执行。

以上的this.syncRunners就是SyncRunner线程池。可以看到,通过计算syncRunnerIndex,采用了简单的轮循提交算法。
- 另外,WAL日志消费线程,会尝试收集一批SyncFuture对象(即sync操作),一次提交给SyncRunner。
所以,在以上代码中,可以看到传入offer()方法的,是this.syncFutures这一SyncFutures[]数组,而不是单个SyncFuture对象。
收集一批次再提交,性能比较好。但是单个批次需要积攒的SyncFuture对象越多,则Sync的及时性越差,会导致前台Region Server RPC服务线程阻塞在SyncFuture.get()上的时间就越长。
因此,这里存在吞吐量和及时性之间的平衡。HBase为了支持海量数据的写入,在这里更倾向于高吞吐量,体现在了以下注释中。具体多少个SyncFuture构成一个批次,有一定的策略,在此不再累述。
SyncRunner线程
1. 从队列中获取一个由WAL日志消费线程提交的SyncFuture(下图红框中的代码)。
2. 调用文件系统API,执行sync()操作(下图蓝框中的代码)
- 合并多次频繁的sync()操作,提高性能。
上文提到,WAL日志消费线程一次会提交多个SyncFuture。对此,SyncRunner线程只会落实执行其中最新的SyncFuture(也就是Sequence ID最大的那个)所代表的Sync操作。而忽略之前的SyncFuture。
这就是下图绿框中的代码。
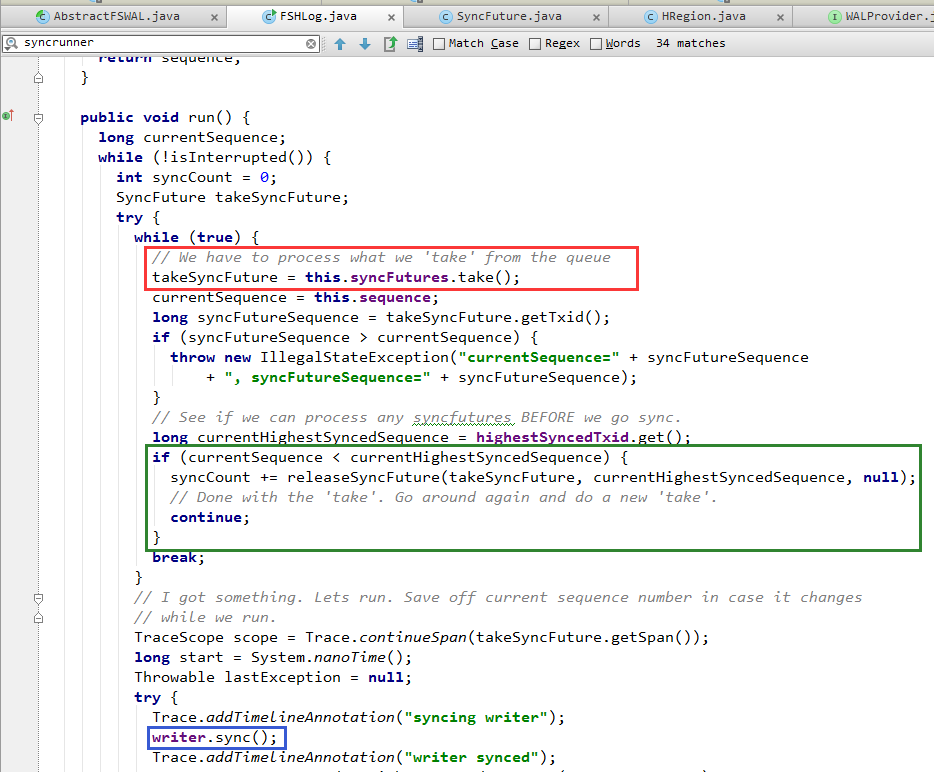
3. 如果sync()完成,或者因为上面提到的合并忽略了某一个SyncFuture,那么会调用releaseSyncFuture() ==> Object.notify()来通知SyncFuture阻塞退出。
之前阻塞在SyncFuture.get()上的Region Server RPC服务线程就可以继续往下执行了。
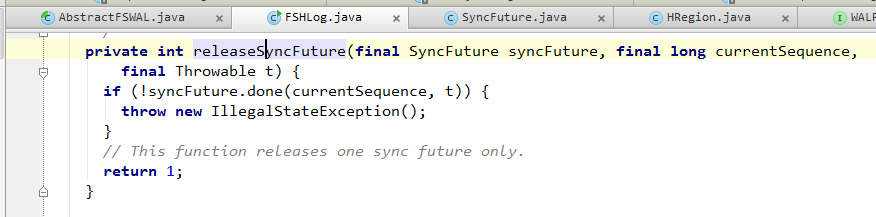
至此,整个WAL写入流程完成。
总结
我觉得对线程并发写入文件时,用队列来协调,保证日志写入的顺序,这还是比较容易想到的。
但是,提供Sync() API确保日志写入的可靠性,同时避免频繁的Sync()操作影响性能。——这是HBase WAL实现的一大亮点。
后续我再研究研究WAL的checkpoint和读取WAL回放机制,再和大家分享。