一、介绍
本例子用Selenium +phantomjs爬取今天头条视频(http://www.tvhome.com/news/)的信息,输入给定关键字抓取图片信息。
给定关键字:视频;融合;电视
二、网站信息
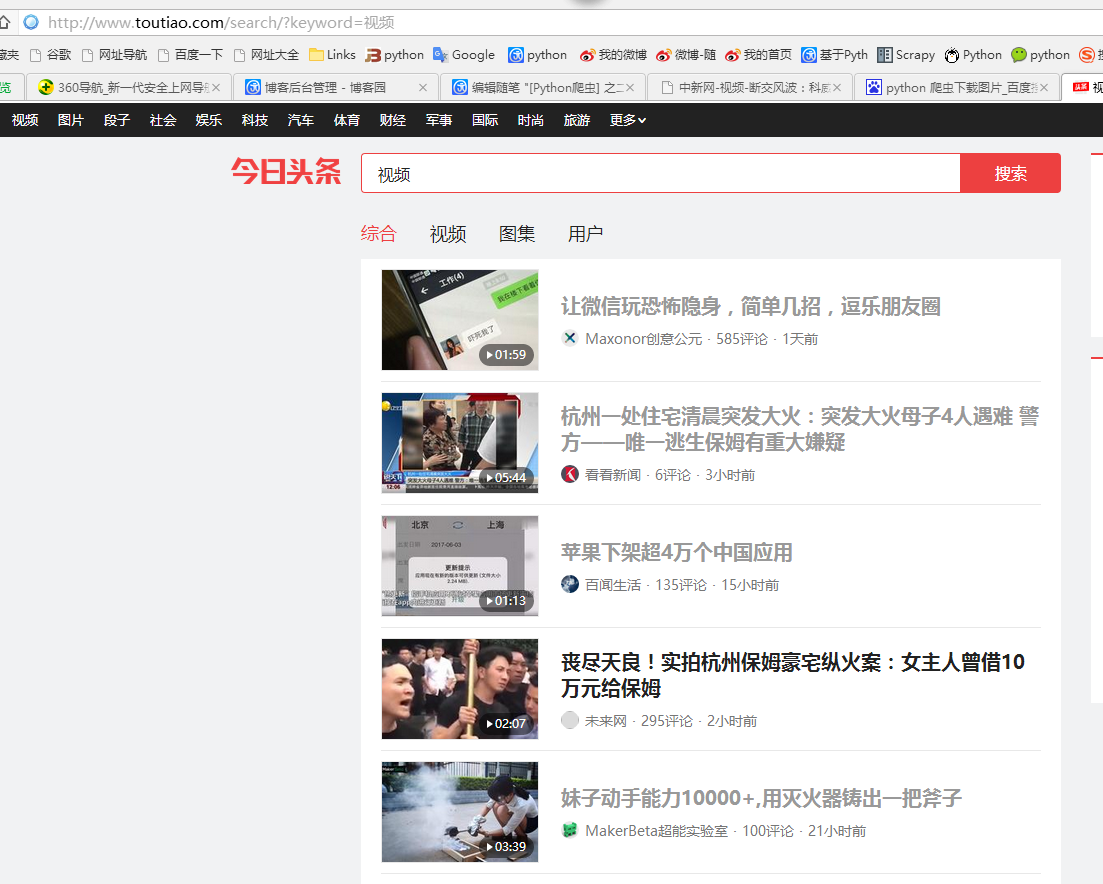
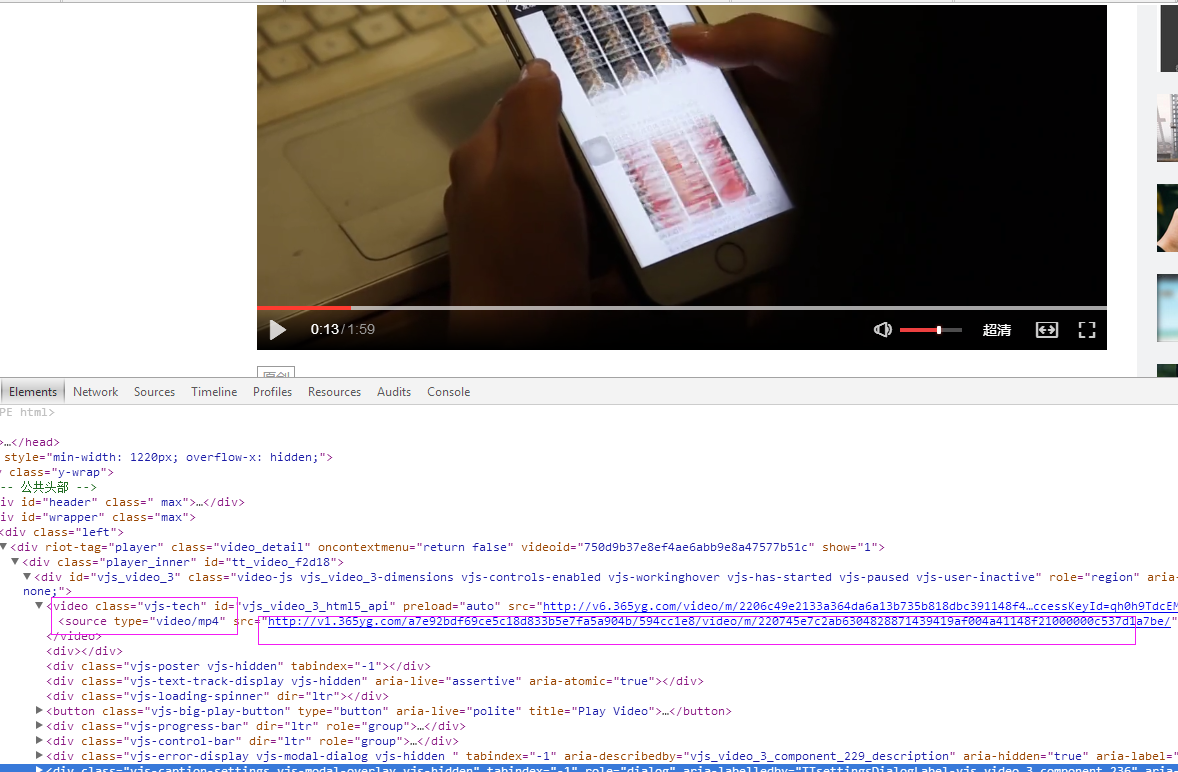
三、数据抓取
针对上面的网站信息,来进行抓取
1、首先抓取视频信息列表
抓取代码:Elements = doc('div[class="articleCard"]')
2、抓取图片
视频url:url = 'http://www.toutiao.com' + element.find('a[class="link title"]').attr('href')
videourl = dochtml('video[class="vjs-tech"]').find('source').attr('src')
四、完整代码
# coding=utf-8 import os import re from selenium import webdriver import selenium.webdriver.support.ui as ui import time from datetime import datetime import IniFile # from threading import Thread from pyquery import PyQuery as pq import LogFile import mongoDB import urllib class toutiaoSpider(object): def __init__(self): logfile = os.path.join(os.path.dirname(os.getcwd()), time.strftime('%Y-%m-%d') + '.txt') self.log = LogFile.LogFile(logfile) configfile = os.path.join(os.path.dirname(os.getcwd()), 'setting.conf') cf = IniFile.ConfigFile(configfile) webSearchUrl = cf.GetValue("toutiao", "webSearchUrl") self.keyword_list = cf.GetValue("section", "information_keywords").split(';') self.db = mongoDB.mongoDbBase() self.start_urls = [] for word in self.keyword_list: self.start_urls.append(webSearchUrl + urllib.quote(word)) self.driver = webdriver.PhantomJS() self.wait = ui.WebDriverWait(self.driver, 2) self.driver.maximize_window() def down_video(self, videourl): """ 下载视频到本地 :param videourl: 视频url """ # http://img.tvhomeimg.com/uploads/2017/06/23/144910c41de4781ccfe9435e736ef72b.jpg if len(videourl) > 0: fileName = '' if videourl.rfind('/') > 0: fileName = time.strftime('%Y%m%d%H%M%S') + '.mp4' u = urllib.urlopen(videourl) data = u.read() strpath = os.path.join(os.path.dirname(os.getcwd()), 'video') with open(os.path.join(strpath, fileName), 'wb') as f: f.write(data) def scrapy_date(self): strsplit = '------------------------------------------------------------------------------------' index = 0 for link in self.start_urls: self.driver.get(link) keyword = self.keyword_list[index] index = index + 1 time.sleep(1) #数据比较多,延迟下,否则会出现查不到数据的情况 selenium_html = self.driver.execute_script("return document.documentElement.outerHTML") doc = pq(selenium_html) infoList = [] self.log.WriteLog(strsplit) self.log_print(strsplit) Elements = doc('div[class="articleCard"]') for element in Elements.items(): url = 'http://www.toutiao.com' + element.find('a[class="link title"]').attr('href') infoList.append(url) if len(infoList)>0: for url in infoList: self.driver.get(url) htext = self.driver.execute_script("return document.documentElement.outerHTML") dochtml = pq(htext) videourl = dochtml('video[class="vjs-tech"]').find('source').attr('src') if videourl: self.down_video(videourl) self.driver.close() self.driver.quit() obj = toutiaoSpider() obj.scrapy_date()