[TOC]
教材学习内容总结
集合框架学习总结
Collection集合学习总结
集合的由来
我们学习的是面向对象语言,而面向对象语言对事物的描述是通过对象体现的,为了方便对多个对象进行操作,我们就必须把这多个对象进行存储。而要想存储多个对象,就不能是一个基本的变量,而应该是一个容器类型的变量,在我们目前所学过的知识里面,有哪些是容器类型的呢?数组和StringBuffer。但是呢?StringBuffer的结果是一个字符串,不一定满足我们的要求,所以我们只能选择数组,这就是对象数组。而对象数组又不能适应变化的需求,因为数组的长度是固定的,这个时候,为了适应变化的需求,Java就提供了集合类供我们使用。
数组和集合的区别?
长度区别:数组的长度固定、集合长度可变;
内容不同:数组存储的是同一种类型的元素、而集合可以存储不同类型的元素;
元素的数据类型问题:数组可以存储基本数据类型,也可以存储引用数据类型、集合只能存储引用类型;
集合的继承关系
|-Collection顶层接口
|-List子接口
|-ArrayList实现类
|-LinkedList实现类
|-Vector实现类
|-Set子接口
|-HashSet实现类
|-TreeSet实现类
Collection集合常用方法(略,参考JDK-API)
List集合
(1)List集合的特点
1. 元素有序:插入和取出的顺序相同;
2. 此接口的用户可以对列表中每个元素的插入位置进行精确地控制。用户可以根据元素的整数索引(在列表中的位置)访问元素,并搜索列表中的元素。;
3. 与 set 不同,列表通常允许重复的元素;
4. List 接口在 iterator、add、remove、equals 和 hashCode 方法的协定上加了一些其他约定,超过了 Collection 接口中指定的约定;
5. List 接口提供了特殊的迭代器,称为 ListIterator,除了允许 Iterator 接口提供的正常操作外,该迭代器还允许元素插入和替换,以及双向访问。还提供了一个方法来获取从列表中指定位置开始的列表迭代器。
(2)List集合特有的方法
```
void add(int index, Object element) //在指定索引处添加元素;
Object get(int index)//获取指定位置的元素;
ListIterator listIterator()//List集合特有迭代器;
Object remove(int index)//根据索引位置删除元素,返回被删除的元素;
Object set(int index, Object element)//根据索引修改元素,返回被修改的元素;
```
(3)List集合三个实现类的特点
|-ArrayList(重点):
- 底层数据结构是数组,查询快,增删慢;
- 线程不安全,但效率高;
|-Vector向量
- Vector类可以实现可增长的对象数组。与数组一样,它包含可以使用整数索引进行访问的组件。但是,Vector 的大小可以根据需要增大或缩小,以适应创建 Vector 后进行添加或移除项的操作;
- 底层数据结构是数组,查询快,增删慢;
- 线程安全,效率低;
说明:
Vector向量特有方法:
```
void add addElement(Object obj) //add()
Object elementAt(int index) //get()
Emuneration elements() //Iterator iterator()
boolean hasMoreElements() //hasNext()
Object nextElement() //next()
```
|-LinkedList(重点)
- 底层数据结构是链表,查询慢,增删快;
- 线程不安全,效率高;
说明:
LinkedList特有方法:
```
void addFirst(E e);
void addLast(E e);
E getFirst();
E getLast();
E removeFirst();
E removeLast();
```
Set集合
|--Set:无序(插入和取出顺序不一致),元素唯一;
|--HashSet
- 元素无序(插入和取出顺序不一致),唯一;
- 此类实现 Set接口,由哈希表(实际上是一个 HashMap实例)支持。它不保证 set的迭代顺序;特别是它不保证该顺序恒久不变。此类允许使用 null元素;
|--LinkedHashSet
- 元素有序(插入和取出顺序一致),唯一:由链表保证元素的有序(插入和取出的顺序是一致的)、由哈希表保证元素的唯一,即底层是哈希表+链表结构。
|--TreeSet
- 元素可排序,唯一;
- 使用元素的自然顺序对元素进行排序,或者根据创建 set时提供的 Comparator进行排序,具体取决于使用的构造方法。;
Map集合学习总结
Map集合——以键值对的方式存放数据。
例如:存取学生信息
| 键:类似set集合——key值不允许重复 | 值:类似list集合,值可重复 |
|---|---|
| 学号1 | 学生1信息 |
| 学号2 | 学生2信息 |
| 学号3 | 学生3信息 |
| 学号2(已存在,不允许重复) | 学生4信息 |
| 学号5 | 学生4信息(可重复) |
Map集合的特点
将键映射到值的对象。一个映射不能包含重复的键;每个键最多只能映射到一个值。
Map集合的继承关系
|--Map顶层接口
|--HashMap实现类
|--HashTable实现类
|--TreeMap实现类
|--LinkedHashMap实现类
|--Properties实现类
Map结合与Collection集合的区别
- Map集合存储元素是成对出现的,Map集合的键是唯一的,值是可重复的;
- Collection集合存储元素的单独出现的,Collection接口的子接口Set集合中存放的元素是唯一的,而List中存放的元素是可重复的;
注意
- Map集合的数据结构只针对键有效,跟值无关,常用实现类:HashMap,TreeMap,LinkedHashMap,HashTable,Properties等。
- Collection集合的数据结构针对元素有效:常用子接口:Set,List。
Map集合常用方法(略,参考JDK-API)
说明
(1)Map集合遍历的两种方式:
1. 根据键找值:Set<K> keySet() : 返回此映射中包含的键的 Set视图。;
2. 根据键值对对象找键和值:Set<Map.Entry<K,V>> entrySet() : 返回此映射中包含的映射关系的 Set视图;
(2)Map接口(顶层接口)常用实现类的特点
1. HashMap(最常用):线程不安全,效率高;允许null键和null值;遍历无序输出;
2. HashTable:线程安全,效率低;不允许null键和null值;遍历无序输出;
3. TreeMap:键是红黑二叉树结构,可以保证键的排序(存储和取出的顺序一致)和唯一性;线程不安全;
4. LinkedHashMap:Map接口的哈希表和链接列表实现,具有可预知的迭代顺序;线程不安全;由哈希表保证键的唯一性、由链表保证键的有序性(存储和取出的顺序一致)。
代码托管

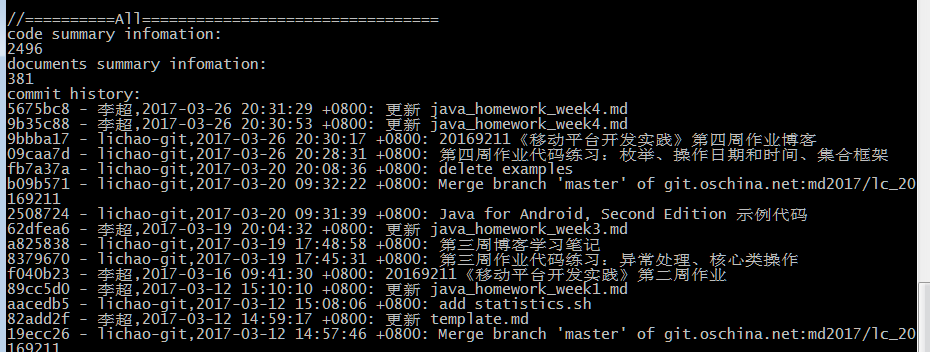
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 220/220 | 1/1 | 10/10 | |
| 第二周 | 400/620 | 1/2 | 18/28 | |
| 第三周 | 650/1120 | 1/3 | 12/40 | |
| 第四周 | 1443/2563 | 1/4 | 12/52 |
参考资料
-
[Effective.Java中文版(第2版)].布洛克;
-
[Head First Java (中文版)].塞若;
-
Java从入门到精通 第三版;
-
深入Java内存模型;
-
[Java语言程序设计-进阶篇(原书第8版)].梁勇
-
Head First设计模式(高清版);