1. App产生日志数据,发送web请求:
gmall-mock模块
//启动日志
upload{"area":"heilongjiang","uid":"2","os":"andriod","ch":"huawei","appid":"gmall","mid":"mid_71","type":"startup","vs":"1.1.2"}
//事件日志
upload{"area":"heilongjiang","uid":"2","itemid":24,"npgid":41,"evid":"clickItem","os":"andriod","pgid":32,"appid":"gmall","mid":"mid_71","type":"event"}
2. springboot接收日志落盘并发送给kafka:
gmall-logger模块--SpringBoot的部署
日志前加一个ts时间戳;org.slf4j.LoggerFactory,slf4j是一个接口,它会去找实现类;LoggeerFactory默认的会在jar包中找实现类;
logging(它是LoggeFactory默认使用的)和log4j是竞争关系,所以要在gmall-logger.pom.xml文件中加入exclusions把logging给排除了
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> <exclusions> <exclusion> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-logging</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-log4j</artifactId> <version>1.3.8.RELEASE</version> </dependency> </dependencies>
com.atguigu.gmall.logger.controller.LoggerController @RestController public class LoggerController { @Autowired KafkaTemplate kafkaTemplate; private static final Logger logger = LoggerFactory.getLogger(LoggerController.class); @PostMapping("log") public String doLog(@RequestParam("log") String log){ JSONObject jsonObject = JSON.parseObject(log); jsonObject.put("ts", System.currentTimeMillis()); //System.out.println(log); // 1. 落盘成为日志文件 // log4j logger.info(jsonObject.toJSONString()); //2. 发送kafka if ("startup".equals(jsonObject.getString("type"))){ kafkaTemplate.send(GmallConstant.KAFKA_TOPIC_STARTUP, jsonObject.toJSONString()); }else { kafkaTemplate.send(GmallConstant.KAFKA_TOPIC_EVENT, jsonObject.toJSONString()); } return "success"; } }
利用resources/ log4j.properties进行log日志的落盘:
log4j.appender.atguigu.MyConsole=org.apache.log4j.ConsoleAppender //怎么写这个日志;类型--控制台 log4j.appender.atguigu.MyConsole.target=System.err //控制台有两种:System.out日志颜色黑色和System.err日志是红色的 log4j.appender.atguigu.MyConsole.layout=org.apache.log4j.PatternLayout //自定义的,除了要打印的日志级别,还要打印什么 log4j.appender.atguigu.MyConsole.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %10p (%c:%M) - %m%n //格式,p是日志级别,%m输出的内容,%n是换行; log4j.appender.atguigu.File=org.apache.log4j.DailyRollingFileAppender //每日滚动文件,每天产生一个文件; log4j.appender.atguigu.File.file=/opt/module/applog/gmall/log/app.log //输出的文件路径,linux中的路径 log4j.appender.atguigu.File.DatePattern='.'yyyy-MM-dd //输出文件的后缀; 当天的日志是没有后缀的,一旦过了12点,就有后缀.'yyyy-MM-dd',后缀是日志时间 log4j.appender.atguigu.File.layout=org.apache.log4j.PatternLayout //自定义格式 log4j.appender.atguigu.File.layout.ConversionPattern=%m%n //要干干净净的打印信息; log4j.logger.com.atguigu.gmall.logger.controller.LoggerController=info,atguigu.File
//某一个类的路径,只监控某个类所产生的日志;log4j.rootLogger=error,atguigu.Myconsole表示根底的,除了上边指定的都是它,首先是精确匹配到info就日志输出就按照它的打印,它们后边的.File或.Myconsole都会输出
日志级别有:级别从低到高 trace、debug、info、warn、error、fatal,如果写info,从低到高比它高的都可以输出出来;
在linux中,log4j要有权限才能创建applog/gmall/log/app.log的目录,也可以提前创建好这个目录;
在linux中,非root账号,不能使用1024以下的端口号; Tomcat中 server.port=80
把日志采集模块打包部署到Linux中
在idea中的maven执行package,把打好的jar包拷贝到Linux 路径下,启动jar包:
可临时指定端口号,后台执行使用 &,控制台日志不输出使用/dev/null/ 2>&1 输入日志到黑洞 也可以输出到指定目录 >./app.err
java -jar /app/gmall/dw-logger-0.0.1-SNAPSHOT.jar --server.port=8080 >/dev/null 2>&1 &
测试 由windows发送日志数据(gmall-mock/ JsonMocker类)到linux 日志落盘
在三台系统同时部署日志采集系统的jar包,分别把/applog/目录拷贝到三台虚拟机上
java -jar /opt/module/applog/gmall/gmall-logger-0.0.1-SNAPSHOT.jar --server.port=8080 >./app.error 2>&1 &
[kris@hadoop101 log]$ tail -10f app.log //监控文件测试数据是否写入
3. 搭建nginx
https://www.cnblogs.com/shengyang17/p/10836168.html ,只需一台部署nginx即可;
由windows发送模拟日志,nginx负责路由,日志服务负责接收。
window发送日志------>>niginx路由---> linux中接收日志的jar存储日志文件并发给kafka--->kafka
更新集群启动脚本 ,加入nginx操作: ./logger-cluster.sh start 启动nginx路由,路由三台虚拟机给接收日志服务的jar包 ,并发给fakfa;
logger-cluster.sh


[kris@hadoop101 gmall]$ vim logger-cluster.sh #!/bin/bash JAVA_BIN=/opt/module/jdk1.8.0_144/bin/java PROJECT=gmall APPNAME=gmall-logger-0.0.1-SNAPSHOT.jar SERVER_PORT=8080 case $1 in "start"){ for i in hadoop101 hadoop102 hadoop103 do echo "========启动日志服务: $i===============" ssh $i "$JAVA_BIN -Xms32m -Xmx64m -jar /opt/module/applog/$PROJECT/$APPNAME --server.port=$SERVER_PORT >./app.error 2>&1 &" done echo "==============启动NGINX===============" /opt/module/nginx/sbin/nginx };; "stop"){ echo "=============关闭NGINX=================" /opt/module/nginx/sbin/nginx -s stop for i in hadoop101 hadoop102 hadoop103 do echo "========关闭日志服务: $i===============" ssh $i "ps -ef|grep $APPNAME |grep -v grep|awk '{print $2}'|xargs kill" >/dev/null 2>&1 done };; esac
ssh之间的互相连接:三种联通方式: ①source /etc/profile; ②ssh 会读.bashrc cat /etc/profile>>.brashrc ③$JAVA_BIN
netstart -anp | more 查看端口
当前日志模块:

4. 日活DAU
搭建实时处理模块gmall-realtime:
消费kafka;利用redis过滤当日已经计入的日活设备;把每批次新增的当日日活信息保存到ES中;从ES中查出数据,发布成数据接口
消费kafka& 利用redis去重
1、把今日新增的活跃用户保存到redis中; 2、每条数据经过过滤,去掉redis中的已有的用户
设计Redis的kv; Key:dau:2019-01-22, value: 设备id
业务类开发
DauApp.scala 消费kafka中数据(通过MyKafkaUtil获取) --->>利用redis去重---->>保存到ES(通过MyEsUtil工具类)中;
object DauApp { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setAppName("gmall").setMaster("local[*]") val streamingContext: StreamingContext = new StreamingContext(new SparkContext(conf),Seconds(5)) val inputStream: InputDStream[ConsumerRecord[String, String]] = MyKafkaUtil.getKafkaStream(GmallConstant.KAFKA_TOPIC_STARTUP, streamingContext) // 1 把当日已访问过的用户保存起来 redis // 2 以当日已访问用户清单为依据 ,过滤掉再次访问的请求 // 转换case class 补全日期格式 val startupLogDStream: DStream[StartUpLog] = inputStream.map { record => val jsonStr: String = record.value() val startUpLog: StartUpLog = JSON.parseObject(jsonStr, classOf[StartUpLog]) //把日期进行补全 val dateTimeString: String = new SimpleDateFormat("yyyy-MM-dd HH:mm").format(new Date(startUpLog.ts)) val dateTimeArray: Array[String] = dateTimeString.split(" ") startUpLog.logDate = dateTimeArray(0) startUpLog.logHour = dateTimeArray(1).split(":")(0) startUpLog.logHourMinute = dateTimeArray(1) startUpLog } // 去重操作 val filterDStream: DStream[StartUpLog] = startupLogDStream.transform { rdd => //driver 每时间间隔执行一次 println("过滤前:" + rdd.count()) val jedis: Jedis = RedisUtil.getJedisClient val curDate: String = new SimpleDateFormat("yyyy-MM-dd").format(new Date()) val key: String = "dau:" + curDate val dauSet: util.Set[String] = jedis.smembers(key) //当日日活用户清单 //使用广播变量 val dauBC: Broadcast[util.Set[String]] = streamingContext.sparkContext.broadcast(dauSet) val filterRDD: RDD[StartUpLog] = rdd.filter { startuplog => !dauBC.value.contains(startuplog.mid) } println("过滤后:" + filterRDD.count()) filterRDD } // 考虑到 新的访问可能会出现重复 ,所以以mid为key进行去重,每个mid为小组 每组取其中一个 val startupLogGroupDStream: DStream[(String, Iterable[StartUpLog])] = filterDStream.map{startuplog => (startuplog.mid, startuplog)}.groupByKey() val startupLogFilterDistinctDStream: DStream[StartUpLog] = startupLogGroupDStream.flatMap { case (mid, startupLogIter) => val startupLogOneIter: Iterable[StartUpLog] = startupLogIter.take(1) startupLogOneIter } // 1 把当日已访问过的用户保存到 redis startupLogFilterDistinctDStream.foreachRDD{rdd => rdd.foreachPartition{startupLogItr => val jedis: Jedis = RedisUtil.getJedisClient val startupList: List[StartUpLog] = startupLogItr.toList for (elem <- startupList) { val key: String = "dau:" + elem.logDate jedis.sadd(key, elem.mid) } jedis.close() //保存到ES MyEsUtil.insertEsBatch(GmallConstant.ES_INDEX_DAU, startupList) } } streamingContext.start() streamingContext.awaitTermination() } }
4. ES
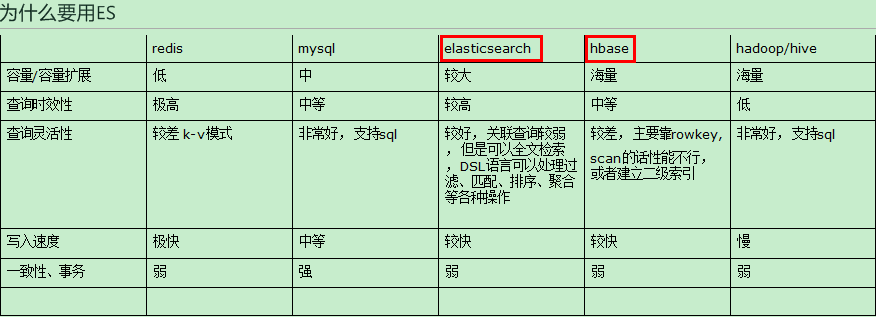
综上 ,在实际环境中,需要一种能够容纳较大规模数据切交互性好的数据库。mysql虽然交互性好,但是容量扩展性有限。
hbase虽然能够支持海量数据,但是查询的灵活度不足。所以ES在容量及交互性上达到一个非常不错的平衡,而且还能支持全文检索。
搭建es集群 https://www.cnblogs.com/shengyang17/p/10597841.html
ES& kibana的启动脚本: ./ek.sh start
[kris@hadoop101 gmall]$ cat ek.sh #!/bin/bash es_home=/opt/module/elasticsearch kibana_home=/opt/module/kibana/ case $1 in "start"){ echo "=============启动ES集群=============" for i in hadoop101 hadoop102 hadoop103 do ssh $i "source /etc/profile;${es_home}/bin/elasticsearch >/dev/null 2>&1 &" done echo "=============启动kibana=============" nohup ${kibana_home}/bin/kibana >/opt/module/kibana/kibana.log 2>&1 & };; "stop"){ echo "=============关闭kibana=============" ps -ef | grep ${kibana_home} | grep -v grep | awk '{print $2}'|xargs kill echo "=============关闭ES集群=============" for i in hadoop101 hadoop102 hadoop103 do ssh $i "ps -ef | grep $es_home | grep -v grep | awk '{print $2}'|xargs kill" >/dev/null 2>&1 done };; esac
设计es索引结构
case class startup
case class Startup(mid:String, uid:String, appid:String, area:String, os:String, ch:String, logType:String, vs:String, var logDate:String, var logHour:String, var logHourMinute:String, var ts:Long ) { }
text 支持分词; keyword 只能全部内容匹配
保存数据之前一定要先定义好mapping: 每个字段的类型 ; 分清楚索引类型
1、需要索引 也需要分词:标题,商品名称,分类名称, type:“text”
2、需要索引,但不需要分词:类型id , 日期,数量 ,年龄 ,各种id, type:"keyword";
mid, uid,area,os ,ch ,vs,logDate,logHourMinute,ts
3、既不需要索引,也不需要分词: 不被会用于条件过滤,经过脱敏的字段,138****0101 index:false
##############在ES中创建index PUT gmall_dau { "mappings": { "_doc":{ "properties":{ "mid":{ "type":"keyword" , }, "uid":{ "type":"keyword" }, "area":{ "type":"keyword" }, "os":{ "type":"keyword" }, "ch":{ "type":"keyword" }, "vs":{ "type":"keyword" }, "logDate":{ "type":"keyword" }, "logHour":{ "type":"keyword" }, "logHourMinute":{ "type":"keyword" }, "ts":{ "type":"long" } } } } }
在Kibana中进行查询
如果在在保存| 插入数据的时候,没有先建立mapping的数据结构,则ES是会自动推断;当你再去聚合aggs时,text的字段是不能进行聚合的(如果想要聚合要加 字段.keyword,如下所示),但是好一点的是ES给保存了两份,一个是text类型的字段、另外一个是keyword类型的;浪费了空间,在实际生产环境中是不能使用这种方式的;
GET /gmall_dau/_search { "query": { "bool": { "filter": { "term": { "logDate": "2019-05-04" } } } } } ######groupby操作 聚合aggregation GET /gmall_dau/_search { "query": { "bool": { "filter": { "term": { "logDate": "2019-04-30" } } } }, "aggs": { "groupby_logHour": { "terms": { "field": "logHour.keyword", "size": 24 } } } }
保存到es中; 关于es java客户端的选择,目前市面上有两类客户端:
一类是TransportClient 为代表的ES原生客户端,不能执行原生dsl语句必须使用它的Java api方法。
另外一种是以Rest Api为主的missing client,最典型的就是jest。 这种客户端可以直接使用dsl语句拼成的字符串,直接传给服务端,然后返回json字符串再解析。
两种方式各有优劣,但是最近elasticsearch官网,宣布计划在7.0以后的版本中废除TransportClient。以RestClient为主。
所以在官方的RestClient 基础上,进行了简单包装的Jest客户端,就成了首选,而且该客户端也与springboot完美集成。
5. 数据发布接口
详细见代码
通过gmall-mock模块的类JsonMocker发送数据--->nginx路由--->三台虚拟机的gmall-logger的接收数据并转发给kafka(用的是SpringBoot)--->
启动:gmall-publisher--springBoot的主类: com.atguigu.gmall.publisher.GmallPublisherApplication,给chart的接口,启动
启动:gmall--dw-chart---com.demo.DemoApplication的主类; 接接口展示数据的动态变化
启动:[kris@hadoop101 ~]$ redis-server myredis/redis.conf
启动:gmall-realtime的com.atguigu.gmall.realtime.app.DauApp类,
启动:gmall-mock模块的类JsonMocker发送数据
http://127.0.0.1:8070/realtime-total?date=2019-04-30
[{"name":"新增日活","id":"dau","value":761},{"name":"新增设备","id":"new_mid","value":233}]
http://127.0.0.1:8070/realtime-hour?id=dau&&date=2019-05-04
{"yesterday":{},"today":{"20":26,"21":96}}
通过前端页面展示: http://localhost:8089/index