为什么bs虚函数表的地址(int*)(&bs)与虚函数地址(int*)*(int*)(&bs) 不是同一个?
链接:https://www.zhihu.com/question/27459122/answer/36736246
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
题主的问题在 《Inside the C++ Object Model》 里有完美解答。这本书必读。
另外放个相关问题的例子的传送门:一道阿里实习生笔试题的疑惑? - RednaxelaFX 的回答
C++规范并没有规定虚函数的实现方式。不过大部分C++实现都用虚函数表(vtable)来实现虚函数的分派。特别是对单继承的情况,大家的实现都比较接近;对多继承的情况可能需要多层虚函数表,这个大家有不少发挥空间。
下面给个单继承情况下常见C++实现的布局的例子。
(代码用了C++11的语法,不影响内容)#include <string>
#include <iostream>
class Object {
int identity_hash_;
public:
Object(): identity_hash_(std::rand()) { }
int IdentityHashCode() const { return identity_hash_; }
virtual int HashCode() { return IdentityHashCode(); }
virtual bool Equals(Object* rhs) { return this == rhs; }
virtual std::string ToString() { return "Object"; }
};
class MyObject : public Object {
int dummy_;
public:
int HashCode() override { return 0; }
std::string ToString() override { return "MyObject"; }
};
int main() {
Object o1;
MyObject o2;
std::cout << o2.ToString() << std::endl
<< o2.IdentityHashCode() << std::endl
<< o2.HashCode() << std::endl;
}
/*
Object vtable
-16 [ offset to top ] __si_class_type_info
-8 [ typeinfo Object ] --> +0 [ ... ]
--> +0 [ vptr ] --> +0 [ &Object::HashCode ]
+8 [ identity_hash_ ] +8 [ &Object::Equals ]
+12 [ (padding) ] +16 [ &Object::ToString ]
MyObject vtable
-16 [ offset to top ] __si_class_type_info
-8 [ typeinfo MyObject ] --> +0 [ ... ]
--> +0 [ vptr ] --> +0 [ &MyObject::HashCode ]
+8 [ identity_hash_ ] +8 [ &Object::Equals ]
+12 [ dummy_ ] +16 [ &MyObject::ToString ]
*/
这个布局是在64位(LP64)的Mac OS X上Clang++用的。我没有禁用RTTI,所以在vtable的开头还有一个隐藏字段存着类型的typeinfo指针。C++的RTTI虽然毕竟弱,但好歹也算是一种反射的实现;每个编译器会自己实现藏在std::type_info背后的反射用数据结构。
“offset-to-top”在多继承的情况下有用,不过编译器为了方便实现也可以在单继承的时候用同样的结构,把值填为0就不影响语义了。
例如:
- 对象的vptr是位于对象的+0偏移量,还是位于别的(例如负偏移量,-8之类)
- vtable里是否存在typeinfo。如果关掉RTTI功能的话就没特别的必要存typeinfo了。
- 如果vtable里有存typeinfo,它位于什么偏移量,是+0还是别的(例如负偏移量,-8之类)
- 还有一个很微妙的:一般C++实现vtable里放发是虚函数的入口地址,该地址直接可调用;但也不排除奇葩实现从vtable项出发要再经过几层间接才能访问到真正的入口地址…这种做法在C++实现中不常见,但在VM实现中却挺常见的。下面再举例说。
在多继承和虚拟继承的情况下虚函数表要如何组织就有趣了…这里不想展开,题主请读《Inside the C++ Object Model》吧。
对象内有多个vptr、使用多层vtable是常见做法;有些实现把这种多层vtable叫做VTT(vtable table)。
===============================================================
GCC的文档写道:https://gcc.gnu.org/onlinedocs/gcc/Compatibility.htmlMost platforms have a well-defined ABI that covers C code, but ABIs that cover C++ functionality are not yet common.
Starting with GCC 3.2, GCC binary conventions for C++ are based on a written, vendor-neutral C++ ABI that was designed to be specific to 64-bit Itanium but also includes generic specifications that apply to any platform. This C++ ABI is also implemented by other compiler vendors on some platforms, notably GNU/Linux and BSD systems. We have tried hard to provide a stable ABI that will be compatible with future GCC releases, but it is possible that we will encounter problems that make this difficult. Such problems could include different interpretations of the C++ ABI by different vendors, bugs in the ABI, or bugs in the implementation of the ABI in different compilers. GCC's -Wabi switch warns when G++ generates code that is probably not compatible with the C++ ABI.
Clang也同样在Linux和BSD系系统(包括Mac OS X的Darwin)实现Itanium C++ ABI,而在Windows上为了跟MSVC兼容实现MSVC C++ ABI。
那么这个Itanium C++ ABI到底是怎样的?这里有一份文档草案:Itanium C++ ABI
其中这段描述了非POD类的实例的布局:2.4 Non-POD Class Types
而这段描述了vtable的局部,包括多继承情况下的布局:2.5 Virtual Table Layout
只要把这篇文档读了就可以知道GCC和Clang的C++ ABI。足够解答题主的疑问。
===============================================================
MSVC的C++ ABI我不知道有啥特别详细的文档。有时候好奇会去看Clang所实现的MSVC C++ ABI是怎样的;Clang的开发者们肯定对这此有很多逆向经验了。
===============================================================
顺带一提一些JVM以及CLR对单继承虚方法的实现。
基于类的面向对象、类在运行时结构不可变、类继承只有单继承、虚函数只能单分派的编程语言里,利用vtable实现虚函数/虚方法分派是很常见的技巧(不过不一定是首选技巧)。
有些同学可能被忽悠过说Java啊C#之类的没有虚函数表。实际上高性能的JVM和CLR实现都还是有用虚函数表来实现虚方法分派。毕竟主要是单继承的类体系。
(也确实存在完全不使用vtable的JVM实现。通常这种是特别纠结空间开销的JVM,例如为低端嵌入式设备设计的JVM。这些略奇葩嗯。)
HotSpot VM:(以JDK8的、64位、不开压缩指针为例)
instanceOopDesc
--> +0 [ _mark ] InstanceKlass
+8 [ _klass ] --> +0 [ ... ]
+16 [ ... fields ... ] +8 [ ... ]
... [ ... ]
+n [ vtable[0] ]
+n+8 [ vtable[1] ]
... [ vtable... ]
+m [ itable[0] ]
+m+8 [ itable[1] ]
... [ itable... ]
对象的头16字节是“对象头”,对象头的第二个字段是跟vptr等价的一个指针,指向InstanceKlass。
InstanceKlass的开头是一大堆固定长度的元数据,主要记录该类型的反射相关的信息;末尾包含该类型的vtable和itable(接口虚方法表)。具体结构这里就不说了,有兴趣的同学欢迎另外开问题。
可以看到,HotSpot VM使用了vtable来实现单继承虚方法分派,但是对应vptr的字段并不在对象的+0偏移量而在+4(32位)或+8(64位)偏移量上;对应vtable的数据结构也不在InstanceKlass的+0偏移量开始,而是在一大块定长的数据之后挂在末尾。
HotSpot VM里,只有虚方法(非private的实例方法)会出现在vtable里;非虚方法(静态方法或private实例方法)则不会出现在vtable里。
HotSpot VM的itable(Interface Table)跟C++一些实现的VTT思路相似,也是多层vtable。毕竟要解决的问题一样——多继承的虚方法分派。
HotSpot VM的vtable项不是指向“可调用的方法入口的指针”,而是一个Method*。Method对象含有Java方法的元数据,其中一个字段才是真正的“可调用的方法入口”。所以说HotSpot VM的vtable虽然作用跟C++类似,但访问的间接层比C++要多一层。
CLR:(以32位CLRv2在x86上为例)
Object
-4 [ m_SyncBlockValue ] MethodTable
--> +0 [ m_pMethTab ] --> +0 [ ... ]
+4 [ ... fields ... ] +4 [ ... ]
... [ ... ] EEClass
+n [ m_pEEClass ] --> [ ... ]
... [ ... ]
+m [ m_pDispatchMap ]
+m+4 [ vtable[0] ]
+m+8 [ vtable[1] ]
... [ vtable... ]
+x [ dispatchmap[0] ]
... [ dispatchmap... ]
CLRv2这种对象布局方式跟前面提到的C++的例子非常相似。
对象的+0偏移量上存着跟vptr等价的类型指针,指向MethodTable。
MethodTable里主要存着一些涉及代码执行、分派还有GC所需的数据;这些数据通常比较热。它的开头是一块定长的数据,末尾挂着可变长的vtable和DispatchMap(相当于itable)。
EEClass存着类型的反射相关元数据;这些数据相对MethodTable里的相对来说比较冷,所以把类型数据分离为两个对象。EEClass对应到前面C++的例子就是typeinfo,只不过前者包含的反射信息远多于后者。
CLRv2的MethodTable + EEClass的作用等于HotSpot VM的InstanceKlass。
相比HotSpot VM,CLRv2的MethodTable稍微更纯粹一些,更接近C++那种vtable,而把跟执行关系不大的、反射相关的元数据挪到一个单独的对象里。
MethodTable内嵌的vtable可以看作两部分:前半部分跟C++的常见实现类似,按顺序排列虚方法;后半部分则排列着该类型所定义的非虚方法。也就是说一个类型所定义的所有方法都会在对应的MethodTable的vtable里出现,但只有前半部分参与虚方法分派。
MethodTable里的vtable项跟C++的类似,是方法的“可调用方法入口”。
JIT编译过的方法就会有真正可调用的方法入口;但在CLRv2上,除非一个方法有被NGen或者是native方法,不然它得等到第一次被调用的时候才会被JIT编译。某个方法在被JIT编译前,其对应的MethodTable的vtable项会是一个pre-JIT stub,用于实现“JIT编译的触发”。
请参考另一个回答:什么是桩代码(Stub)? - RednaxelaFX 的回答
CLRv4里对象布局有细微变化。
Sun Classic VM:(以32位Sun JDK 1.0.2在x86上为例)
HObject ClassObject
-4 [ hdr ]
--> +0 [ obj ] --> +0 [ ... fields ... ]
+4 [ methods ]
methodtable ClassClass
> +0 [ classdescriptor ] --> +0 [ ... ]
+4 [ vtable[0] ] methodblock
+8 [ vtable[1] ] --> +0 [ ... ]
... [ vtable... ]
这是一种使用“句柄”(handle)的对象模型。Java的引用实现为指向handle的指针,通过handle进一步访问对象的实例字段或虚方法表。除了handle和GC的实现外,所有对Java对象的访问都必须通过handle这个间接层,而不能使用直接指向对象实例的指针。对象的字段内容存储在ClassObject类型的结构体里。
上图中的HObject是对java.lang.Object及大部分其它类实例的handle;数组实例和少量特殊类的实例有特殊的handle实现,这里不展开讲。
所有实例方法都会出现在methodtable的vtable里。
ClassObject的对象头hdr主要用于存储这个ClassObject的大小,便于实现GC堆的前向线性遍历。
这种做法下,handle是固定大小的,而包含对象实例字段的ClassObject是可变长的。两者被分配在不同的区域:handle区与对象区。Handle区不会碎片化,因为所有handle都一样大;这样对handle的自动内存管理只需要用mark-sweep而不需要移动这些handle,那么handle的地址就是固定的,指向它的指针也就是稳定的。
反之,对象区里的对象不一定一样大,有可能在长时间运行、反复分配和释放内存之后出现碎片化,所以需要偶尔做compaction来消除碎片化,于是对象就有可能移动。
优点:
通过固定地址的handle去指向可变地址的对象实例数据,这个额外的间接层允许Sun Classic VM实现保守式的mark-sweep/compact GC,也就是说就算不能精确知道哪些数据是Java对象的引用,也可以安全地移动对象。这是一种相当偷懒的做法。
缺点:
显然,相比使用直接指针,这种使用handle的做法多了一个间接层。它的效率实在不太好,无论是空间效率(handle占用了额外的空间)还是时间效率(访问对象字段和虚方法分派等操作)都比使用直接指针的做法差。
具体到Sun Classic VM的handle的具体设计,有趣的一点是它把methodtable的指针放在handle里而不是跟对象实例数据放在一起。这样的“fat handle”设计至少执行效率上比只包含对象实例指针的handle要快一些——前者访问虚方法表用两次间接:handle->methods->vtable[index];后者则要三次间接:handle->obj->methods->vtable[index]。
有趣的是采用这种布局的还不只有这个Sun Classic VM,还有:
- DVM_ObjectRef 参考1:ポリモルフィズム 参考2:Diksamのポリモルフィズム
- <TODO> 回头继续追加
值得一提的是,CLR的对象模型追根溯源可以追到这个Sun Classic VM上。
微软从Sun获得了Java的授权,并通过授权得到了Sun JDK 1.0.x的源码,以此为基础开发了MSJVM。
MSJVM为了改善性能,把Sun Classic VM的HObject和ClassObject合并回到一起,改用直接指针实现Java对象的引用。对象模型被改造成了这样:
Object
-4 [ sync block index ] methodtable ClassClass
--> +0 [ methods ] --> +0 [ class desc ] --> +0 [ ... ]
+4 [ ... fields ... ] +4 [ vtable[0] ]
+8 [ vtable[1] ]
... [ vtable... ]
是不是看起来跟前面的CLRv2的对象模型看起来非常相似了?
这个历史的一些片段请参考另一个问题的回答:微软当年的 J++ 究竟是什么?为什么 Sun 要告它? - RednaxelaFX 的回答
JRockit VM:(以32位JRockit R28在x86上为例)
JRockit x86
Object ClassBlock Class
--> +0 [ Class block ] --> +0 [ clazz ] --> +0 [ ... ]
+4 [ Lock word ] +4 [ ... ]
+8 [ ... fields ... ] ... [ ... ]
+n [ vtable[0] ]
《Oracle JRockit: The Definitive Guide》第4章第124页提到了JRockit里的对象布局。
乍一看这跟前面提到的几个例子很相似。所谓“Class block”指针跟C++的vptr作用类似,而且位于+0偏移量上。
实际上JRockit的ClassBlock里包含的vtable/itable设计有许多精妙的地方,采用了双向布局,其itable实现了constant time lookup。可惜没有任何公开文档描述它,所以这里也没办法展开讲。
JRockit VM:(以32位JRockit R28在SPARC上为例)
Object
--> +0 [ Lock word ] ClassBlock Class
+4 [ Class block ] --> +0 [ clazz ] --> +0 [ ... ]
+8 [ ... fields ... ] +4 [ ... ]
... [ ... ]
+n [ vtable[0] ]
上面提到JRockit的vtable/itable设计没有公开文档详细描述,那这里为啥要举这个例子?
因为JRockit在SPARC上实现的对象头跟在x86上的顺序相反,挺有趣的。这演示了就算是同一个名字的VM,在不同平台或者说不同条件下也可能有不同的实现。
SPARC上的JRockit的“Class block”字段就不是对象头的第一个字段,而是第二个。
无独有偶,类似的差异设计在Maxine VM里也存在:Objects - Maxine VM
Sable VM
SableVM是由加拿大的McGill大学研发的研究性JVM。它实现了许多有趣的概念。
这里相关的两个概念是:双向对象布局(bidirectional object layout)和稀疏接口方法分派表(sparse interface method dispatch table)。
Sable VM的双向对象布局把所有引用类型字段放在对象头的一侧,而把原始类型字段放在对象头的另一侧。像这样的感觉:
_svmt_object_instance_struct
-8 [ ... reference field ... ]
-4 [ reference field 0 ]
--> +0 [ lockword ] _svmt_vtable _svmt_type_info
+4 [ vtable ] --> +0 [ type ] --> +0 [ ... ]
+8 [ non-reference field 0 ] +4 [ ... ]
+12 [ ... non-reference field ... ]
引用类型的字段全部在相对于对象头的负偏移量上,而非引用类型(原始类型)字段则全部在正偏移量上。这样,在实现类继承的时候,可以保证以下两点同时满足:
- 在同一个继承链上,同一个字段总是在同一个偏移量上
- 所有引用类型字段都在连续的内存块里
于是GC扫描对象中的引用时就可以很高效地扫描连续的内存块。
上图更直观。传统设计可能如下:
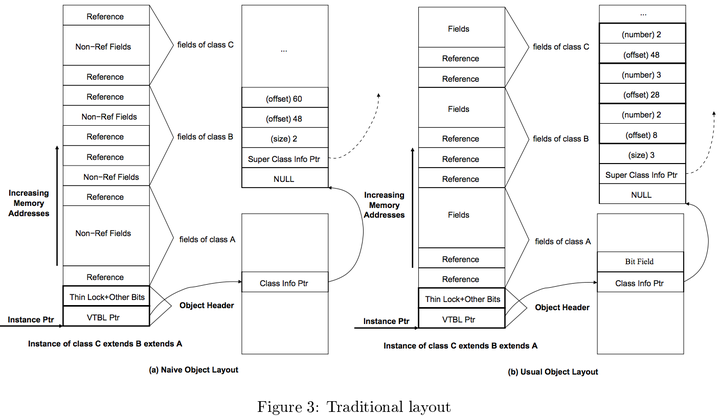
而Sable VM的双向对象布局则是:
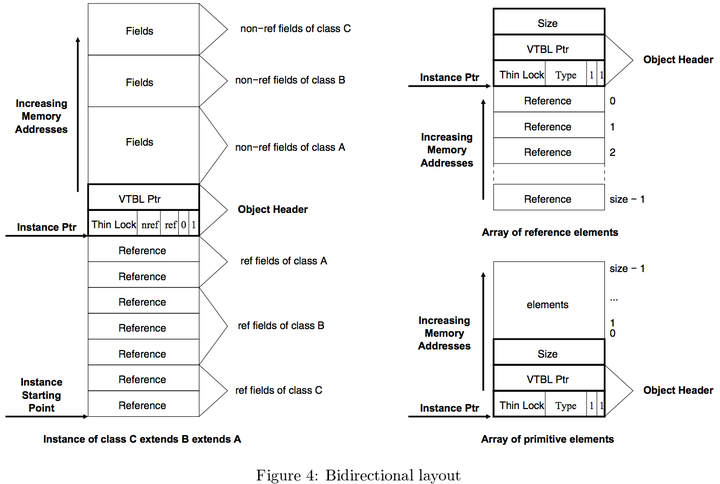
(图片引用自 SableVM: A Research Framework for the Efficient Execution of Java Bytecode)
Sable VM的vtable设计也很精妙。跟对象布局相似也采用双向布局,正向(正偏移量)上放的是跟C++实现类似的vtable,而负偏移量上放的是稀疏的接口方法分派表,如图:
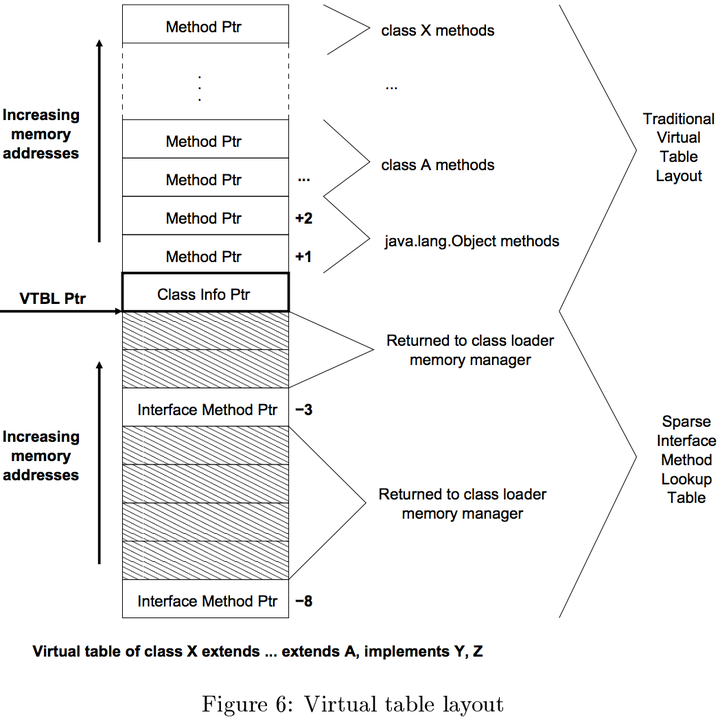 (图片引用自 SableVM: A Research Framework for the Efficient Execution of Java Bytecode )
先写这么多。
(图片引用自 SableVM: A Research Framework for the Efficient Execution of Java Bytecode )
先写这么多。