https://www.bilibili.com/video/av16378934?from=search&seid=9658415144190341605
numpy.random模块 https://blog.csdn.net/fireflychh/article/details/73603838
pandas && numpy
1. 属性以及创建矩阵
import numpy as np
array = np.array([[1,2,3],
[2,3,4]]) #建立一个矩阵(注意'[]'的数量)
print(array)
print('number of dim', array.ndim) #矩阵的维数
print('shape', array.shape) #矩阵的形状
print('size', array.size) #矩阵的大小,数据个数
a = np.array([2,23,4], dtype=np.int) ##int32,32位int @1
a1 = np.zeros((3,4), dtype=np.int32) #3行4列的全为0, 32位int类型数据
a2 = np.ones((3,4), dtype=np.int32) #3行4列的全为1, 32位int类型数据
a3 = np.arange(10, 20, 2) #生成从10到20(取不到20)的步长为2的数列
a4 = np.arange(12).reshape((3,4)) #生成从0到11的,3行4列的矩阵
a5 = np.linspace(1, 10, 5) #生成线段,生成从1到10一共5段线段
# Out[13]: array([ 1. , 3.25, 5.5 , 7.75, 10. ])
2. 基础运算
import numpy as np
a = np.array([10,20,30,40])
b = np.arange(4) #[0,1,2,3]
c = a - b #减法
d = a + b #加法
e = a * b #乘法注意不是矩阵乘法
f = b**2 #次方
g = 10*np.sin(a) #sin与cos用法一样
print(b < 3) #[ True True True False]
a1 = np.array([[1,1],
[0,1]])
b1 = np.arange(4).reshape((2,2))
c1 = a1 * b1 #逐个相乘 array([[0, 1],
# [0, 3]])
c1_dot = np.dot(a1, b1) ##矩阵乘法 array([[2, 4],
# [2, 3]])
c1_dot_2 = a.dot(b) ##另一种写法 个人觉得可读性较差
a3 =
a2 = np.random.random((2,4))#array([[0.41322246, 0.70201529, 0.3669404 , 0.24802252],
#[0.3022681 , 0.89514217, 0.63173225, 0.57511299]])
x = np.sum(a2, axis=1) #求和,axis=1表示以取行元素操作列, axis=0表示以列取元素操作行,Out[24]: array([1.73020067, 2.4042555 ])
x1 = np.min(a2, axis=0) #最小值 array([0.3022681 , 0.70201529, 0.3669404 , 0.24802252])
x2 = np.max(a2, axis=1) #最大值array([0.70201529, 0.89514217])
import numpy as np
a = np.arange(2, 14).reshape((3,4))
print(np.argmin(a)) ##最小值的索引位置 0
print(np.argmax(a)) ##最大值的索引位置 11
print('平均值',np.mean(a)) ##平均值 或者 a.mean()
print(np.average(a)) ##平均值
print('中位数',np.median(a)) ##中位数 7.5
print('累加',np.cumsum(a)) ##累加依次相邻两个数之和 [ 2 5 9 14 20 27 35 44 54 65 77 90]
print('累差',np.diff(a)) ##相邻两个数之间的差值
#累差 [[1 1 1]
#[1 1 1]
#[1 1 1]]
print('输出非零数据的行数和列数',np.nonzero(a))
#行数:(array([0, 0, 0, 0, 1, 1, 1, 1, 2, 2, 2, 2], dtype=int64),
#列数: array([0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3], dtype=int64))
print('转置',np.transpose(a)) ##矩阵转置
print('类似二值化',np.clip(a, 5, 9)) ##类似二值化 小于5的数变成5,大于9的数变成9
#[[5 5 5 5]
# [6 7 8 9]
# [9 9 9 9]] 如果数据相反就只有大于5的变5而不是小于9的变9
a1 = np.array([[1,4,2,7],
[3,1,5,8],
[8,3,5,6]])
print("排序", np.sort(a1)) ##注意逐行排序
# [[1 2 4 7]
# [1 3 5 8]
# [3 5 6 8]]
3.numpy的索引
import numpy as np
a = np.arange(3,15).reshape((3,4))
##如果是数列的话直接a[n]
print(a[2]) ##输出第二行所以数据
print('等同于',a[2, :])
print(a[2][2]) ##输出第二行第二列
print(a[2, 1:3])##第二行第一列到第二列
##迭代行
for raw in a:
print(raw)
##迭代列
for column in a.T: ##a.T 相当于 np.transpose(a) a的转置
print(column)
##迭代项
print('将矩阵转换成一行的序列', a.flatten()) ## 返回序列[ 3 4 5 6 7 8 9 10 11 12 13 14]
for item in a.flat: ##flat() 返回的是一个生成序列的迭代器
print(item)
4.numpy 合并
import numpy as np
a = np.array([1,1,1])
b = np.array([2,2,2])
print('上下的合并',np.vstack((a,b,c))) ## 注意需要括号将合并的数据括起来
#[[1 1 1]
# [2 2 2]]
print('左右合并',np.hstack((a,b,c))) ##[1 1 1 2 2 2]
##注意transpose无法将序列转换为列
#需要如下操作
a1 = np.array([1,1,1])[:,np.newaxis] #或者reshape(n,1)也可以
a2 = np.array([2,2,2])[:,np.newaxis]
print(np.hstack((a1,a2)))
#[[1 2]
# [1 2]
# [1 2]]
print('总的合并方法(在newaxis方法下)',np.concatenate((a1,a2),axis=1)) ##(在newaxis方法下)才能使用,1行0列
就newaxis方法进行如下解释
首先newaxis作用是增加维度
详解:np.newaxis在[]中第几位,a.shape的第几维就变成1,a的原来的维度依次往后排。
例子:若a.shape=(a ,b, c)
a[:, np.newaxis].shape= (a, 1, b, c)
a[:, np.newaxis, np.newaxis].shape= (a, 1, 1, b, c)
a[np.newaxis, :].shape= (1, a, b, c)
a[np.newaxis, np.newaxis, :].shape= (1, 1, a, b, c)
a[np.newaxis, :, np.newaxis].shape= (1, a, 1, b, c)
a[np.newaxis, :, np.newaxis, :].shape= (1, a, 1, b, c)
a[:, :,np.newaxis].shape= (a, b,1, c)
另外
np.newaxis=None
a[np.newaxis, :, np.newaxis, :].shape == a[None,:,None,:]
如下是具体例子:
import numpy as np
a = np.array([1,1,1])
a1 = a[:,np.newaxis]
b = np.array([2,2,2])
b1 = b[np.newaxis,:]
print(a.shape, a)
print(a1.shape)
print(a1)
print(b.shape, b)
print(b1.shape)
print(b1)
结果
(3,) [1 1 1]
(3, 1)
[[1]
[1]
[1]]
(3,) [2 2 2]
(1, 3)
[[2 2 2]]
c = np.array([[1,1,1],[2,2,2]]) c1 = c[:,np.newaxis] d = np.array([[2,2,2],[3,3,3]]) d1 = d[np.newaxis,:] print(c.shape) print(c) print(c1.shape) print(c1) print(d.shape) print(d) print(d1.shape) print(d1)
结果
(2, 3)
[[1 1 1]
[2 2 2]]
(2, 1, 3)
[[[1 1 1]]
[[2 2 2]]]
(2, 3)
[[2 2 2]
[3 3 3]]
(1, 2, 3)
[[[2 2 2]
[3 3 3]]]
5.numpy的array分割
import numpy as np
a = np.arange(12).reshape((3,4))
print(a)
##没有整除会报ValueError
print(np.split(a, 2, axis=1)) ##将a按照列数平均分成两份,每取一行分成两半
print(np.split(a, 3, axis=0)) ##将a按照行数平均分成3分,每取一列分成3分
#[array([[0, 1, 2, 3]]), array([[4, 5, 6, 7]]), array([[ 8, 9, 10, 11]])]
##不等量分割
print(np.array_split(a,2,axis=0))
#[array([[0, 1, 2, 3],
# [4, 5, 6, 7]]), array([[ 8, 9, 10, 11]])]
print(np.array_split(a,[1,3],axis=1))##按照第一份分0列,第二份分1,2列,第三份分第3列([]相当于切片,索引)
print('上下分割也就是按照行分割',np.vsplit(a,3))
print('左右分割也就是按照列数分割',np.hsplit(a,2))
6. nump的copy以及deep_copy
In [1]: import numpy as np
In [2]: a = np.arange(4)
In [3]: b = a
In [4]: a
Out[4]: array([0, 1, 2, 3])
In [5]: b
Out[5]: array([0, 1, 2, 3])
In [6]: a[0] = 11
In [7]: a
Out[7]: array([11, 1, 2, 3])
In [8]: b
Out[8]: array([11, 1, 2, 3])
In [9]: b is a
Out[9]: True
In [10]: b[1:3] = [22,33]
In [11]: b
Out[11]: array([11, 22, 33, 3])
In [12]: a
Out[12]: array([11, 22, 33, 3])
In [13]: c = a.copy() ##deep_copy
In [14]: a[3] = 44
In [15]: a
Out[15]: array([11, 22, 33, 44])
In [16]: c
Out[16]: array([11, 22, 33, 3])
pandas
1. 基本介绍
import numpy as np
import pandas as pd
s = pd.Series([1,3,6,np.nan,44,1]) ##列表,会自动加序号
print('产生列表',s)
dates = pd.date_range('20200206',periods=6)
##产生日期,periods表示生成的个数
#DatetimeIndex(['2020-02-06', '2020-02-07', '2020-02-08', '2020-02-09',
# '2020-02-10', '2020-02-11'],
# dtype='datetime64[ns]', freq='D')
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=['a','b','r','t'])
## 其中randn之后会讲到, index表示行的名称,column表示列的名称
# a b r t
#2020-02-06 -0.661183 0.586394 0.867207 0.234598
#2020-02-07 2.050175 0.962423 0.412010 1.479072
#2020-02-08 1.132787 1.256786 -0.234434 -0.860920
#2020-02-09 -0.118119 1.201684 -1.485074 0.460520
#2020-02-10 -0.040067 -0.871771 -0.720332 0.055199
#2020-02-11 -0.165296 -1.925641 0.002060 0.701225
df1 = pd.DataFrame(np.arange(12).reshape((3,4)))
##默认名称就是0-n-1的数字
# 0 1 2 3
#0 0 1 2 3
#1 4 5 6 7
#2 8 9 10 11
data = pd.Series(np.random.randn(1000),index=np.arange(1000))
data = data.cumsum()#元素累加和,也是1000个数据
#字典的表示方法
df2 = pd.DataFrame({'A':[1.,2.,3.,4.],
'B':pd.date_range('20200206',periods=4),
'C':pd.Series(np.arange(4)),
'D':pd.Categorical(['test','train','train','tets']),
'E':'foo'})
# A B C D E
#0 1.0 2020-02-06 0 test foo
#1 2.0 2020-02-07 1 train foo
#2 3.0 2020-02-08 2 train foo
#3 4.0 2020-02-09 3 tets foo
print('打印数据类型',df2.dtypes)
print('打印列序号的名字',df2.columns)#打印列序号的名字 Index(['A', 'B', 'C', 'D', 'E'], dtype='object')
print('打印每个数据',df2.values)
print(df2.describe())
print('转置',df2.T)
print('排序',df2.sort_index(axis=1, ascending=False))
##倒序排序,按照行取值 ascend上升
print('按照某列数据排序', df2.sort_values(by='C', ascending=False))
##按照'C'列数据进行排序
2. 数据选择
import pandas as pdi
import numpy as np
dates = pd.date_range('20200206', periods=6)
df = pd.DataFrame(np.arange(24).reshape((6,4)), index=dates, columns=['A','B','C','D'])
方法1
df.A 与 df['A']一样
df[0:3], df['20200206':'20200208]
方法2
select by label:loc
df.loc['20200207']
df.loc['20200207',['A','B']]
方法3
select by position: iloc
df.iloc[1,1]
df.iloc[[1,3,5],1:3]
方法4
Boolean indexing:
df[df.A>8]
3. 设置值
import pandas as pd
import numpy as np
dates = pd.date_range('20200206', periods=6)
df = pd.DataFrame(np.arange(24).reshape((6,4)), index=dates, columns=['A','B','C','D'])
#改变值
df.iloc[2,2] = 111
df.loc['20200207','B'] = 222
df[df.A > 4] = 0
df.B[df.A > 4] = 0
df['E'] = np.nan ##nan无穷大
df['F'] = pd.Series(np.arange(6), index=dates)
4. 处理丢失数据
import pandas as pd
import numpy as np
dates = pd.date_range('20200206', periods=6)
df = pd.DataFrame(np.arange(24).reshape((6,4)), index=dates, columns=['A','B','C','D'])
df.iloc[0,1] = np.nan
df.iloc[1,2] = np.nan
df.dropna(axis=0, how='any')
# axis=0按照行取数据删掉列
# how={'any', 'all'} any表示出现nan就删掉,all表示全部一行或者一列是nan删掉
df.fillna(value=0)#将nan数据填入数据0
df.isnull() #判断是否有丢失的数据
# A B C D
#2020-02-06 False True False False
#2020-02-07 False False True False
#2020-02-08 False False False False
#2020-02-09 False False False False
#2020-02-10 False False False False
#2020-02-11 False False False Fals
np.any(df.isnull()) == True ##检查是否有值丢失
5.导入导出数据
读取

保存

data = pd.read_csv('C:/Users/XXXX/Pictures/untitled3/student.csv')
print(data)
data.to_pickle('C:/Users/XXXX/Desktop/studstudent.pickle')
6.合并
1.concat方法
import pandas as pd
import numpy as np
df1 = pd.DataFrame(np.ones((3,4))*0, columns=['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4))*1, columns=['a','b','c','d'])
df3 = pd.DataFrame(np.ones((3,4))*2, columns=['a','b','c','d'])
##concatenation
res = pd.concat([df1, df2, df3], axis=1, ignore_index=True)
#0上下合并,1左右合并
#ignore_index=True 表示忽略行列的名称
df1 = pd.DataFrame(np.ones((3,4))*0, columns=['a','b','c','d'], index=[1,2,3])
df2 = pd.DataFrame(np.ones((3,4))*1, columns=['b','c','d','e'], index=[2,3,4])
res1 = pd.concat([df1,df2], join='inner',ignore_index=True)
res2 = pd.concat([df1, df2], join='outer',ignore_index=True)
##默认是outer,如果名字大小不一样全用NaN填充
#inner则不同的数据全部裁剪掉
print(res1)
print(res2)
#结果
b c d
0 0.0 0.0 0.0
1 0.0 0.0 0.0
2 0.0 0.0 0.0
3 1.0 1.0 1.0
4 1.0 1.0 1.0
5 1.0 1.0 1.0
a b c d e
0 0.0 0.0 0.0 0.0 NaN
1 0.0 0.0 0.0 0.0 NaN
2 0.0 0.0 0.0 0.0 NaN
3 NaN 1.0 1.0 1.0 1.0
4 NaN 1.0 1.0 1.0 1.0
5 NaN 1.0 1.0 1.0 1.0
res = pd.concat([df1,df2], axis=1, join_axes=[df1.index])
#join_axes表示只考虑df1.index中行名称(删掉了4)
a b c d b c d e
1 0.0 0.0 0.0 0.0 NaN NaN NaN NaN
2 0.0 0.0 0.0 0.0 1.0 1.0 1.0 1.0
3 0.0 0.0 0.0 0.0 1.0 1.0 1.0 1.0
2. append方法
res = df1.append([df2,df3], ignore_index=True)
3. merge方法
import pandas as pd
import numpy as np
left = pd.DataFrame({'key':['K0','K1','K2','K3'],
'A':['A0','A1','A2','A3'],
'B':['B0','B1','B2','B3']})
right = pd.DataFrame({'key':['K0','K1','K2','K3'],
'A':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3']})
res = pd.merge(left, right, on='key') #基于'key'的合并
A_x B key A_y D
0 A0 B0 K0 C0 D0
1 A1 B1 K1 C1 D1
2 A2 B2 K2 C2 D2
3 A3 B3 K3 C3 D3
res = pd.merge(left, right,on='key', suffixes=['_boy', '_girl'], how='outer')
##suffixes在相同的index后加上后缀
A_boy B key A_girl D
0 A0 B0 K0 C0 D0
1 A1 B1 K1 C1 D1
2 A2 B2 K2 C2 D2
3 A3 B3 K3 C3 D3
left = pd.DataFrame({'key1':['K0','K0','K1','K2'],
'key2':['K0','K1','K0','K1'],
'A':['A0','A1','A2','A3'],
'B':['B0','B1','B2','B3']})
right = pd.DataFrame({'key1':['K0','K1','K1','K2'],
'key2':['K0','K0','K0','K0'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3']})
res = pd.merge(left, right, on=['key1', 'key2'],how='outer',indicator=True)
#how=['innner', 'outer', 'left', 'right'] 默认inner
#innner ,outer类似上述
#left,right基于左边还是右边的key来进行合并
#indicator显示是否两者都有,默认Flase
A B key1 key2 C D _merge
0 A0 B0 K0 K0 C0 D0 both
1 A1 B1 K0 K1 NaN NaN left_only
2 A2 B2 K1 K0 C1 D1 both
3 A2 B2 K1 K0 C2 D2 both
4 A3 B3 K2 K1 NaN NaN left_only
5 NaN NaN K2 K0 C3 D3 right_only
res = pd.merge(left, right, left_index=True, right_index=True, how='outer')
#left_index,right_index=True表示用左边右边的index进行合并
A B key1_x key2_x C D key1_y key2_y
0 A0 B0 K0 K0 C0 D0 K0 K0
1 A1 B1 K0 K1 C1 D1 K1 K0
2 A2 B2 K1 K0 C2 D2 K1 K0
3 A3 B3 K2 K1 C3 D3 K2 K0
7.画图(部分)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
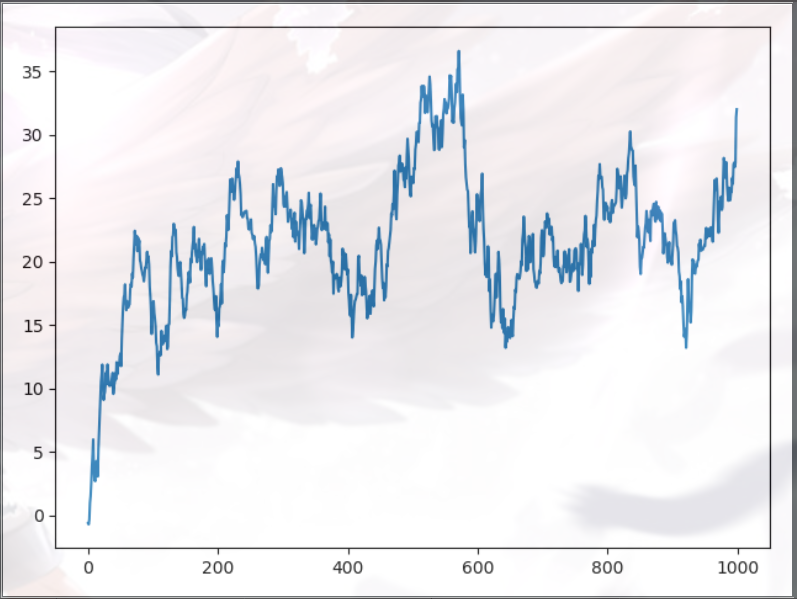
data = pd.Series(np.random.randn(1000),index=np.arange(1000))
data = data.cumsum()
data.plot()
plt.show()
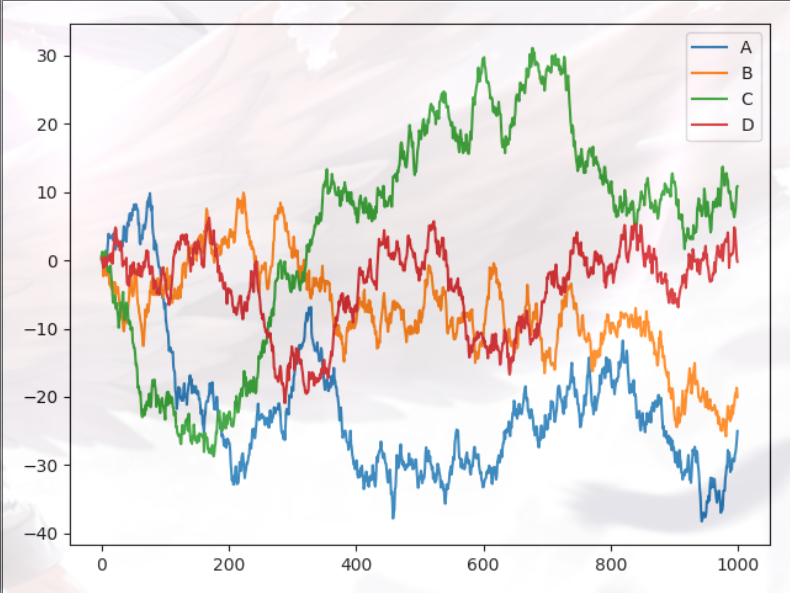
data = pd.DataFrame(np.random.randn(1000,4), columns=list('ABCD'))
data = data.cumsum()
data.plot()
plt.show()
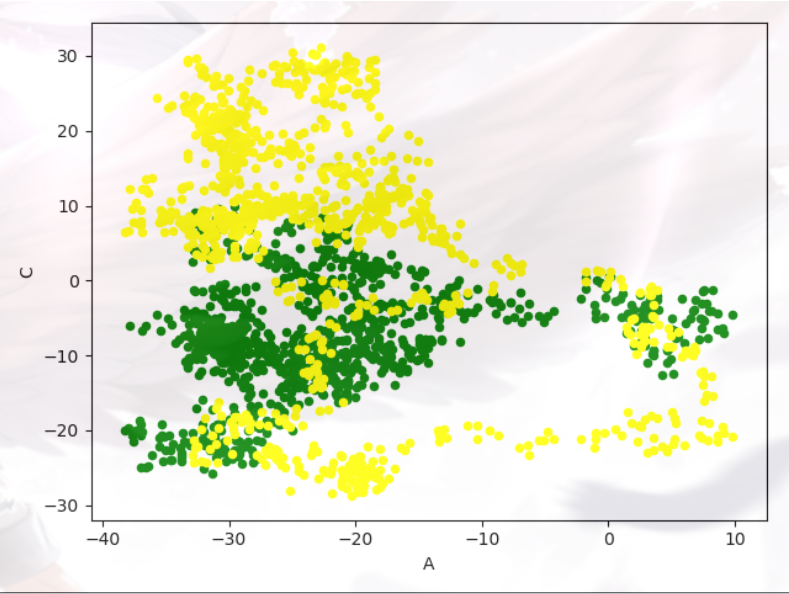
a = data.plot.scatter(x='A', y='B', color='Green')
data.plot.scatter(x='A',y='C', color='Yellow',ax = a)#ax=a将两副图画在一起
plt.show()