网络输入是一个序列,一句话,图像的某一行,都可以认为是一个序列,
网络输出的也是一个序列。
RNN的架构
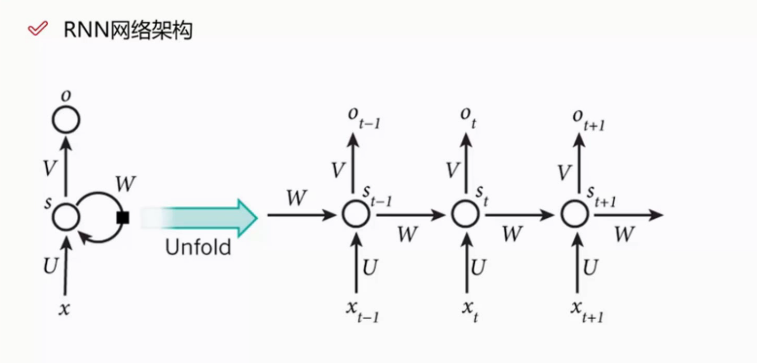
我们把所有的输出o连起来,就成了一个序列。
rnn有一些缺点,lstm可以加入一个遗忘单元,然后控制哪些需要记住,哪些需要忘记。
机器翻译:

现在的机器翻译已经达到了非常高的水平。最早的时候,就是逐字翻译。
逐字翻译不准确,而且不连贯,现在已经被淘汰了。
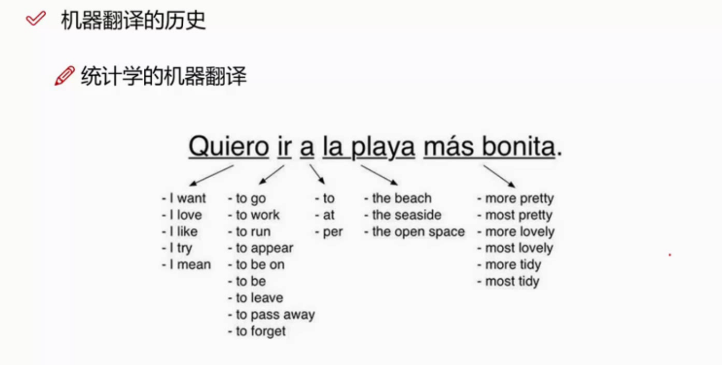
然后使用统计学,使用转移矩阵,选择最可能的转接方式,可以做的不错,但依然有问题。
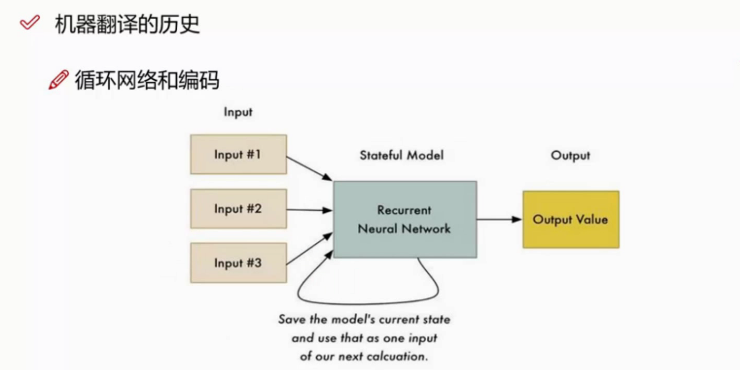
现在我们使用的是循环神经网络。
首先我们进行RNN编码,就是把输入的句子转成一个向量(比如300维),然后通过另一个RNN进行解码,得到最后的结果。
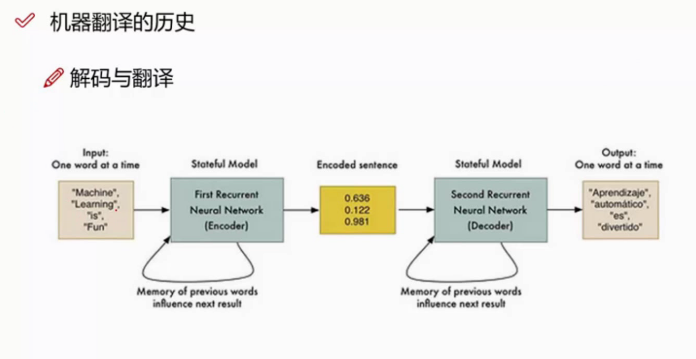
seq2seq网络架构
左边输入:are you free tomorrow?
右边输出:yes, what's up?
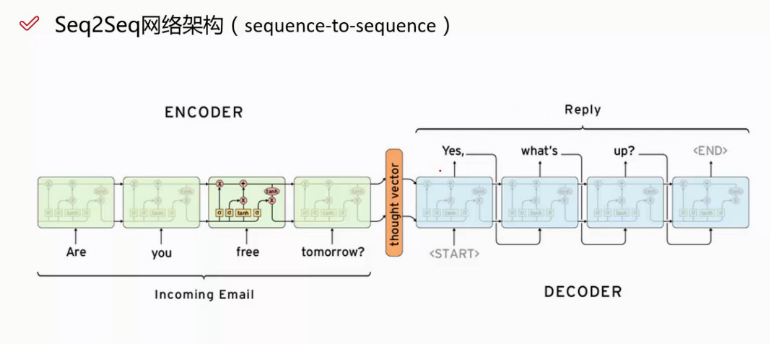
END或者用EDS表示最终的结束字符。因为我们要防止它无限制的解码下去,我们需要一个终止字符。
这样的网络架构可以构造一个聊天机器人的。但是这样的对话数据不好找。
文本摘要

S表示输入数据。
T表示文本摘要。
S的序列不一样长,我们可以采用补全的方式,让他们一样的输出长度。
rnn输入字符是不认识的,我们一般是使用word2vec进行映射操作的。
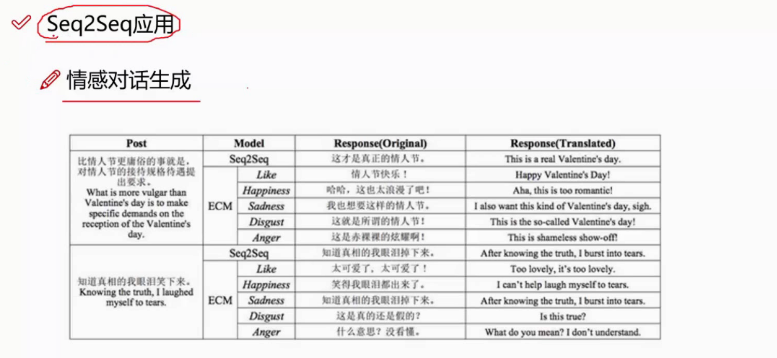
seq2seq存在的问题:
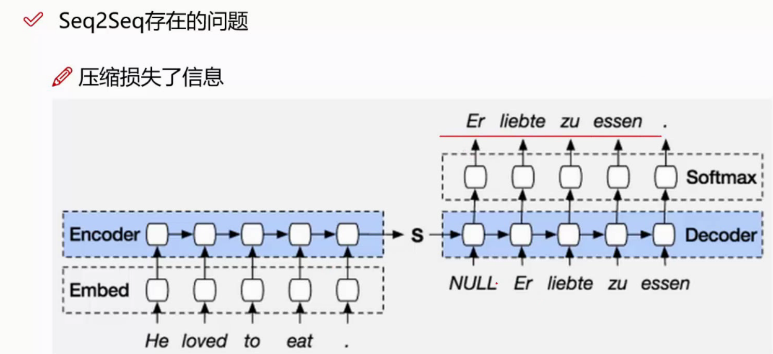
压缩损失了信息,因为在进行编码的过程中,最后一个词可能占比比较大一些,因为编码过程损失了信息,所以会导致在解码的过程中,得不到损失的那些信息。这是seq2seq中比较严重的缺点。
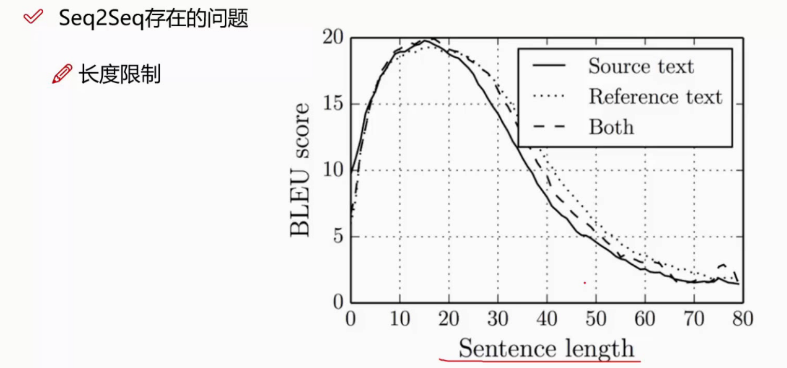
序列长度一般10-20左右最好的。
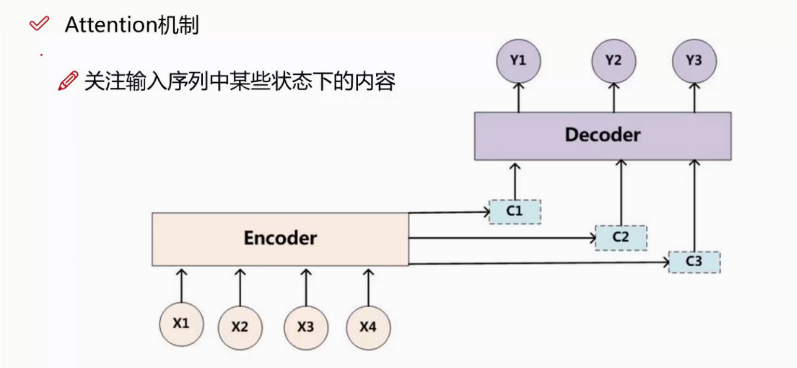
解决办法:加入attentation机制。

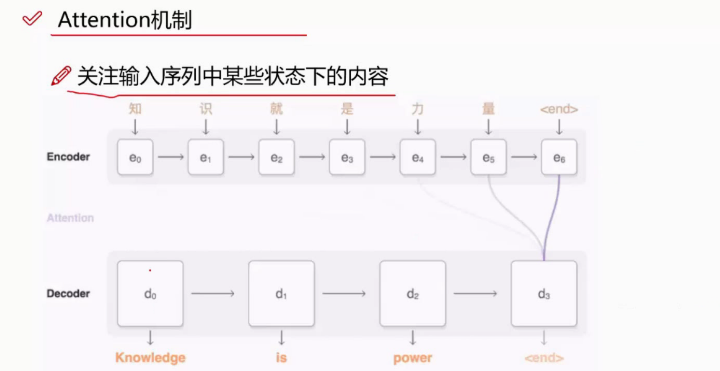
我们认为knowledge就是和知识有关,和后边的几个词关系不大,或者说,我们可以引入一个概率分布,让它知道这个词和哪些输入的关系大一些。
举例子:
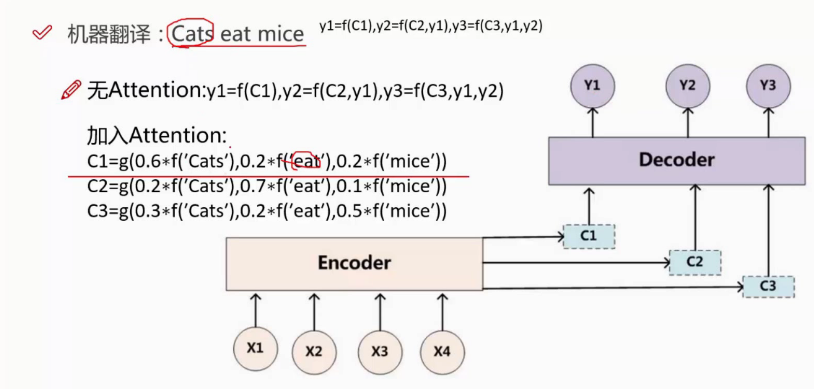
加入了attentation机制,然后改变了C的结果。从论文中可以看到,加入attentation机制之后,效果变好。
attentation实际上是做了一个加权的工作。
Bucket机制
每次mini—batch都是固定大小。我们可以分组,然后保证内部一致就可以了。