目录
1 引言
1.2 读者范围
2 综述
3 代码详细分析
3.1 启动Hadoop集群
3.2 JobTracker启动以及Job的初始化
3.3 TaskTracker启动以及发送Heartbeat
3.4 JobTracker接收Heartbeat并向TaskTracker分配任务
3.5 TaskTracker接收HeartbeatResponse
3.6 MapReduce任务的运行
3.6.1 MapTask的运行
3.6.2 ReduceTask的运行
4 致谢
1 引言
1.1 目的
该文档从源代码的级别剖析了Hadoop0.20.2版本的MapReduce模块的运行原理和流程,对JobTracker、 TaskTracker的内部结构和交互流程做了详细介绍。系统地分析了Map程序和Reduce程序运行的原理。读者在阅读之后会对Hadoop MapReduce0.20.2版本源代码有一个大致的认识。
1.2 读者范围
如果读者想只是想从原理上更加深入了解Hadoop MapReduce运行机制的话,只需要阅读第2章综述即可,该章节要求读者对HadoopMapReduce模型有系统的了解。
如果读者想深入了解HadoopMapReduce的源代码,则需阅读该文档第2、3节。阅读第3节需要读者熟练掌握Java语言的基本语法,并且对反射机制、动态代理有一定的了解。同时,还要求读者对于Hadoop HDFS和Hadoop RPC的基本用法有一定的了解。
另外,熟悉Hadoop源代码的最好方法是远程调试,有关远程调试的方法请读者去网上自行查阅资料。
2 综述
Hadoop源代码分为三大模块:MapReduce、HDFS和Hadoop Common。其中MapReduce模块主要实现了MapReduce模型的相关功能;HDFS模块主要实现了HDFS的相关功能;而Hadoop Common主要实现了一些基础功能,比如说RPC、网络通信等。
在用户使用HadoopMapReduce模型进行并行计算时,用户只需要写好Map函数、Reduce函数,之后调用JobClient将Job 提交即可。在JobTracker收到提交的Job之后,便会对Job进行一系列的配置,然后交给TaskTracker进行执行。执行完毕之后,JobTracker会通知JobClient任务完成,并将结果存入HDFS中。
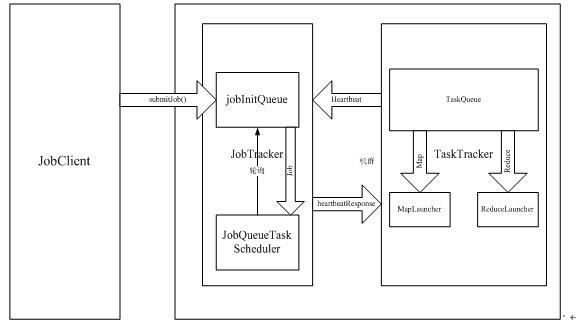
如图所示,用户提交Job是通过JobClient类的submitJob()函数实现的。在Hadoop源代码中,一个被提交了的Job由 JobInProgress类的一个实例表示。该类封装了表示Job的各种信息,以及Job所需要执行的各种动作。在调用submitJob()函数之后,JobTracker会将作业加入到一个队列中去,这个队列的名字叫做jobInitQueue。然后,在JobTracker中,有一个名为 JobQueueTaskScheduler的对象,会不断轮询jobInitQueue队列,一旦发现有新的Job加入,便将其取出,然后将其初始化。
在Hadoop代码中,一个Task由一个TaskInProgress类的实例表示。该类封装了描述Task所需的各种信息以及Task执行的各种动作。
TaskTracker自从启动以后,会每隔一段时间向JobTracker发送消息,消息的名称为“Heartbeat”。Heartbeat中包含了该TaskTracker当前的状态以及对Task的请求。JobTracker在收到Heartbeat之后,会检查该heartbeat的里所包含的各种信息,如果发现错误会启动相应的错误处理程序。如果TaskTracker在Heartbeat中添加了对Task的请求,则 JobTracker会添加相应的指令在对Heartbeat的回复中。在Hadoop源代码中,JobTracker对TaskTracker的指令称为action,JobTracker对TaskTracker所发送来的Heartbeat的回复消息称为HeartbeatResponse。
在TaskTracker内部,有一个队列叫做TaskQueue。该中包含了所有新加入的Task(Task包括Map Task,和Reduce Task)。每当TaskTracker收到 HeartbeatResponse后,会对其进行检查,如果其中包含了新的Task,便将其加入到TaskQueue中。在TaskTracker内部,有两个线程不断轮询TaskQueue,一个是MapLauncher,另一个是ReduceLauncher。如果发现有新加入的Map任务,MapLauncher便将其取出并且执行。如果是Reduce任务,ReduceLauncher便将其取出执行。
不论是Map Task还是Reduce Task,当他们被取出之后,都要进行本地化。本地化的意思就是将所有需要的信息,比如需要运行的jar文件、配置文件、输入数据等等,一起拷贝到本地的文件系统。这样做的目的是为了方便任务在某台机器上独立执行。本地化之后,TaskTracker会为每一个task单独创建一个jvm,然后单独运行。等Task运行完之后,TaskTracker会通知JobTracker任务完成,以进行下一步的动作。
等到所有的Task都完成之后,Job也就完成了,此时JobTracker会通知JobClient工作完成。
3 代码详细分析
下面从用户使用Hadoop进行MapReduce计算的过程为线索,详细介绍Task执行的细节,并对Hadoop MapReduce的主要代码进行分析。
3.1 启动Hadoop集群
Hadoop集群的启动是通过在Master上运行start-all.sh脚本进行的。运行该脚本之后,Hadoop会配置一系列的环境变量以及其他Hadoop运行所需要的参数,然后在本机(Master)运行JobTracker和NameNode。然后通过SSH登录到所有slave机器上,启动 TaskTracker和DataNode。
因为本文只介绍Hadoop MapReduce模块,所以NameNode和DataNode的相关知识不再介绍。
3.2 JobTracker启动以及Job的初始化
org.apache.hadoop.mapred.JobTracker类实现了Hadoop MapReduce模型的JobTracker的功能,主要负责任务的接受,初始化,调度以及对TaskTracker的监控。
JobTracker单独作为一个JVM运行,main函数就是启动JobTracker的入口函数。在main函数中,有以下两行非常重要的代码:
startTracker(new JobConf());
JobTracker.offerService();
startTracker函数是一个静态函数,它调用JobTracker的构造函数生成一个JobTracker类的实例,名为result。然后,进行了一系列初始化活动,包括启动RPC server,启动内置的jetty服务器,检查是否需要重启JobTracker等。
在JobTracker.offerService()中,调用了taskScheduler对象的start()方法。该对象是 JobTracker的一个数据成员,类型为TaskScheduler。该类型提供了一系列接口,使得JobTracker可以对所有提交的job进行初始化以及调度。但是该类型实际上是一个抽象类型,其真正的实现类型为JobQueueTaskScheduler类,所以,taskScheduler.start()方法执行的是JobQueueTaskScheduler类的start方法。
该方法的详细代码如下:
public synchronized void start() throwsIOException { //调用TaskScheduler.start()方法,实际上没有做任何事情 super.start(); //注册一个JobInProgressListerner监听器 taskTrackerManager.addJobInProgressListener(jobQueueJobInProgressListener); eagerTaskInitializationListener.setTaskTrackerManager(taskTrackerManager); eagerTaskInitializationListener.start(); taskTrackerManager.addJobInProgressListener(eagerTaskInitializationListener)
}
JobQueueTaskScheduler类的start方法主要注册了两个非常重要的监听 器:jobQueueJobInProgressListener和eagerTaskInitializationListener。前者是 JobQueueJobInProgressListener类的一个实例,该类以先进先出(内部实现的就是串行)的方式维持一个JobInProgress的队列,并且监听各 个JobInProgress实例在生命周期中的变化;后者是EagerTaskInitializationListener类的一个实例,该类不断监听jobInitQueue,一旦发现有新的job被提交(即有新的JobInProgress实例被加入),则立即调用该实例(JobInProgress实例)的initTasks方法,对job进行初始化。
JobInProgress类的initTasks方法的主要代码如下:
/**这是一个异步调用的线程,使得分片计算不阻塞任何线程*/ public synchronized void initTasks() throwsIOException { …… //读取输入分片,从HDFS中读取job.split文件,并为每个Map创建一个分片 String jobFile = profile.getJobFile(); Path sysDir = newPath(this.jobtracker.getSystemDir()); FileSystem fs = sysDir.getFileSystem(conf); DataInputStream splitFile = fs.open(newPath(conf.get("mapred.job.split.file")));//默认为job.split JobClient.RawSplit[] splits; try { splits = JobClient.readSplitFile(splitFile);//读取输入分片文件job.split } finally { splitFile.close(); }
………………
//map task的个数就是input splits的个数 numMapTasks = splits.length; //为每个map tasks生成一个TaskInProgress来处理一个input split maps = newTaskInProgress[numMapTasks]; for(inti=0; i < numMapTasks; ++i) { inputLength += splits[i].getDataLength(); maps[i] =new TaskInProgress(jobId, jobFile, splits[i],jobtracker, conf, this, i); } /* 对于map task,将其放入nonRunningMapCache,是一个Map<Node, List<TaskInProgress>>,也即对于map task来讲,其将会被分配到其input split所在的Node上。在此,Node代表一个datanode或者机架或者数据中 心。nonRunningMapCache将在JobTracker向TaskTracker分配map task的 时候使用。 */ if(numMapTasks > 0) { nonRunningMapCache = createCache(splits,maxLevel); } //创建reduce task this.reduces = new TaskInProgress[numReduceTasks]; for (int i= 0; i < numReduceTasks; i++) { reduces[i]= new TaskInProgress(jobId, jobFile, numMapTasks, i,jobtracker, conf, this); /*reducetask放入nonRunningReduces,其将在JobTracker向TaskTracker 分配reduce task的时候使用。*/ nonRunningReduces.add(reduces[i]); } //创建两个cleanup task,一个用来清理map,一个用来清理reduce. cleanup =new TaskInProgress[2]; // 清理map提示. 此map不使用任何分片. 仅仅分配空的分片.
JobClient.RawSplit emptySplit = new JobClient.RawSplit();
cleanup[0] = new TaskInProgress(jobId, jobFile, emptySplit, jobtracker, conf, this, numMapTasks); cleanup[0].setJobCleanupTask(); // 清理reduce提示 cleanup[1]= new TaskInProgress(jobId, jobFile, numMapTasks, numReduceTasks, jobtracker, conf, this); cleanup[1].setJobCleanupTask(); //创建两个初始化 task,一个初始化map,一个初始化reduce. setup =new TaskInProgress[2]; setup[0] =new TaskInProgress(jobId, jobFile, splits[0],jobtracker,conf, this, numMapTasks + 1 ); setup[0].setJobSetupTask(); setup[1] =new TaskInProgress(jobId, jobFile, numMapTasks, numReduceTasks + 1, jobtracker, conf, this); setup[1].setJobSetupTask(); tasksInited.set(true);//初始化完毕 …… }
3.3 TaskTracker启动以及发送Heartbeat
org.apache.hadoop.mapred.TaskTracker类实现了MapReduce模型中TaskTracker的功能。
TaskTracker也是作为一个单独的JVM来运行的,其main函数就是TaskTracker的入口函数,当运行start-all.sh时,脚本就是通过SSH运行该函数来启动TaskTracker的。
Main函数中最重要的语句是:
new TaskTracker(conf).run();
其中run函数主要调用了offerService函数:
State offerService() throws Exception { longlastHeartbeat = 0; //TaskTracker进程是一直存在的 while(running && !shuttingDown) { …… long now = System.currentTimeMillis(); //每隔一段时间就向JobTracker发送heartbeat long waitTime = heartbeatInterval - (now - lastHeartbeat);//还需等待的时间 if(waitTime > 0) { synchronized(finishedCount) { if (finishedCount[0] == 0) { finishedCount.wait(waitTime); } finishedCount[0] = 0; } } …… //发送Heartbeat到JobTracker,得到response HeartbeatResponse heartbeatResponse = transmitHeartBeat(now); …… //从Response中得到此TaskTracker需要做的事情 TaskTrackerAction[] actions = heartbeatResponse.getActions(); …… if(actions != null){ for(TaskTrackerAction action: actions) { if (action instanceof LaunchTaskAction) { //如果action是一个新的Task(是LaunchTaskAction的实例),则将Action添加到任务队列中 addToTaskQueue((LaunchTaskAction)action); }else if (action instanceof CommitTaskAction) { //如果action是提交过的一个Task(是CommitTaskAction的实例),在响应的队列中若无当前task,则将其添加进去
CommitTaskAction commitAction = (CommitTaskAction)action; if (!commitResponses.contains(commitAction.getTaskID())) { commitResponses.add(commitAction.getTaskID()); } }else { tasksToCleanup.put(action); } } } } returnState.NORMAL; }
其中transmitHeartBeat函数的作用就是第2章中提到的向JobTracker发送Heartbeat。其主要逻辑如下:
private HeartbeatResponse transmitHeartBeat(long now) throws IOException { //每隔一段时间,在heartbeat中要返回给JobTracker一些统计信息 boolean sendCounters; if (now> (previousUpdate + COUNTER_UPDATE_INTERVAL)) { sendCounters = true; previousUpdate = now; } else { sendCounters = false; } …… //报告给JobTracker,此TaskTracker的当前状态 if(status == null) { synchronized (this) { status = new TaskTrackerStatus(taskTrackerName, localHostname,httpPort,cloneAndResetRunningTaskStatuses(sendCounters), failures,maxCurrentMapTasks, maxCurrentReduceTasks); } } …… /**当满足下面的条件的时候,此TaskTracker请求JobTracker为其分配一个新的Task来运行: *当前TaskTracker正在运行的map task的个数小于可以运行的map task的最大个数 *或者当前TaskTracker正在运行的reduce task的个数小于可以运行的reduce task的最大个数,就是TaskTracker有空闲的意思,Map或Reduce有一个满足条件就OK*/ boolean askForNewTask; long localMinSpaceStart; synchronized (this) { askForNewTask = (status.countMapTasks() < maxCurrentMapTasks || status.countReduceTasks() <maxCurrentReduceTasks) && acceptNewTasks; localMinSpaceStart = minSpaceStart; } …… //向JobTracker发送heartbeat,这是一个RPC调用 HeartbeatResponse heartbeatResponse = jobClient.heartbeat(status,justStarted, askForNewTask,heartbeatResponseId); …… return heartbeatResponse; }
3.4 JobTracker接收Heartbeat并向TaskTracker分配任务
当JobTracker被RPC调用来发送heartbeat的时候,JobTracker的 heartbeat(TaskTrackerStatus status,boolean initialContact, booleanacceptNewTasks, short responseId)函数被调用:
public synchronized HeartbeatResponse heartbeat(TaskTrackerStatus status,boolean initialContact, boolean acceptNewTasks,short responseId) throws IOException{ …… String trackerName = status.getTrackerName();//获取TaskTracker的名字 …… short newResponseId = (short)(responseId + 1); …… HeartbeatResponse response = newHeartbeatResponse(newResponseId, null); List<TaskTrackerAction> actions = new ArrayList<TaskTrackerAction>(); //如果TaskTracker向JobTracker请求一个task运行 if(acceptNewTasks) { TaskTrackerStatus taskTrackerStatus = getTaskTracker(trackerName); if(taskTrackerStatus == null) { LOG.warn("Unknown task tracker polling; ignoring: " +trackerName); } else{ //setup和cleanup的task优先级最高 List<Task> tasks = getSetupAndCleanupTasks(taskTrackerStatus); if(tasks == null ) { //任务调度器分配任务 tasks = taskScheduler.assignTasks(taskTrackerStatus); } if(tasks != null) { for(Task task : tasks) { //将任务放入actions列表,返回给TaskTracker expireLaunchingTasks.addNewTask(task.getTaskID()); actions.add(new LaunchTaskAction(task)); } } } } …… int nextInterval = getNextHeartbeatInterval(); response.setHeartbeatInterval(nextInterval); response.setActions( actions.toArray(newTaskTrackerAction[actions.size()])); …… return response; }
默认的任务调度器为JobQueueTaskScheduler,其assignTasks如下:
public synchronized List<Task> assignTasks(TaskTrackerStatus taskTracker) throwsIOException { ClusterStatus clusterStatus = taskTrackerManager.getClusterStatus(); final int numTaskTrackers = clusterStatus.getTaskTrackers(); final int clusterMapCapacity = clusterStatus.getMaxMapTasks(); final int clusterReduceCapacity = clusterStatus.getMaxReduceTasks(); Collection<JobInProgress> jobQueue = jobQueueJobInProgressListener.getJobQueue(); // // 获取当前TaskTracker的Map+Reduce数目 // final int trackerMapCapacity = taskTracker.getMaxMapTasks(); final int trackerReduceCapacity = taskTracker.getMaxReduceTasks(); final int trackerRunningMaps = taskTracker.countMapTasks(); final int trackerRunningReduces = taskTracker.countReduceTasks(); // 分配的Task List<Task> assignedTasks = new ArrayList<Task>(); // // 计算线程池中(正在运行 + 将要运行的) Map和Reduce任务的数目 // int remainingReduceLoad = 0; int remainingMapLoad = 0; synchronized (jobQueue) { for (JobInProgress job : jobQueue) { if (job.getStatus().getRunState() == JobStatus.RUNNING) { remainingMapLoad += (job.desiredMaps() - job.finishedMaps()); if (job.scheduleReduces()) { remainingReduceLoad += (job.desiredReduces() - job.finishedReduces()); } } } } // 计算Maps和Reduces的加载因子 double mapLoadFactor = 0.0; if (clusterMapCapacity > 0) { mapLoadFactor = (double)remainingMapLoad / clusterMapCapacity; } double reduceLoadFactor = 0.0; if (clusterReduceCapacity > 0) { reduceLoadFactor = (double)remainingReduceLoad / clusterReduceCapacity; } // // 在下面的步骤中,我们首先分配map tasks(如果满足条件),接着分配reduce tasks (如果满足条件)。 // 我们仔细检查每一个到来的job,仅当jobs的准备工作就绪后,它才能获得服务。// // // 当给给定主机的工作量小于此种类型Task的工作量的时候,我们给当前的TaskTracker分配task。//然而,如果集群接近满负荷,我们就不会有足够的空间投机执行task,我们仅仅调度最高优先级的task获得执行。// final int trackerCurrentMapCapacity = Math.min((int)Math.ceil(mapLoadFactor * trackerMapCapacity), trackerMapCapacity); int availableMapSlots = trackerCurrentMapCapacity - trackerRunningMaps;//还可以执行的Map个数 boolean exceededMapPadding = false; if (availableMapSlots > 0) { exceededMapPadding = exceededPadding(true, clusterStatus, trackerMapCapacity); } int numLocalMaps = 0; int numNonLocalMaps = 0; scheduleMaps: for (int i=0; i < availableMapSlots; ++i) { synchronized (jobQueue) { for (JobInProgress job : jobQueue) { if (job.getStatus().getRunState() != JobStatus.RUNNING) { continue; } Task t = null; // 尝试调度本地节点或本地机架的Map task t = job.obtainNewLocalMapTask(taskTracker, numTaskTrackers, taskTrackerManager.getNumberOfUniqueHosts()); if (t != null) { assignedTasks.add(t); ++numLocalMaps; // 不把map task的任务分配到极致, // 集群要为将来失败的task、投机的task保留一些自由区域, // 超越最高优先级的job if (exceededMapPadding) { break scheduleMaps; } // 为下个Map task再次尝试所有的jobs break; } // 尝试调度本地节点或本地机架的Map Task t = job.obtainNewNonLocalMapTask(taskTracker, numTaskTrackers, taskTrackerManager.getNumberOfUniqueHosts()); if (t != null) { assignedTasks.add(t); ++numNonLocalMaps; // 我们至多分配一个关交换或者投机task // 这主要是用来阻止taskTrackers从其他taskTrackers窃取本地tasks // break scheduleMaps; } } } } int assignedMaps = assignedTasks.size(); // // 为reduce tasks保存一些东西
// 然而,对于每个心跳,我们不会分配超过一个reduce task(通常是一个或者0个) // final int trackerCurrentReduceCapacity = Math.min((int)Math.ceil(reduceLoadFactor * trackerReduceCapacity), trackerReduceCapacity); final int availableReduceSlots = Math.min((trackerCurrentReduceCapacity - trackerRunningReduces), 1); boolean exceededReducePadding = false; if (availableReduceSlots > 0) { exceededReducePadding = exceededPadding(false, clusterStatus, trackerReduceCapacity); synchronized (jobQueue) { for (JobInProgress job : jobQueue) { if (job.getStatus().getRunState() != JobStatus.RUNNING || job.numReduceTasks == 0) { continue; } Task t = job.obtainNewReduceTask(taskTracker, numTaskTrackers, taskTrackerManager.getNumberOfUniqueHosts() ); if (t != null) { assignedTasks.add(t); break; }
// 不把reduce task的任务分配到极致,
// 集群要为将来失败的task、投机的task保留一些自由区域,
// 超越最高优先级的job if (exceededReducePadding) { break; } } } } if (LOG.isDebugEnabled()) { LOG.debug("Task assignments for " + taskTracker.getTrackerName() + " --> " + "[" + mapLoadFactor + ", " + trackerMapCapacity + ", " + trackerCurrentMapCapacity + ", " + trackerRunningMaps + "] -> [" + (trackerCurrentMapCapacity - trackerRunningMaps) + ", " + assignedMaps + " (" + numLocalMaps + ", " + numNonLocalMaps + ")] [" + reduceLoadFactor + ", " + trackerReduceCapacity + ", " + trackerCurrentReduceCapacity + "," + trackerRunningReduces + "] -> [" + (trackerCurrentReduceCapacity - trackerRunningReduces) + ", " + (assignedTasks.size()-assignedMaps) + "]"); } return assignedTasks; }
从上面的代码中我们可以知道,JobInProgress的obtainNewMapTask是用来分配maptask的,其主要调用findNewMapTask,根据TaskTracker所在的Node从nonRunningMapCache中查找 TaskInProgress。JobInProgress的obtainNewReduceTask是用来分配reduce task的,其主要调用findNewReduceTask,从nonRunningReduces查找TaskInProgress。
3.5 TaskTracker接收HeartbeatResponse
在向JobTracker发送heartbeat后,如果返回的reponse中含有分配好的任务 LaunchTaskAction,TaskTracker则调用addToTaskQueue方法,将其加入TaskTracker类中 MapLauncher或者ReduceLauncher对象的taskToLaunch队列。在此,MapLauncher和 ReduceLauncher对象均为TaskLauncher类的实例。该类是TaskTracker类的一个内部类,具有一个数据成员,是 TaskTracker.TaskInProgress类型的队列。在此特别注意,在TaskTracker类内部所提到的TaskInProgress 类均为TaskTracker的内部类,我们用TaskTracker.TaskInProgress表示,一定要和MapRed包中的 TaskInProgress类区分,后者我们直接用TaskInProgress表示。如果应答包中包含的任务是map task则放入mapLancher的taskToLaunch队列,如果是reduce task则放入reduceLancher的taskToLaunch队列:
TaskLauncher类的addToTaskQueue方法代码如下:
private void addToTaskQueue(LaunchTaskAction action) { if(action.getTask().isMapTask()) { mapLauncher.addToTaskQueue(action); } else { reduceLauncher.addToTaskQueue(action); } }
private TaskInProgress registerTask(LaunchTaskAction action, TaskLauncher launcher) { //从action中获取Task对象 Task t = action.getTask(); LOG.info("LaunchTaskAction(registerTask): " + t.getTaskID() + " task's state:" + t.getState()); //生成TaskTracker.TaskInProgress对象 TaskInProgress tip = new TaskInProgress(t, this.fConf, launcher); synchronized(this){ /*在相应的数据结构中增加所生成的TaskTracker.TaskInProgress对 象,以通知程序其他部分该任务的建立*/ tasks.put(t.getTaskID(),tip); runningTasks.put(t.getTaskID(),tip); boolean isMap =t.isMapTask(); if (isMap) { mapTotal++; } else { reduceTotal++; } } return tip; }
同时,TaskLauncher类继承了Thread类,所以在程序运行过程中,它们各自都以一个线程独立运行。它们的启动在 TaskTracker初始化过程中已经完成。该类的run函数就是不断监测taskToLaunch队列中是否有新的 TaskTracker.TaskInProgress对象加入。如果有则从中取出一个对象,然后调用TaskTracker类的 startNewTask(TaskInProgress tip)来启动一个task,其又主要调用了localizeJob(TaskInProgresstip),该函数的工作就是第二节中提到的本地化。该函数代码如下:
private void localizeJob(TaskInProgress tip)throws IOException { //首先要做的一件事情是有关Task的文件从HDFS拷贝的TaskTracker的本地文件系统中:job.split,job.xml以及job.jar Path localJarFile = null; Task t =tip.getTask(); JobID jobId = t.getJobID(); Path jobFile = new Path(t.getJobFile()); …… Path localJobFile = lDirAlloc.getLocalPathForWrite( getLocalJobDir(jobId.toString()) + Path.SEPARATOR + "job.xml", jobFileSize, fConf); RunningJob rjob = addTaskToJob(jobId, tip); synchronized (rjob) { if(!rjob.localized) { FileSystem localFs = FileSystem.getLocal(fConf); Path jobDir = localJobFile.getParent(); …… //将job.split拷贝到本地 systemFS.copyToLocalFile(jobFile, localJobFile); JobConf localJobConf = new JobConf(localJobFile); Path workDir = lDirAlloc.getLocalPathForWrite( (getLocalJobDir(jobId.toString()) + Path.SEPARATOR +"work"), fConf); if(!localFs.mkdirs(workDir)) { throw new IOException("Mkdirs failed to create " + workDir.toString()); } System.setProperty("job.local.dir", workDir.toString()); localJobConf.set("job.local.dir", workDir.toString()); //copy Jar file to the local FS and unjar it.
//这里的解压和我们之前解压MapReduce打包成的jar文件有相似之处
String jarFile = localJobConf.getJar(); long jarFileSize = -1; if(jarFile != null) { Path jarFilePath = new Path(jarFile); localJarFile = new Path(lDirAlloc.getLocalPathForWrite( getLocalJobDir(jobId.toString()) +Path.SEPARATOR + "jars", *jarFileSize, fConf), "job.jar"); if(!localFs.mkdirs(localJarFile.getParent())) { throw new IOException("Mkdirs failed to create jars directory"); } //将job.jar拷贝到本地 systemFS.copyToLocalFile(jarFilePath, localJarFile); localJobConf.setJar(localJarFile.toString()); //将job的configuration写成job.xml,可以为后面得具体实现作为一个参考
OutputStream out = localFs.create(localJobFile); try{ localJobConf.writeXml(out); }finally { out.close(); } // 解压缩job.jar RunJar.unJar(new File(localJarFile.toString()), new File(localJarFile.getParent().toString())); } rjob.localized = true; rjob.jobConf = localJobConf; } } //真正的启动此Task launchTaskForJob(tip, new JobConf(rjob.jobConf)); }
当所有的task运行所需要的资源都拷贝到本地后,则调用TaskTracker的launchTaskForJob方法,其又调用TaskTracker.TaskInProgress的launchTask函数:
public synchronized void launchTask() throwsIOException { …… //创建task运行目录 localizeTask(task); if(this.taskStatus.getRunState() == TaskStatus.State.UNASSIGNED) { this.taskStatus.setRunState(TaskStatus.State.RUNNING); } //创建并启动TaskRunner,对于MapTask,创建的是MapTaskRunner,对于ReduceTask,创建的是ReduceTaskRunner this.runner = task.createRunner(TaskTracker.this, this); this.runner.start(); this.taskStatus.setStartTime(System.currentTimeMillis()); }
TaskRunner是抽象类,是Thread类的子类,其run函数如下:
public final void run() { …… TaskAttemptID taskid = t.getTaskID(); LocalDirAllocator lDirAlloc = new LocalDirAllocator("mapred.local.dir"); File jobCacheDir = null; if(conf.getJar() != null) { jobCacheDir = new File( new Path(conf.getJar()).getParent().toString()); } File workDir = new File(lDirAlloc.getLocalPathToRead( TaskTracker.getLocalTaskDir( t.getJobID().toString(), t.getTaskID().toString(), t.isTaskCleanupTask()) + Path.SEPARATOR + MRConstants.WORKDIR, conf).toString()); FileSystem fileSystem; Path localPath; …… //拼接所有的classpath String baseDir; String sep = System.getProperty("path.separator");
//不同的系统下面,路径分隔符不一样,windows下面为“;”
StringBuffer classPath = new StringBuffer(); //start with same classpath as parent process classPath.append(System.getProperty("java.class.path")); classPath.append(sep); if(!workDir.mkdirs()) { if(!workDir.isDirectory()) { LOG.fatal("Mkdirs failed to create " + workDir.toString()); } } String jar = conf.getJar(); // 其实这部分上面也判断过
if (jar!= null) { // if jar exists, it into workDir File[] libs = new File(jobCacheDir, "lib").listFiles(); if(libs != null) { for(int i = 0; i < libs.length; i++) { classPath.append(sep); //add jar from libs to classpath classPath.append(libs[i]); } } classPath.append(sep); classPath.append(new File(jobCacheDir, "classes")); classPath.append(sep); classPath.append(jobCacheDir); } …… classPath.append(sep); classPath.append(workDir); //拼写命令行java及其参数 Vector<String> vargs = new Vector<String>(8); File jvm = new File(new File(System.getProperty("java.home"), "bin"),"java"); vargs.add(jvm.toString()); String javaOpts = conf.get("mapred.child.java.opts", "-Xmx200m"); javaOpts = javaOpts.replace("@taskid@", taskid.toString()); String[] javaOptsSplit = javaOpts.split(" "); String libraryPath = System.getProperty("java.library.path"); if(libraryPath == null) { libraryPath = workDir.getAbsolutePath(); } else{ libraryPath += sep + workDir; } boolean hasUserLDPath = false; for(inti=0; i<javaOptsSplit.length ;i++) { if(javaOptsSplit[i].startsWith("-Djava.library.path=")) { javaOptsSplit[i] += sep + libraryPath; hasUserLDPath = true; break; } } if(!hasUserLDPath) { vargs.add("-Djava.library.path=" + libraryPath); } for(int i = 0; i < javaOptsSplit.length; i++) { vargs.add(javaOptsSplit[i]); } //添加Child进程的临时文件夹 String tmp = conf.get("mapred.child.tmp", "./tmp"); Path tmpDir = new Path(tmp); if(!tmpDir.isAbsolute()) { tmpDir = new Path(workDir.toString(), tmp); } FileSystem localFs = FileSystem.getLocal(conf); if(!localFs.mkdirs(tmpDir) && !localFs.getFileStatus(tmpDir).isDir()) { thrownew IOException("Mkdirs failed to create " + tmpDir.toString()); } vargs.add("-Djava.io.tmpdir=" + tmpDir.toString()); // Add classpath. vargs.add("-classpath"); vargs.add(classPath.toString()); //log文件夹 long logSize = TaskLog.getTaskLogLength(conf); vargs.add("-Dhadoop.log.dir=" + newFile(System.getProperty("hadoop.log.dir") ).getAbsolutePath()); vargs.add("-Dhadoop.root.logger=INFO,TLA"); vargs.add("-Dhadoop.tasklog.taskid=" + taskid); vargs.add("-Dhadoop.tasklog.totalLogFileSize=" + logSize); // 运行map task和reduce task的子进程的main class是Child vargs.add(Child.class.getName()); // main of Child …… //运行子进程 jvmManager.launchJvm(this, jvmManager.constructJvmEnv(setup,vargs,stdout,stderr,logSize, workDir, env, pidFile, conf)); }
在程序运行过程中,实际运行的TaskRunner实例应该是MapTaskRunner或者是ReduceTaskRunner。这两个子类只对TaskRunner进行了简单修改,在此不做赘述。
在jvmManager.launchJvm()方法中,程序将创建一个新的jvm,来执行新的程序。
3.6 MapReduce任务的运行
真正的map task和reduce task都是在Child进程中运行的,Child的main函数的主要逻辑如下:
while (true) {
//从TaskTracker通过网络通信得到JvmTask对象
JvmTaskmyTask = umbilical.getTask(jvmId);
……
idleLoopCount = 0;
task =myTask.getTask();
taskid =task.getTaskID();
isCleanup= task.isTaskCleanupTask();
JobConfjob = new JobConf(task.getJobFile());
TaskRunner.setupWorkDir(job);
numTasksToExecute = job.getNumTasksToExecutePerJvm();
task.setConf(job);
defaultConf.addResource(newPath(task.getJobFile()));
……
//运行task
task.run(job, umbilical); // run the task
if(numTasksToExecute > 0 && ++numTasksExecuted ==
numTasksToExecute){
break;
}
}
3.6.1 MapTask的运行
3.6.1.1 MapTask.run()方法
如果task是MapTask,则其run函数如下:
public void run(final JobConf job, finalTaskUmbilicalProtocol umbilical)
throws IOException,ClassNotFoundException, InterruptedException {
//负责与TaskTracker的通信,通过该对象可以获得必要的对象
this.umbilical = umbilical;
// 启动Reporter线程,用来和TaskTracker交互目前运行的状态
TaskReporter reporter = new TaskReporter(getProgress(), umbilical);
reporter.startCommunicationThread();
boolean useNewApi =job.getUseNewMapper();
/*用来初始化任务,主要是进行一些和任务输出相关的设置,比如创
建commiter,设置工作目录等*/
initialize(job, getJobID(),reporter, useNewApi);
/*以下4个if语句均是根据任务类型的不同进行相应的操作,这些方
法均是Task类的方法,所以与任务是MapTask还是ReduceTask无关*/
if(jobCleanup) {
runJobCleanupTask(umbilical,reporter);
return;
}
if(jobSetup) {
//主要是创建工作目录的FileSystem对象
runJobSetupTask(umbilical,reporter);
return;
}
if(taskCleanup) {
//设置任务目前所处的阶段为结束阶段,并且删除工作目录
runTaskCleanupTask(umbilical,reporter);
return;
}
//如果不是上述四种类型,则真正运行任务
if (useNewApi) {
runNewMapper(job, split, umbilical,reporter);
} else {
runOldMapper(job, split, umbilical, reporter);
}
done(umbilical, reporter);
}
3.6.1.2 MapTask.runNewMapper()方法
其中,我们只研究运用新API编写程序的情况,所以runOldMapper函数我们将不做考虑。runNewMapper的代码如下:
private <INKEY,INVALUE,OUTKEY,OUTVALUE>
voidrunNewMapper(
final JobConf job,
final BytesWritable rawSplit,
final TaskUmbilicalProtocol umbilical,
TaskReporter reporter
) throws IOException, ClassNotFoundException, InterruptedException{
/*TaskAttemptContext类继承于JobContext类,相对于JobContext类增加
了一些有关task的信息。通过taskContext对象可以获得很多与任务执行相
关的类,比如用户定义的Mapper类,InputFormat类等等 */
org.apache.hadoop.mapreduce.TaskAttemptContexttaskContext =
new org.apache.hadoop.mapreduce.TaskAttemptContext(job,getTaskID());
//创建用户自定义的Mapper类的实例
org.apache.hadoop.mapreduce.Mapper
<INKEY,INVALUE,OUTKEY,OUTVALUE> mapper=
org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>) ReflectionUtils.newInstance(taskContext.getMapperClass(),job);
// 创建用户指定的InputFormat类的实例
org.apache.hadoop.mapreduce.InputFormat<INKEY,INVALUE> inputFormat= (org.apache.hadoop.mapreduce.InputFormat<INKEY,INVALUE>)
ReflectionUtils.newInstance(taskContext.getInputFormatClass(),job);
// 重新生成InputSplit
org.apache.hadoop.mapreduce.InputSplit split =null;
DataInputBuffer splitBuffer =new DataInputBuffer();
splitBuffer.reset(rawSplit.getBytes(), 0, rawSplit.getLength());
SerializationFactory factory =new SerializationFactory(job);
Deserializer<? extendsorg.apache.hadoop.mapreduce.InputSplit>
deserializer =
(Deserializer<? extendsorg.apache.hadoop.mapreduce.InputSplit>)
factory.getDeserializer(job.getClassByName(splitClass));
deserializer.open(splitBuffer);
split =deserializer.deserialize(null);
//根据InputFormat对象创建RecordReader对象,默认是LineRecordReader
org.apache.hadoop.mapreduce.RecordReader<INKEY,INVALUE> input =
new NewTrackingRecordReader<INKEY,INVALUE>
(inputFormat.createRecordReader(split, taskContext), reporter);
job.setBoolean("mapred.skip.on", isSkipping());
//生成RecordWriter对象
org.apache.hadoop.mapreduce.RecordWriter output = null;
org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>.Context mapperContext = null;
try {
Constructor<org.apache.hadoop.mapreduce.Mapper.Context>
contextConstructor =
org.apache.hadoop.mapreduce.Mapper.Context.class.getConstructor
(newClass[]{org.apache.hadoop.mapreduce.Mapper.class,
Configuration.class,
org.apache.hadoop.mapreduce.TaskAttemptID.class,
org.apache.hadoop.mapreduce.RecordReader.class,
org.apache.hadoop.mapreduce.RecordWriter.class,
org.apache.hadoop.mapreduce.OutputCommitter.class,
org.apache.hadoop.mapreduce.StatusReporter.class,
org.apache.hadoop.mapreduce.InputSplit.class});
//get an output object
if(job.getNumReduceTasks() == 0) {
output = newNewDirectOutputCollector(taskContext, job,
umbilical, reporter);
} else{
output = new NewOutputCollector(taskContext, job, umbilical,
reporter);
}
mapperContext = contextConstructor.newInstance(mapper, job,
getTaskID(), input, output, committer, reporter, split);
/*初始化,在默认情况下调用的是LineRecordReader的initialize方
法,主要是打开输入文件并且将文件指针指向文件头*/
input.initialize(split, mapperContext);
mapper.run(mapperContext); //运行真正的Mapper类
input.close();
output.close(mapperContext);
} catch(NoSuchMethodException e) {
thrownew IOException("Can't find Context constructor", e);
} catch(InstantiationException e) {
thrownew IOException("Can't create Context", e);
} catch(InvocationTargetException e) {
thrownew IOException("Can't invoke Context constructor", e);
} catch(IllegalAccessException e) {
thrownew IOException("Can't invoke Context constructor", e);
}
}
3.6.1.3 Mapper.run()方法
其中mapper.run方法调用的是Mapper类的run方法。这也是用户要实现map方法所需要继承的类。该类的run方法代码如下:
public void run(Context context) throws IOException, InterruptedException{
setup(context);
while (context.nextKeyValue()){
map(context.getCurrentKey(),context.getCurrentValue(), context);
}
cleanup(context);
}
该方法首先调用了setup方法,这个方法在Mapper当中实际上是什么也没有做。用户可重写此方法让程序在执行map函数之前进行一些其他操 作。然后,程序将不断获取键值对交给map函数处理,也就是用户所希望进行的操作。之后,程序调用cleanup函数。这个方法和setup一样,也是 Mapper类的一个方法,但是实际上什么也没有做。用户可以重写此方法进行一些收尾工作。
3.6.1.4 Map任务执行序列图
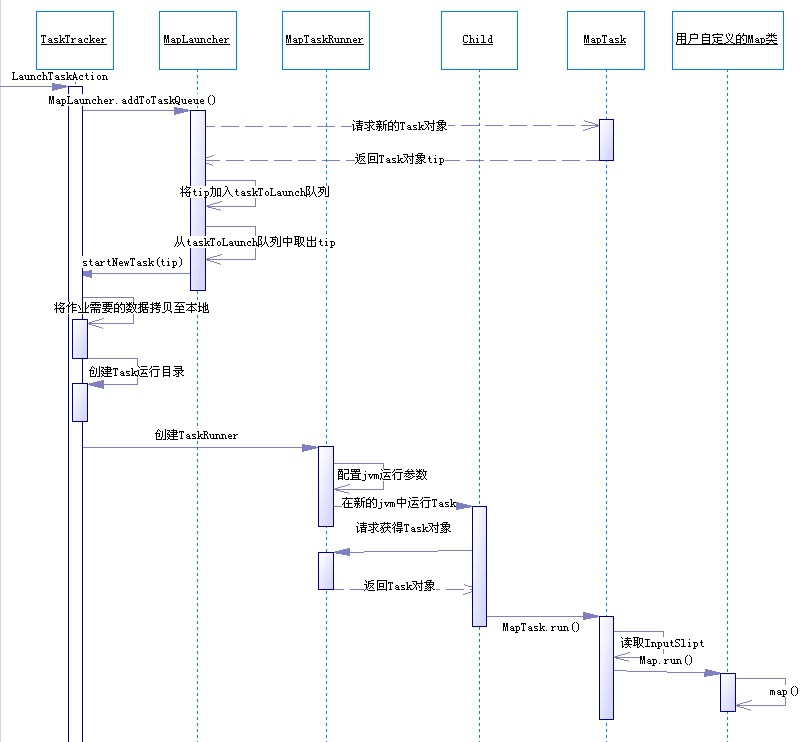
图 Map任务执行序列图
3.6.2 ReduceTask的运行
3.6.2.1 ReduceTask.run()方法
如果运行的任务是ReduceTask,则其run函数如下:
public void run(JobConfjob, final TaskUmbilicalProtocol umbilical)
throws IOException,InterruptedException, ClassNotFoundException {
this.umbilical = umbilical;
job.setBoolean("mapred.skip.on", isSkipping());
/*添加reduce过程需要经过的几个阶段。以便通知TaskTracker目前运
行的情况*/
if (isMapOrReduce()) {
copyPhase =getProgress().addPhase("copy");
sortPhase = getProgress().addPhase("sort");
reducePhase =getProgress().addPhase("reduce");
}
// 设置并启动reporter进程以便和TaskTracker进行交流
TaskReporter reporter = newTaskReporter(getProgress(), umbilical);
reporter.startCommunicationThread();
boolean useNewApi =job.getUseNewReducer();
/*用来初始化任务,主要是进行一些和任务输出相关的设置,比如创
建commiter,设置工作目录等*/
initialize(job, getJobID(), reporter,useNewApi);
/*以下4个if语句均是根据任务类型的不同进行相应的操作,这些方
法均是Task类的方法,所以与任务是MapTask还是ReduceTask无关*/
if(jobCleanup) {
runJobCleanupTask(umbilical, reporter);
return;
}
if(jobSetup) {
//主要是创建工作目录的FileSystem对象
runJobSetupTask(umbilical, reporter);
return;
}
if(taskCleanup) {
//设置任务目前所处的阶段为结束阶段,并且删除工作目录
runTaskCleanupTask(umbilical, reporter);
return;
}
//Initialize the codec
codec =initCodec();
boolean isLocal ="local".equals(job.get("mapred.job.tracker","local"));
if (!isLocal) {
//ReduceCopier对象负责将Map函数的输出拷贝至Reduce所在机器
reduceCopier = newReduceCopier(umbilical, job, reporter);
//fetchOutputs函数负责拷贝各个Map函数的输出
if (!reduceCopier.fetchOutputs()){
if(reduceCopier.mergeThrowable instanceof FSError) {
throw(FSError)reduceCopier.mergeThrowable;
}
throw newIOException("Task: " + getTaskID() +
" - The reducecopier failed", reduceCopier.mergeThrowable);
}
}
copyPhase.complete(); // copy is already complete
setPhase(TaskStatus.Phase.SORT);
statusUpdate(umbilical);
final FileSystem rfs =FileSystem.getLocal(job).getRaw();
//根据JobTracker是否在本地来决定调用哪种排序方式
RawKeyValueIterator rIter =isLocal
? Merger.merge(job, rfs,job.getMapOutputKeyClass(),
job.getMapOutputValueClass(), codec, getMapFiles(rfs, true),
!conf.getKeepFailedTaskFiles(), job.getInt("io.sort.factor",100),
newPath(getTaskID().toString()), job.getOutputKeyComparator(),
reporter,spilledRecordsCounter, null)
:reduceCopier.createKVIterator(job, rfs, reporter);
// free up the data structures
mapOutputFilesOnDisk.clear();
sortPhase.complete(); // sort is complete
setPhase(TaskStatus.Phase.REDUCE);
statusUpdate(umbilical);
Class keyClass =job.getMapOutputKeyClass();
Class valueClass =job.getMapOutputValueClass();
RawComparator comparator =job.getOutputValueGroupingComparator();
if (useNewApi) {
runNewReducer(job, umbilical,reporter, rIter, comparator,
keyClass,valueClass);
} else {
runOldReducer(job, umbilical,reporter, rIter, comparator,
keyClass,valueClass);
}
done(umbilical, reporter);
}
3.6.2.2 ReduceTask.runNewReducer()方法
同样,在此我们只考虑当用户用新的API编写程序时的情况。所以我们只关注runNewReducer方法,其代码如下:
private <INKEY,INVALUE,OUTKEY,OUTVALUE>
void runNewReducer(JobConfjob,
finalTaskUmbilicalProtocol umbilical,
final TaskReporterreporter,
RawKeyValueIterator rIter,
RawComparator<INKEY>comparator,
Class<INKEY>keyClass,
Class<INVALUE>valueClass
) throwsIOException,InterruptedException,
ClassNotFoundException {
// wrapvalue iterator to report progress.
finalRawKeyValueIterator rawIter = rIter;
rIter =new RawKeyValueIterator() {
public void close() throws IOException {
rawIter.close();
}
public DataInputBuffer getKey() throws IOException {
return rawIter.getKey();
}
public Progress getProgress() {
return rawIter.getProgress();
}
public DataInputBuffer getValue() throws IOException {
return rawIter.getValue();
}
public boolean next() throws IOException {
boolean ret = rawIter.next();
reducePhase.set(rawIter.getProgress().get());
reporter.progress();
return ret;
}
};
/*TaskAttemptContext类继承于JobContext类,相对于JobContext类增加
了一些有关task的信息。通过taskContext对象可以获得很多与任务执行相
关的类,比如用户定义的Mapper类,InputFormat类等等 */
org.apache.hadoop.mapreduce.TaskAttemptContexttaskContext =
neworg.apache.hadoop.mapreduce.TaskAttemptContext(job, getTaskID());
//创建用户定义的Reduce类的实例
org.apache.hadoop.mapreduce.Reducer
<INKEY,INVALUE,OUTKEY,OUTVALUE> reducer =
(org.apache.hadoop.mapreduce.Reducer
<INKEY,INVALUE,OUTKEY,OUTVALUE>)
ReflectionUtils.newInstance(taskContext.getReducerClass(), job);
//创建用户指定的RecordWriter
org.apache.hadoop.mapreduce.RecordWriter
<OUTKEY,OUTVALUE> output =
(org.apache.hadoop.mapreduce.RecordWriter<OUTKEY,OUTVALUE>)
outputFormat.getRecordWriter(taskContext);
org.apache.hadoop.mapreduce.RecordWriter<OUTKEY,OUTVALUE>
trackedRW =
new NewTrackingRecordWriter<OUTKEY,OUTVALUE>
(output, reduceOutputCounter);
job.setBoolean("mapred.skip.on", isSkipping());
org.apache.hadoop.mapreduce.Reducer.Context
reducerContext = createReduceContext(reducer, job, getTaskID(),
rIter,reduceInputKeyCounter,
reduceInputValueCounter,
trackedRW, committer,
reporter, comparator, keyClass,
valueClass);
reducer.run(reducerContext);
output.close(reducerContext);
}
3.6.2.3 reducer.run()方法
其中,reducer的run函数如下:
public void run(Context context) throws IOException, InterruptedException{
setup(context);
while (context.nextKey()) {
reduce(context.getCurrentKey(), context.getValues(), context);
}
cleanup(context);
}
该函数先调用setup函数,该函数默认是什么都不做,但是用户可以通过重写此函数来在运行reduce函数之前做一些初始化工作。然后程序会不断读取输入数据,交给reduce函数处理。这里的reduce函数就是用户所写的reduce函数。最后调用cleanup函数。默认的cleanup函数是没有做任何事情,但是用户可以通过重写此函数来进行一些收尾工作。
3.6.2.4 Reduce任务执行序列图
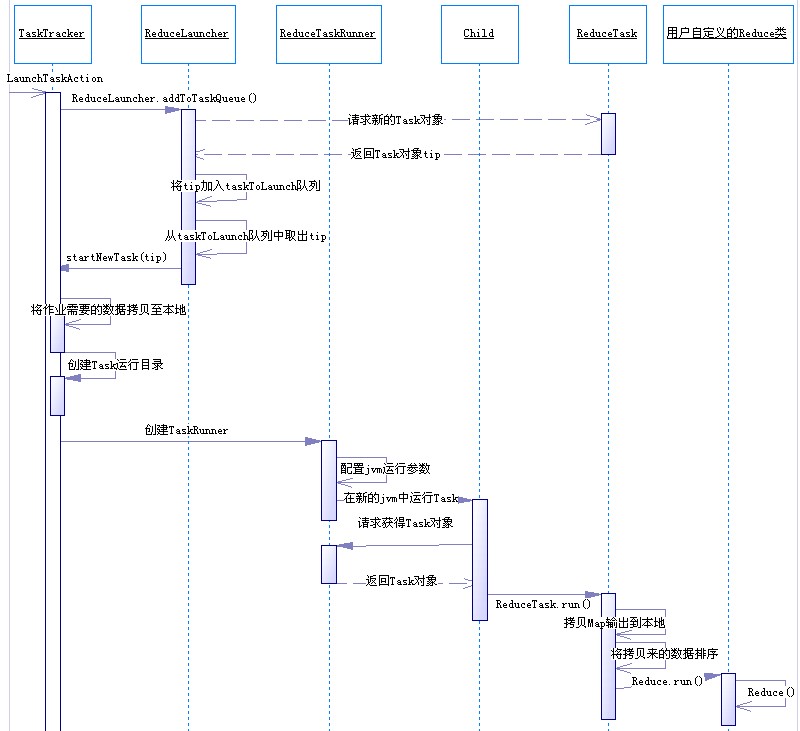
图 Reduce任务执行序列图
4 致谢
作者是在读了“觉先”的博客《Hadoop学习总结之四:Map-Reduce的过程解析》之后才从宏观上了解Hadoop MapReduce模块的工作原理,并且以此为蓝本,写出了本文。所以,在此向“觉先”表示敬意。另外本文当中可能有很多地方直接引用前述博文,在此特别声明,文中就不一一标注了