背景说明
Hash 函数在计算机领域,尤其是数据快速查找领域,加密领域用的极广。
其作用是将一个大的数据集映射到一个小的数据集上面(这些小的数据集叫做哈希值,或者散列值)。
Hash table(散列表,也叫哈希表),是根据哈希值(Key value)而直接进行访问的数据结构。也就是说,它通过把哈希值映射到表中一个位置来访问记录,以加快查找的速度。下面是一个典型的示意图:

但是这种简单的Hash Table存在一定的问题,就是Hash冲突的问题。假设 Hash 函数是良好的,如果我们的位阵列长度为 m 个点,那么如果我们想将冲突率降低到例如 1%, 这个散列表就只能容纳 m * 1% 个元素。显然这就不叫空间有效了(Space-efficient)。
Bloom Filter概述
Bloom Filter是1970年由布隆(Burton Howard Bloom)提出的。它实际上是一个很长的二进制向量和一系列随机映射函数(Hash函数)。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法。Bloom Filter广泛的应用于各种需要查询的场合中,如:
Google 著名的分布式数据库 Bigtable 使用了布隆过滤器来查找不存在的行或列,以减少磁盘查找的IO次数。
在很多Key-Value系统中也使用了布隆过滤器来加快查询过程,如 Hbase,Accumulo,Leveldb,一般而言,Value 保存在磁盘中,访问磁盘需要花费大量时间,然而使用布隆过滤器可以快速判断某个Key对应的Value是否存在,因此可以避免很多不必要的磁盘IO操作,只是引入布隆过滤器会带来一定的内存消耗。
Bloom Filter 原理
如果想判断一个元素是不是在一个集合里,一般想到的是将所有元素保存起来,然后通过比较确定。链表,树等等数据结构都是这种思路. 但是随着集合中元素的增加,我们需要的存储空间越来越大,检索速度也越来越慢。
一个Bloom Filter是基于一个m位的位向量(b1,…bm),这些位向量的初始值为0。另外,还有一系列的hash函数(h1,…hk),这些hash函数的值域属于1~m。下图是一个bloom filter插入x,y,z并判断某个值w是否在该数据集的示意图:
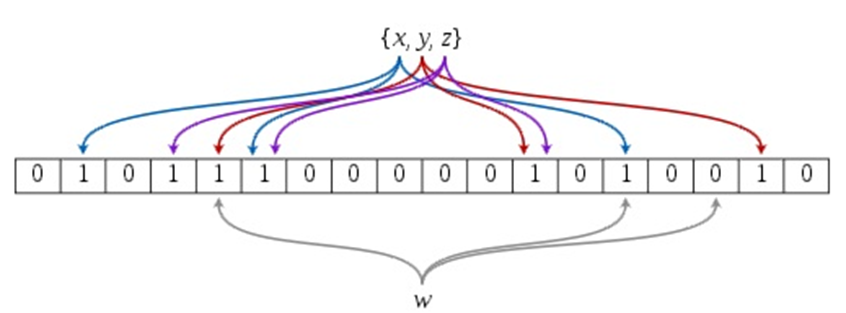
但是布隆过滤器的缺点和优点一样明显。误算率(False Positive)是其中之一。随着存入的元素数量增加,误算率随之增加。但是如果元素数量太少,则使用散列表足矣。
总结:Bloom Filter 通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求100%正确的场合。此外,引入布隆过滤器会带来一定的内存消耗。





厂
