一、使用Docker-compose实现Tomcat+Nginx负载均衡
1.创建docker_compose,在其中配置文件,结构如下
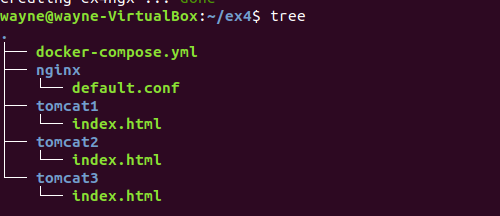
(1)docker-compose
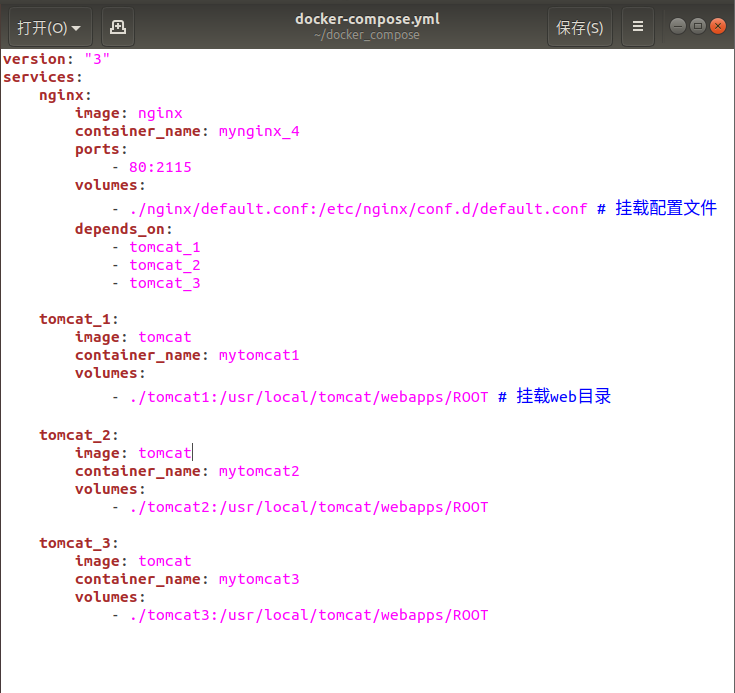
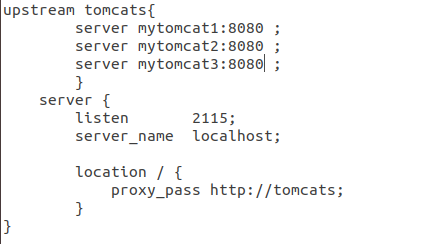
(2)default.conf
(3)运行compose

(4)网页查看
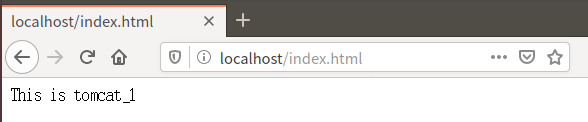
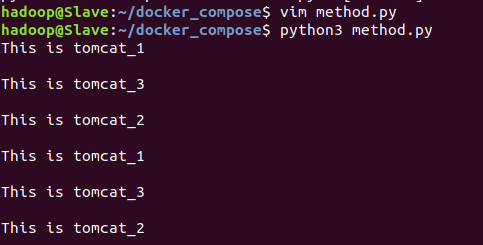
2.负载均衡测试
(1)轮询策略
编写脚本
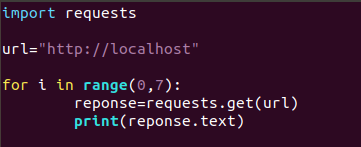
运行
(2)权重策略
修改default.conf
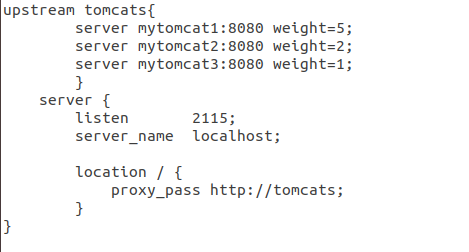
编写脚本
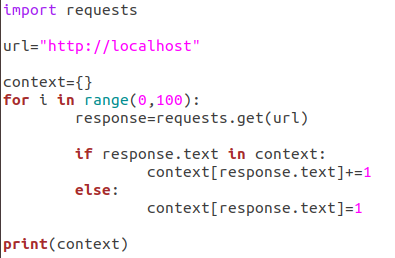
运行

二、使用Docker-compose部署javaweb运行环境
1.文件结构
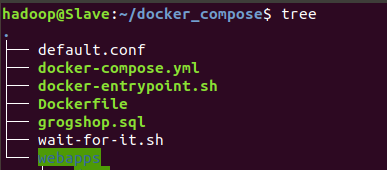
2.配置文件
(1)docker-compose.yml

(2)default.conf

(3)/webapps/ssmgrogshop_war/WEB-INF/classes/jdbc.properties 修改ip和端口
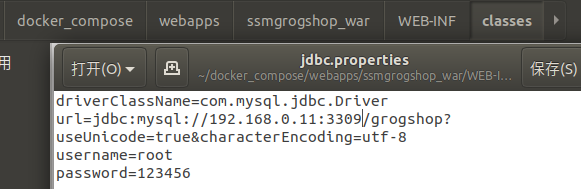
3.启动容器
docker-compose up -d
4.网页查看
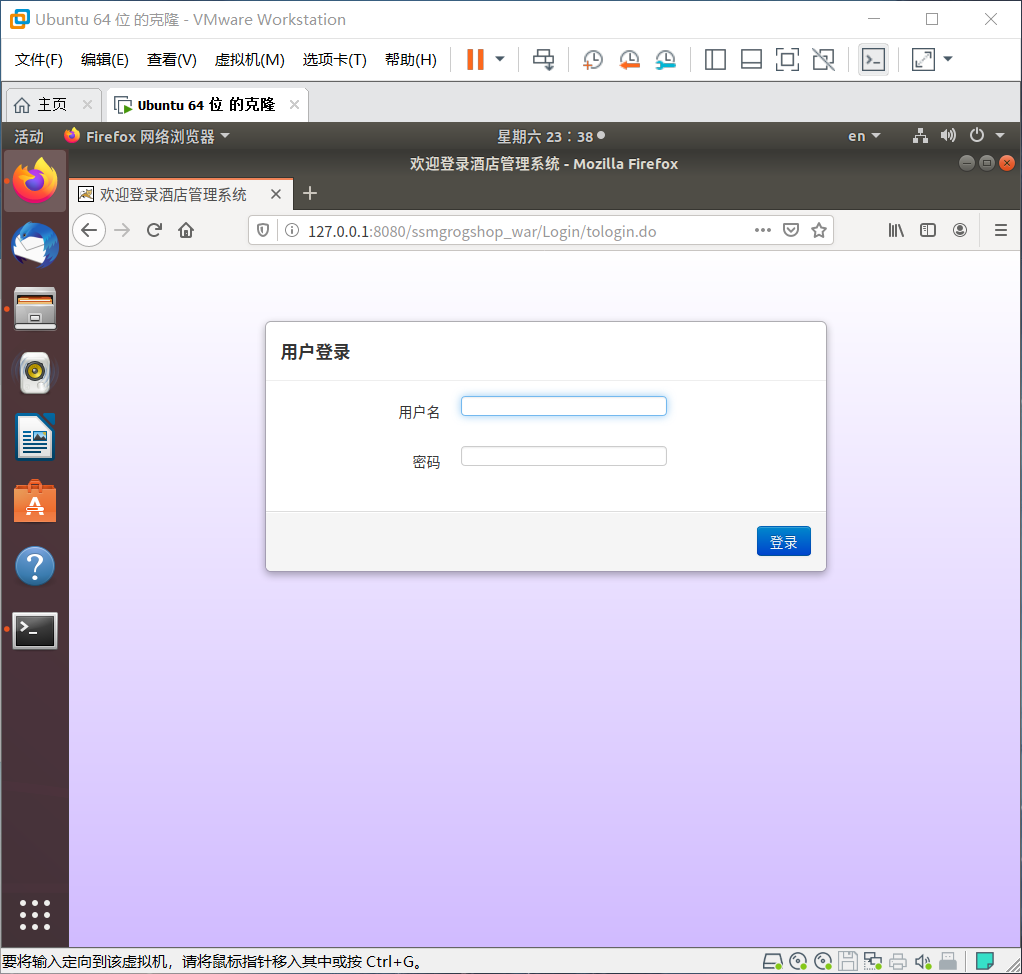
三、使用Docker搭建大数据集群环境
1.创建并运行容器

2.安装ssh

4.修改bashrc:文件末尾添加/etc/init.d/ssh start

5.实现免密登录
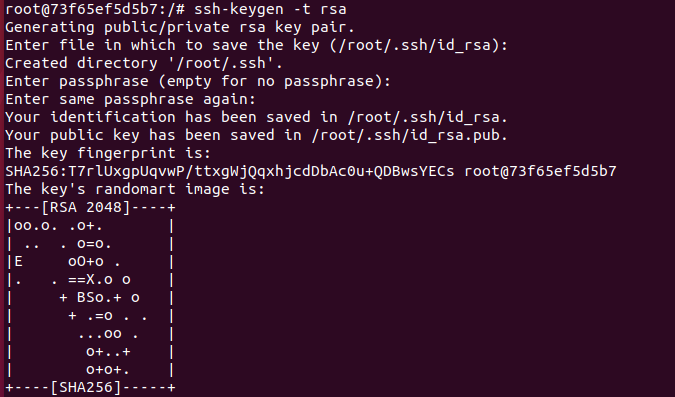

6.安装jdk

7.安装hadoop
(1)将压缩包拷入容器
sudo docker cp /home/cgh/hadoop-3.1.3.tar.gz 容器ID:/root/hadoop-3.1.3.tar.gz
(2)进入容器
docker restart 容器ID
docker attach 容器ID
(3)解压hadoop
cd /root
tar -zxvf hadoop-3.1.3.tar.gz -C /usr/local
8.进行环境配置
(1)修改内容:配置变量

(2)使环境生效

9.配置hadoop集群
(1)修改以下配置

(2)hadoop-env.sh
在文件里添加 export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/
(3)core-site.xml
10.进入脚本目录(cd /usr/local/hadoop-3.1.3/sbin)
(1)start-dfs.sh和stop-dfs.sh,添加下列参数
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
(2)start-yarn.sh和stop-yarn.sh,添加下列参数
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
11.构件镜像
docker commit 容器ID ubuntu/hadoop

12.修改三个终端的hosts

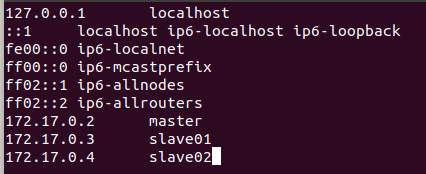
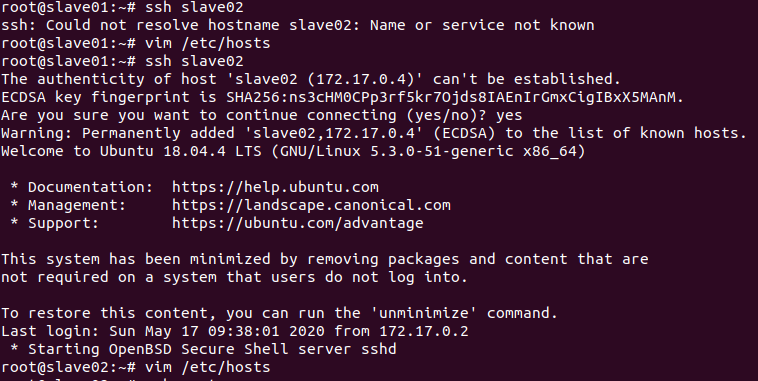
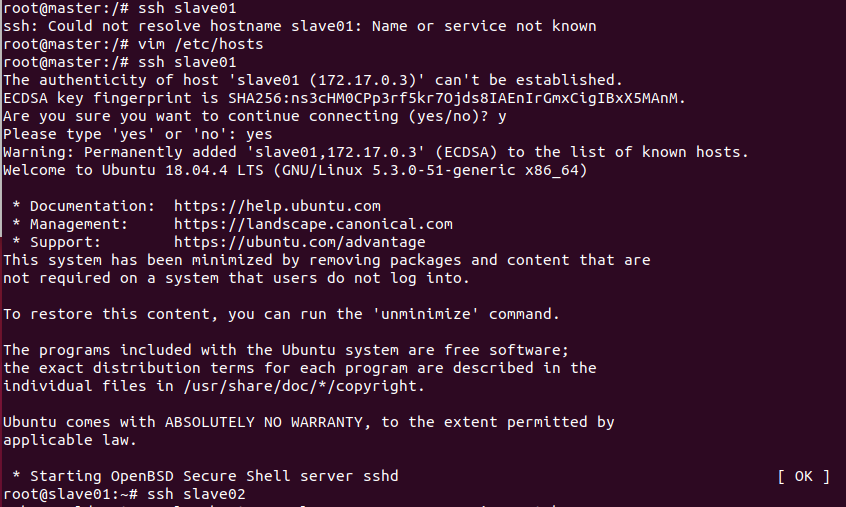
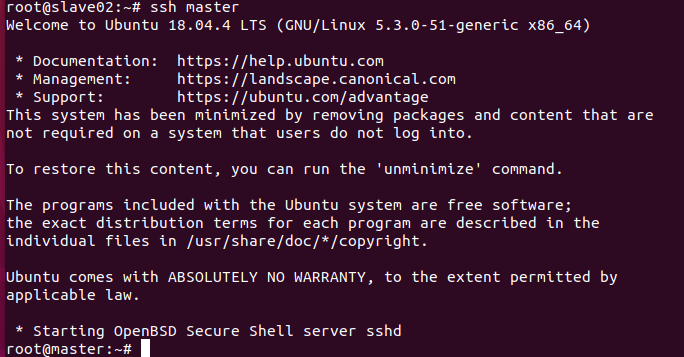
13.通过ssh,相互到达
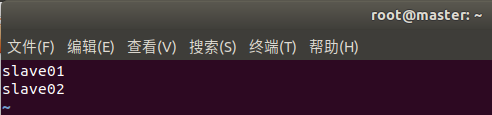
14.在Master上修改workers

15.在master上格式化文件系统

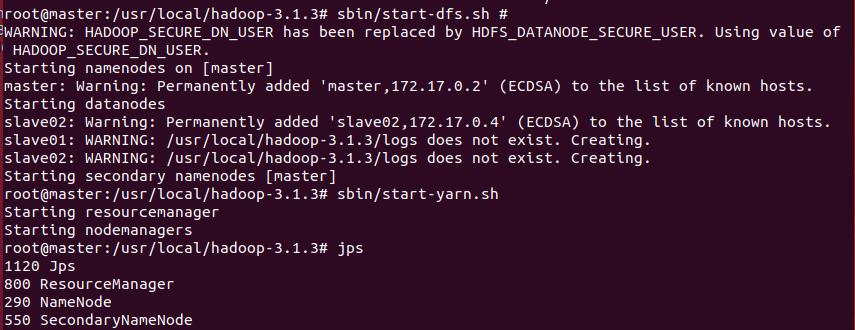
16.启动NameNode和DataNode服务并查看
17.运行hadoop实例程序


18.查看运行结果
