最近在空余时间开发了一个houdini比较撩骚的插件,能够读取当前pm2.5的数值,主要是北京的这个环境太闹心了,脏乱差也得苦中找点乐子吧。插件还没做好,现在只是把数据读取那一部分做完了,等过段时间和搞设计的小伙伴看看怎样做程序动画比较好玩。
这里简单讲一讲思路,之后再上代码吧。
开始之前先列出我抓取数据的网站:
pm2.5 : http://pm25.in
城市列表(事后可以自己手动添加城市) : http://europe.chinadaily.com.cn/travel/2014-12/16/content_19095561.htm
1:读取城市列表。
我想到的是如果你是第一次使用这个插件,在节点创立的时刻能够给你在网络上读取一个可靠地城市列表并以txt的形式存储在你的本地电脑中,这样下一次的时候就能直接调取本地列表了,同时也能够随意添加或修改所需的城市。其实你手动自己去写一个列表也没差,只不过这一步更加智能了一点点。
2:选择城市并调取数据
在面板中选择好自己想要的查找的城市之后,点击更新的时候程序先定位到该城市的网页页面。比如选择“chongqing”,那么脚本会先点位到http://pm25.in/chongqing。其实这个网站已经提供了一个可靠的api,但是这个api的申请审核有点麻烦,所以本着能不麻烦别人就不麻烦别人的原则我就还是不麻烦审核人员了,何况我对实时更新速度根本没要求。用python直接读取页面信息其实也不难,有现成的urllib可以使用,之后再用正则表达式来搜索自己想要的那一部分文本。这里我抓取了pm2.5和一氧化碳等之类的数值,以及AQI的24小时历史数据。
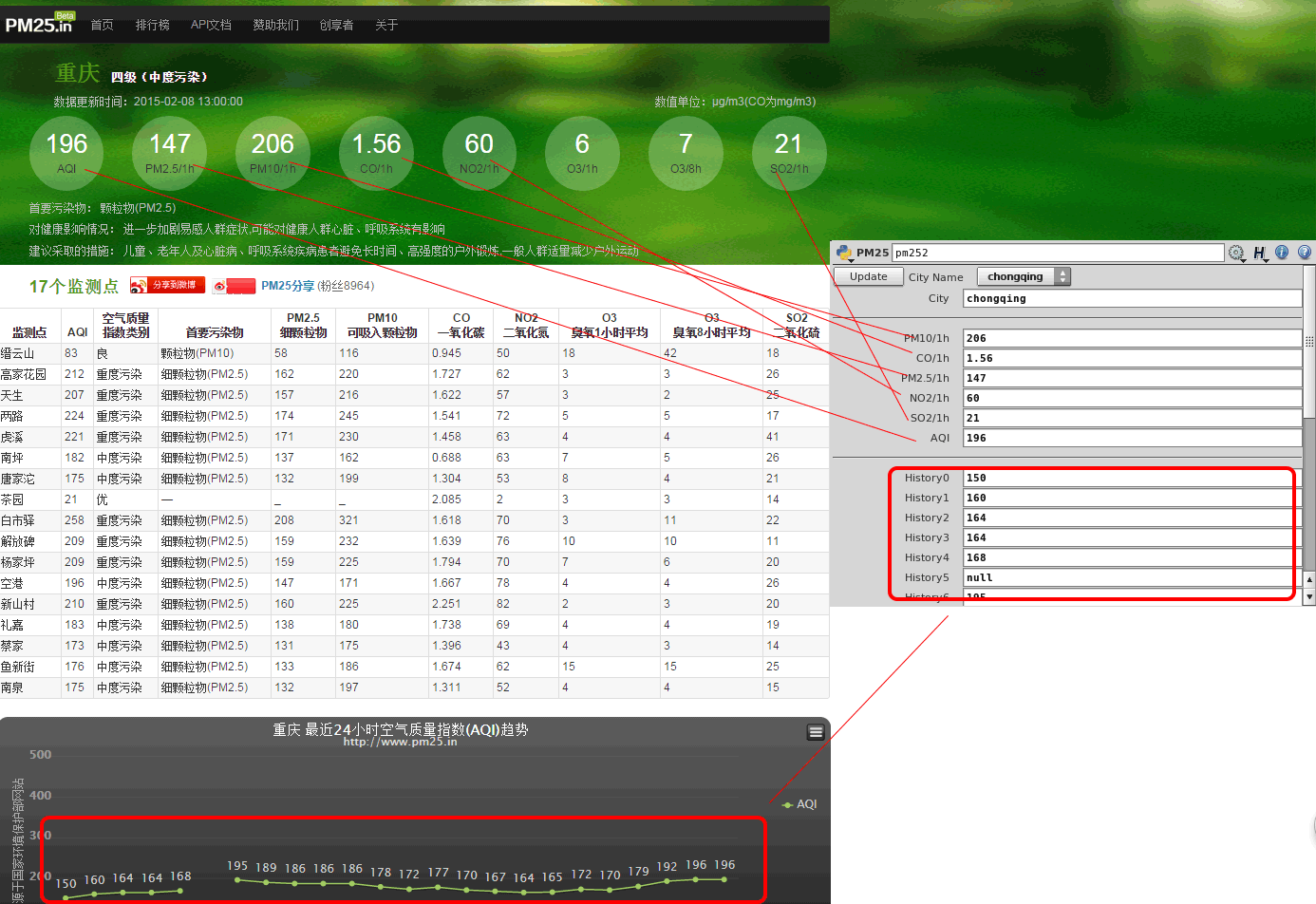
在脚本部分,我分成了两个模块,第一部分是节点生成的时候会执行一边的,主要是更新城市列表的。第二部分是相应按钮来读取具体数据的。下面就上干货代码了:
OnCreated部分:
import re
import urllib2
import string
import hou
url = "http://europe.chinadaily.com.cn/travel/2014-12/16/content_19095561.htm"
cityFileRead = open("C:UsersAdministratorDocumentshoudini13.0pythonFilesCities.txt","r")
cityList = cityFileRead.read()
# open url and get the content
def getUrlContent(url, cityList):
if len(cityList) < 10:
request = urllib2.Request(url)
request.add_header('User-Agent', 'magic-client')
response = urllib2.urlopen(request).read()
print len(response)
return response
else:
return None
def findKeyWords(content):
keyWord = re.compile(r"""(?<=<p>Here is the full list of this year's ranking:</p>).*?(?=<div width="100%">)""", re.DOTALL)
results = keyWord.findall(content)
subKeyWord = re.compile(r"(?<=. ).*?(?=</p>)")
cities = subKeyWord.findall(results[0])
cityFileWrite = open("C:UsersAdministratorDocumentshoudini13.0pythonFilesCities.txt","w")
for city in cities:
city = city.lower()
city = city.replace("’","")
cityFileWrite.write(city + ",")
cityFileWrite.close()
content = getUrlContent(url, cityList)
if content != None:
findKeyWords(content)
cityFileRead.close()
#print "loaded again"
接着是PythonModule部分:
import urllib2
import re
self = hou.pwd()
#geo = self.geometry
cityFileRead = open("C:UsersAdministratorDocumentshoudini13.0pythonFilesCities.txt","r")
cityList = cityFileRead.read()
cityList = cityList.split(",")
pmValues = {}
def getCityName():
index = self.parm("cityName").eval()
#print index
for i in range(len(cityList)):
if i == index:
return cityList[i]
#print cityList[i]
def findUrlContent(city):
url = "http://pm25.in/" + city
#print city
self.setParms({"city":city})
request = urllib2.Request(url)
request.add_header('User-Agent', 'firefox')
response = urllib2.urlopen(request).read()
return response
def getPmInformation(content):
#get per hour data
#print content
dayDataKeyWord = re.compile(r"(?<=data: ).*?(?=,
)")
dayDataResults = dayDataKeyWord.findall(content)[0]
dayDataResults = dayDataResults.replace("[", "")
dayDataResults = dayDataResults.replace("]", "")
histries = dayDataResults.split(",")
#print histries
#get different types of data
typesValueKeyWord = re.compile(r'''(?<=<div class="value">
).*?(?=
</div>)''', re.DOTALL)
typesValueResults = typesValueKeyWord.findall(content)[:-1]
typesTitleKeyWord = re.compile(r'''(?<=<div class="caption">
).*?(?=
</div>)''', re.DOTALL)
typesTitleResults = typesTitleKeyWord.findall(content)
del typesTitleResults[-2]
del typesTitleResults[-2]
for i in range(len(typesTitleResults)):
typesTitleResults[i] = typesTitleResults[i].replace("/","_")
typesTitleResults[i] = typesTitleResults[i].replace(".","_")
pmValues[typesTitleResults[i]] = typesValueResults[i]
#print pmValues
return histries
def createAttrib(pmHistry):
for key in pmValues.iterkeys():
self.setParms({key : pmValues[key]})
for i in range(len(pmHistry)):
name = "histry%d" % i
self.setParms({name : pmHistry[i]})
def update():
city = getCityName()
#print city
content = findUrlContent(city)
#print content
pmHistry = getPmInformation(content)
createAttrib(pmHistry)
#print "done"
cityFileRead.close()
代码里面有我自定义的本地路径,需要根据不同人进行不同的设置。而且这里的代码普适性不强,因为是根据特定的网络页面来设定的正则表达式,所以换做读取其他页面那上面的代码也就基本作废了。
在最后面板按钮上写上 hou.pwd().hdaModule().update() 就能执行了。
其实现在这个小插件虽然能用了,但还是有些小bug正在调试。问题出在每次新建立这个节点不能直接点击update,需要先打开type properties点apply一下。要不然会报错:'moudel' has no attribute 'update'。 这个问题我估计是生成时脚本加载不完整或者刚生成时Python模块读取不了自身对象。总之还在测试,如果你知道问题在哪,欢迎留言告诉我。