前面几篇博客当中,我们介绍的主要是checkpoint,本篇博客我们介绍一个很相似的机制:SavePoint.
SavePoint概念介绍
Flink通过Savepoint功能可以做到程序升级后,继续从升级前的那个点开始执行计算,保证数据不中断,SavePoint可以生成全局、一致性的快照,也可以保存数据源、offset,
operator操作状态等信息,还可以从应用在过去任意做了savepoint的时刻开始继续消费。
CheckPoint和SavePoint的区别
1. checkPoint
应用定时触发,用于保存状态,会过期,内部应用失败重启的时候使用;
2、savePoint
用户手动执行,是指向Checkpoint的指针,不会过期在升级的情况下使用;
SavePoint的配置方式
1、在flink-conf.yaml中配置Savepoint存储位置
该步骤不是必须设置,但是设置后,后面创建指定Job的Savepoint时,可以不用在手动执行命令时指定Savepoint的位置。
state.savepoints.dir: hdfs://namenode:9000/flink/savepoints
2、触发一个savepoint【直接触发或者在cancel的时候触发】
bin/flink savepoint jobId [targetDirectory] [-yid yarnAppId]【针对on yarn模式需要指定-yid参数】
bin/flink cancel -s [targetDirectory] jobId [-yid yarnAppId]【针对on yarn模式需要指定-yid参数】
3、从指定的savepoint启动job
bin/flink run -s savepointPath [runArgs]
SavePoint案例实战
上面介绍了这么多,实际演练一下:
示例程序:
package Stream_example;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
import java.util.concurrent.TimeUnit;
/**
* @ClassName SocketWindowWordCountJavaCheckPoint
* {功能描述:Flink当中的checkpoint机制
* 滑动窗口计算:实现每隔2秒对最近1个小时的数据进行汇总计算}
* @Author Admin
* CREATE 2020/10/5 18:39
* @Version 1.0.0
*/
public class SocketWindowWordCountJavaCheckPoint {
public static void main(String[] args) throws Exception {
//获取Flink的运行环境.
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//开启flink的checkpoint功能:每隔1000 ms启动一个检查点(设置checkpoint的生命周期.)
env.enableCheckpointing(1000);
//checkpoint高级选项设置.
//设置checkpoint的模式为exactly-once(这也是默认值)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//确保检查点之间至少有500ms的间隔(即checkpoint的最小间隔)
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
//检查点必须在1min之内完成,否则会被丢弃(checkpoint的超时时间)
env.getCheckpointConfig().setCheckpointTimeout(60000);
//同一时间只允许操作一个检查点
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
//Flink程序即使被cancel后,也会保留checkpoint数据,以便根据实际需要恢复到指定的checkpoint.
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//设置statebackend,指定state和checkpoint的数据存储位置(checkpoint的数据必须得有一个可以持久化存储的地方)
env.setStateBackend(new FsStateBackend("hdfs://s101:9000/flink/checkpoints"));
//重启策略采用固定间隔 (Fixed delay) :任务发生故障时重启3次,每次间隔是10秒.
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3,10000));
//连接Socket获取输入的数据.
DataStreamSource<String> socketTextStream = env.socketTextStream("192.168.140.103", 8888, "
");
DataStream<Tuple2<String, Integer>> tuple2SingleOutputStreamOperator = socketTextStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
/**
* @param value socket传过来的一行一行的数据.
* @param out
* @throws Exception
*/
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] splited = line.split("\W+");
for (String word : splited) {
out.collect(new Tuple2<>(word, 1));
}
}
});
//指定时间窗口大小为1*60*60s,指定时间间隔为2s.
DataStream<Tuple2<String, Integer>> sumData = tuple2SingleOutputStreamOperator.keyBy(0).timeWindow(Time.seconds(3600), Time.seconds(2)).sum(1);
sumData.print();
env.execute("SocketWindowWordCountJavaCheckPoint");
}
}
从上面的程序当中,你可能会问:这里也看不到savepoint代码的影子啊?是的,因为savepoint是需要手动操作的!
当我们启动完程序后,我们在页面上面是看到SavePoint的数据是null:
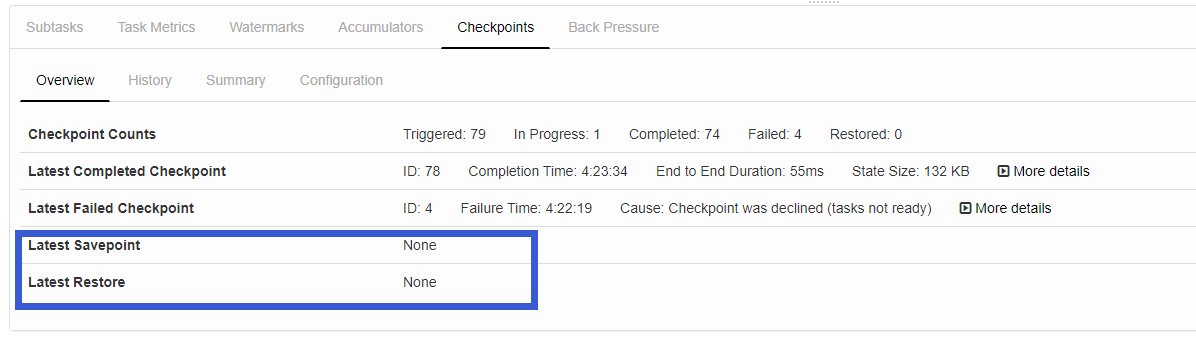
然后我们手动触发一次SavePoint:
[root@s101 /usr/local/software]#flink savepoint 547ac058d6a84efa538be6db25a9224a hdfs://s101:9000/flink/savepoints -yid application_1601832819602_0001 2020-10-05 13:25:43,700 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - Found Yarn properties file under /tmp/.yarn-properties-root. 2020-10-05 13:25:43,700 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - Found Yarn properties file under /tmp/.yarn-properties-root. 2020-10-05 13:25:44,471 INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at s101/192.168.140.101:8032 2020-10-05 13:25:44,692 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar 2020-10-05 13:25:44,692 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar 2020-10-05 13:25:44,711 WARN org.apache.flink.yarn.AbstractYarnClusterDescriptor - Neither the HADOOP_CONF_DIR nor the YARN_CONF_DIR environment variable is set.The Flink YARN Client needs one of these to be set to properly load the Hadoop configuration for accessing YARN. 2020-10-05 13:25:44,856 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Found application JobManager host name 's104' and port '32779' from supplied application id 'application_1601832819602_0001' Triggering savepoint for job 547ac058d6a84efa538be6db25a9224a. Waiting for response... Savepoint completed. Path: hdfs://s101:9000/flink/savepoints/savepoint-547ac0-92290feaf029 You can resume your program from this savepoint with the run command.
此时我们在观察一下页面:
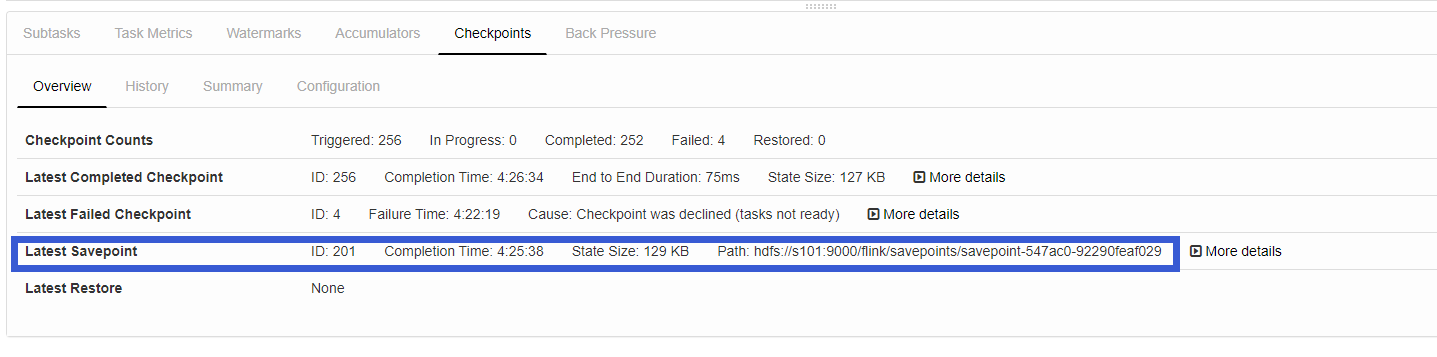
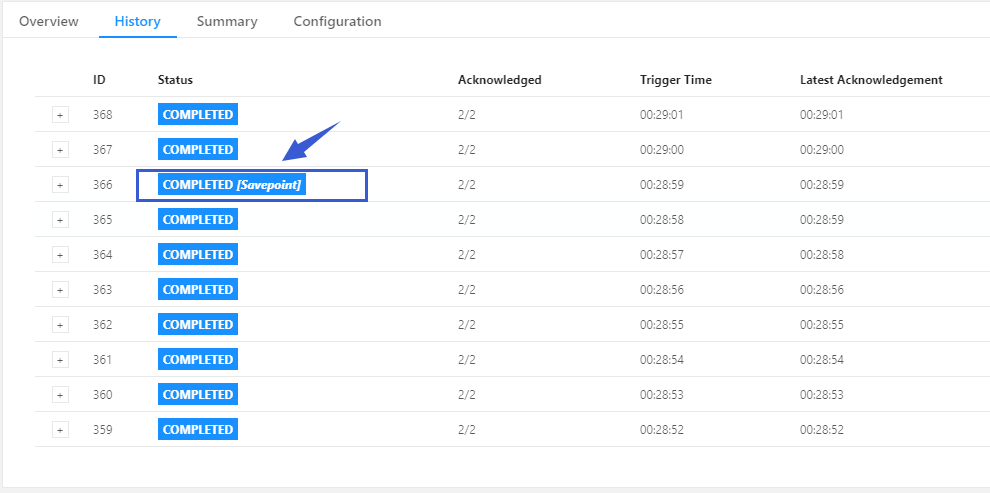
此时我们cancel job,然后在通过刚才的savepoint重启job:
[root@s101 /usr/local/software]#flink run -s hdfs://s101:9000/flink/savepoints/savepoint-547ac0-92290feaf029 -c Stream_example.SocketWindowWordCountJavaCheckPoint FlinkExample-1.0-SNAPSHOT-jar-with-dependencies.jar 2020-10-05 13:29:37,512 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - Found Yarn properties file under /tmp/.yarn-properties-root. 2020-10-05 13:29:37,512 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - Found Yarn properties file under /tmp/.yarn-properties-root. 2020-10-05 13:29:37,885 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - YARN properties set default parallelism to 2 2020-10-05 13:29:37,885 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - YARN properties set default parallelism to 2 YARN properties set default parallelism to 2 2020-10-05 13:29:37,950 INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at s101/192.168.140.101:8032 2020-10-05 13:29:38,087 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar 2020-10-05 13:29:38,087 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar 2020-10-05 13:29:38,092 WARN org.apache.flink.yarn.AbstractYarnClusterDescriptor - Neither the HADOOP_CONF_DIR nor the YARN_CONF_DIR environment variable is set.The Flink YARN Client needs one of these to be set to properly load the Hadoop configuration for accessing YARN. 2020-10-05 13:29:38,175 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Found application JobManager host name 's104' and port '32779' from supplied application id 'application_1601832819602_0001' Starting execution of program
此时我们在观察一下页面:
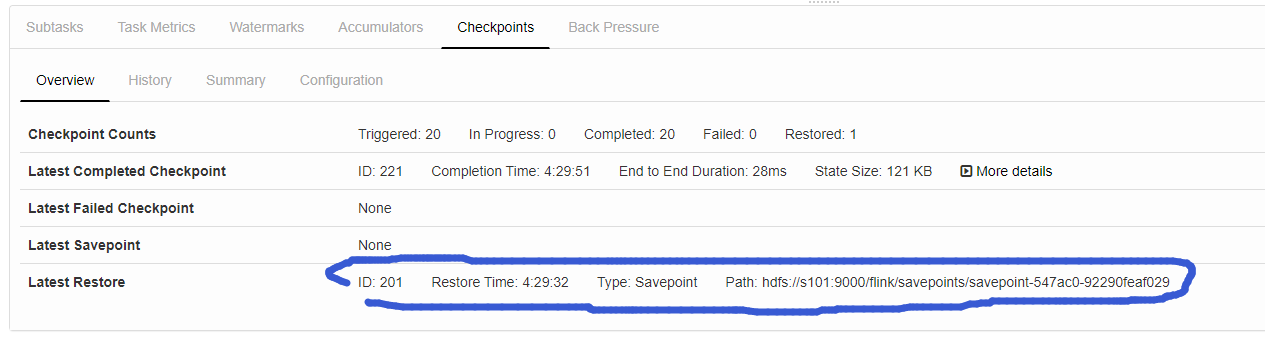
程序继续是我们之前熟悉的样子:

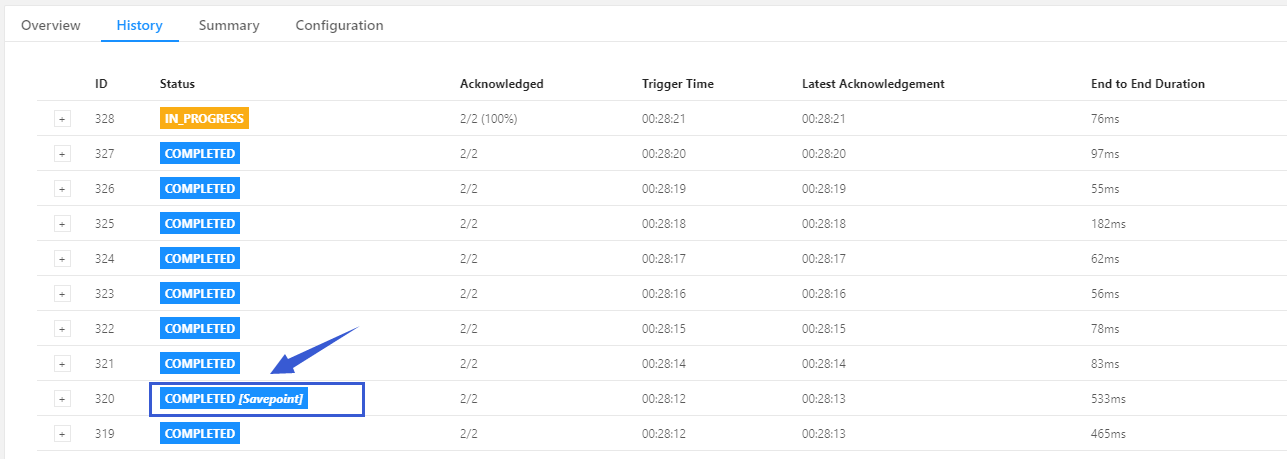
其实我们可以简单理解下Savepoint的功能:Checkpoint相当于系统一直在帮你快照归档,而SavePoint是你自己手动快照归档!(可以理解为SavePoint本质就是CheckPoint)
如何理解savePoint是指向CheckPoint的指针:
OK,到这里,flink的状态管理我们就全部介绍完了,再见各位!
