第六章 SQLA'lchemy
6.1 第一节 MySQL数据库的安装
在Windows下安装MySQL:
-
在
MySQL的官网下载MySQL数据库:https://dev.mysql.com/downloads/windows/installer/5.7.html。 -
然后双击安装,如果出现以下错误,则到
http://www.microsoft.com/en-us/download/details.aspx?id=17113下载.net framework。然后安装。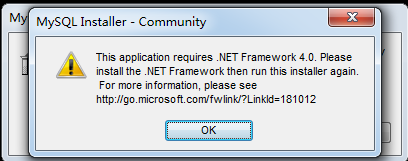
-
在安装过程中,如果提示没有
Microsoft C++ 2013,那么就到以下网址下载安装即可:http://download.microsoft.com/download/9/0/5/905DBD86-D1B8-4D4B-8A50-CB0E922017B9/vcredist_x64.exe。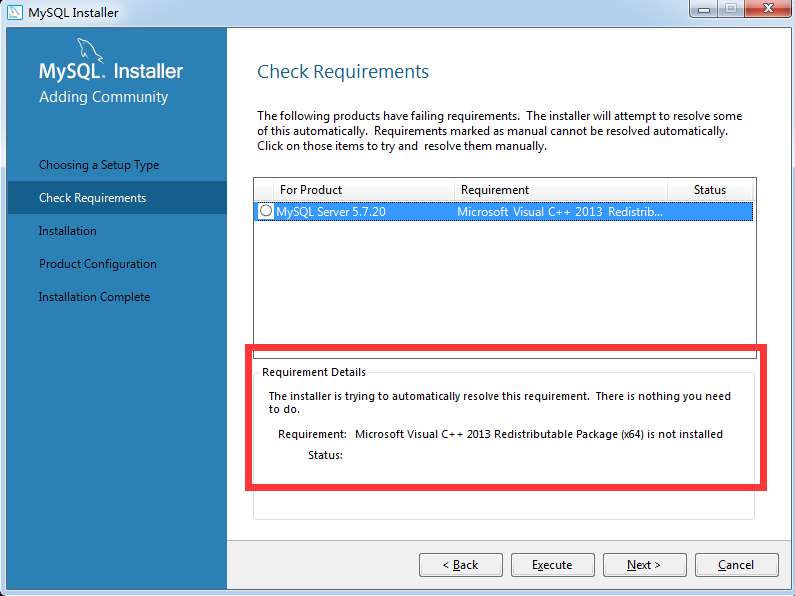
-
然后做好用户名与密码的配置即可。
-
或者求简单,就装php study 这种集成软件,其中包括nginx 和mysql ,redis 都被集成在里面
6.2 第二节SQLAlchemy介绍和基本使用
数据库是一个网站的基础,在Flask中可以自由的使用MySQL、PostgreSQL、SQLite、Redis、MongoDB来写原生的语句实现功能,也可以使用更高级别的数据库抽象方式,如SQLAlchemy或MongoEngine这样的OR(D)M。本教程以MySQL+SQLAlchemy的组合来进行讲解。
在讲解Flask中的数据库操作之前,先确保你已经安装了以下软件:
mysql:如果是在windows上,到官网下载。如果是ubuntu,通过命令sudo apt-get install mysql-server libmysqlclient-dev -yq进行下载安装。MySQLdb:MySQLdb是用Python来操作mysql的包,因此通过pip来安装,命令如下:pip install mysql-python。pymysql:pymysql是用Python来操作mysql的包,因此通过pip来安装,命令如下:pip3 install pymysql。SQLAlchemy:SQLAlchemy是一个数据库的ORM框架,我们在后面会用到。安装命令为:pip3 install SQLAlchemy。
通过SQLAlchemy连接数据库:
首先来看一段代码:
from sqlalchemy import create_engine
# 数据库的配置变量
HOSTNAME = '127.0.0.1'
PORT = '3306'
DATABASE = 'xt_flask'
USERNAME = 'root'
PASSWORD = 'root'
DB_URI = 'mysql+mysqldb://{}:{}@{}:{}/{}'.format(USERNAME,PASSWORD,HOSTNAME,PORT,DATABASE)
# 创建数据库引擎
engine = create_engine(DB_URI)
#创建连接
with engine.connect() as con:
rs = con.execute('SELECT 1')
print rs.fetchone()
首先从sqlalchemy中导入create_engine,用这个函数来创建引擎,然后用engine.connect()来连接数据库。其中一个比较重要的一点是,通过create_engine函数的时候,需要传递一个满足某种格式的字符串,对这个字符串的格式来进行解释:
dialect+driver://username:password@host:port/database
dialect是数据库的实现,比如MySQL、PostgreSQL、SQLite,并且转换成小写。driver是Python对应的驱动,如果不指定,会选择默认的驱动,比如MySQL的默认驱动是MySQLdb。username是连接数据库的用户名,password是连接数据库的密码,host是连接数据库的域名,port是数据库监听的端口号,database是连接哪个数据库的名字。
如果以上输出了1,说明SQLAlchemy能成功连接到数据库。
用SQLAlchemy执行原生SQL:
我们将上一个例子中的数据库配置选项单独放在一个constants.py的文件中,看以下例子:
from sqlalchemy import create_engine
from constants import DB_URI
#连接数据库
engine = create_engine(DB_URI,echo=True)
# 使用with语句连接数据库,如果发生异常会被捕获
with engine.connect() as con:
# 先删除users表
con.execute('drop table if exists users')
# 创建一个users表,有自增长的id和name
con.execute('create table users(id int primary key auto_increment,'
'name varchar(25))')
# 插入两条数据到表中
con.execute('insert into users(name) values("xiaoming")')
con.execute('insert into users(name) values("xiaotuo")')
# 执行查询操作
rs = con.execute('select * from users')
# 从查找的结果中遍历
for row in rs:
print row
6.3 第三节 SQLAlchemy ORM(1)
随着项目越来越大,采用写原生SQL的方式在代码中会出现大量的SQL语句,那么问题就出现了:
- SQL语句重复利用率不高,越复杂的SQL语句条件越多,代码越长。会出现很多相近的SQL语句。
- 很多SQL语句是在业务逻辑中拼出来的,如果有数据库需要更改,就要去修改这些逻辑,这会很容易漏掉对某些SQL语句的修改。
- 写SQL时容易忽略web安全问题,给未来造成隐患。
ORM,全称Object Relational Mapping,中文叫做对象关系映射,通过ORM我们可以通过类的方式去操作数据库,而不用再写原生的SQL语句。通过把表映射成类,把行作实例,把字段作为属性,ORM在执行对象操作的时候最终还是会把对应的操作转换为数据库原生语句。使用ORM有许多优点:
- 易用性:使用
ORM做数据库的开发可以有效的减少重复SQL语句的概率,写出来的模型也更加直观、清晰。 - 性能损耗小:
ORM转换成底层数据库操作指令确实会有一些开销。但从实际的情况来看,这种性能损耗很少(不足5%),只要不是对性能有严苛的要求,综合考虑开发效率、代码的阅读性,带来的好处要远远大于性能损耗,而且项目越大作用越明显。 - 设计灵活:可以轻松的写出复杂的查询。
- 可移植性:
SQLAlchemy封装了底层的数据库实现,支持多个关系数据库引擎,包括流行的MySQL、PostgreSQL和SQLite。可以非常轻松的切换数据库。
使用SQLAlchemy:
要使用ORM来操作数据库,首先需要创建一个类来与对应的表进行映射。现在以User表来做为例子,它有自增长的id、name、fullname、password这些字段,那么对应的类为:
from sqlalchemy import Column,Integer,String
from constants import DB_URI
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
engine = create_engine(DB_URI,echo=True)
# 所有的类都要继承自`declarative_base`这个函数生成的基类
Base = declarative_base(engine)
class User(Base):
# 定义表名为users
__tablename__ = 'users'
# 将id设置为主键,并且默认是自增长的
id = Column(Integer,primary_key=True)
# name字段,字符类型,最大的长度是50个字符
name = Column(String(50))
fullname = Column(String(50))
password = Column(String(100))
# 让打印出来的数据更好看,可选的
def __repr__(self):
return "<User(id='%s',name='%s',fullname='%s',password='%s')>" % (self.id,self.name,self.fullname,self.password)
SQLAlchemy会自动的设置第一个Integer的主键并且没有被标记为外键的字段添加自增长的属性。因此以上例子中id自动的变成自增长的。以上创建完和表映射的类后,还没有真正的映射到数据库当中,执行以下代码将类映射到数据库中:
Base.metadata.create_all()
在创建完数据表,并且做完和数据库的映射后,接下来让我们添加数据进去:
ed_user = User(name='ed',fullname='Ed Jones',password='edspassword')
# 打印名字
print ed_user.name
> ed
# 打印密码
print ed_user.password
> edspassword
# 打印id
print ed_user.id
> None
可以看到,name和password都能正常的打印,唯独id为None,这是因为id是一个自增长的主键,还未插入到数据库中,id是不存在的。接下来让我们把创建的数据插入到数据库中。和数据库打交道的,是一个叫做Session的对象:
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
# 或者
# Session = sessionmaker()
# Session.configure(bind=engine)
session = Session()
ed_user = User(name='ed',fullname='Ed Jones',password='edspassword')
session.add(ed_user)
现在只是把数据添加到session中,但是并没有真正的把数据存储到数据库中。如果需要把数据存储到数据库中,还要做一次commit操作:
session.commit()
# 打印ed_user的id
print ed_user.id
> 1
这时候,ed_user就已经有id。 说明已经插入到数据库中了。有人肯定有疑问了,为什么添加到session中后还要做一次commit操作呢,这是因为,在SQLAlchemy的ORM实现中,在做commit操作之前,所有的操作都是在事务中进行的,因此如果你要将事务中的操作真正的映射到数据库中,还需要做commit操作。既然用到了事务,这里就并不能避免的提到一个回滚操作了,那么看以下代码展示了如何使用回滚(接着以上示例代码):
# 修改ed_user的用户名
ed_user.name = 'Edwardo'
# 创建一个新的用户
fake_user = User(name='fakeuser',fullname='Invalid',password='12345')
# 将新创建的fake_user添加到session中
session.add(fake_user)
# 判断`fake_user`是否在`session`中存在
print fake_user in session
> True
# 从数据库中查找name=Edwardo的用户
tmp_user = session.query(User).filter_by(name='Edwardo')
# 打印tmp_user的name
print tmp_user
# 打印出查找到的tmp_user对象,注意这个对象的name属性已经在事务中被修改为Edwardo了。
> <User(name='Edwardo', fullname='Ed Jones', password='edspassword')>
# 刚刚所有的操作都是在事务中进行的,现在来做回滚操作
session.rollback()
# 再打印tmp_user
print tmp_user
> <User(name='ed', fullname='Ed Jones', password='edspassword')>
# 再看fake_user是否还在session中
print fake_user in session
> False
接下来看下如何进行查找操作,查找操作是通过session.query()方法实现的,这个方法会返回一个Query对象,Query对象相当于一个数组,装载了查找出来的数据,并且可以进行迭代。具体里面装的什么数据,就要看向session.query()方法传的什么参数了,如果只是传一个ORM的类名作为参数,那么提取出来的数据就是都是这个类的实例,比如:
for instance in session.query(User).order_by(User.id):
print instance
# 输出所有的user实例
> <User (id=2,name='ed',fullname='Ed Json',password='12345')>
> <User (id=3,name='be',fullname='Be Engine',password='123456')>
如果传递了两个及其两个以上的对象,或者是传递的是ORM类的属性,那么查找出来的就是元组,例如:
for instance in session.query(User.name):
print instance
# 输出所有的查找结果
> ('ed',)
> ('be',)
以及:
for instance in session.query(User.name,User.fullname):
print instance
# 输出所有的查找结果
> ('ed', 'Ed Json')
> ('be', 'Be Engine')
或者是:
for instance in session.query(User,User.name).all():
print instance
# 输出所有的查找结果
> (<User (id=2,name='ed',fullname='Ed Json',password='12345')>, 'Ed Json')
> (<User (id=3,name='be',fullname='Be Engine',password='123456')>, 'Be Engine')
另外,还可以对查找的结果(Query)做切片操作:
for instance in session.query(User).order_by(User.id)[1:3]
instance
如果想对结果进行过滤,可以使用filter_by和filter两个方法,这两个方法都是用来做过滤的,区别在于,filter_by是传入关键字参数,filter是传入条件判断,并且filter能够传入的条件更多更灵活,请看以下例子:
# 第一种:使用filter_by过滤:
for name in session.query(User.name).filter_by(fullname='Ed Jones'):
print name
# 输出结果:
> ('ed',)
# 第二种:使用filter过滤:
for name in session.query(User.name).filter(User.fullname=='Ed Jones'):
print name
# 输出结果:
> ('ed',)
6.4 第四节 SQLAlchemy的ORM(2)
Column常用参数:
default:默认值。nullable:是否可空。primary_key:是否为主键。unique:是否唯一。autoincrement:是否自动增长。onupdate:更新的时候执行的函数。name:该属性在数据库中的字段映射。
sqlalchemy常用数据类型:
Integer:整形。Float:浮点类型。Boolean:传递True/False进去。DECIMAL:定点类型。enum:枚举类型。Date:传递datetime.date()进去。DateTime:传递datetime.datetime()进去。Time:传递datetime.time()进去。String:字符类型,使用时需要指定长度,区别于Text类型。Text:文本类型。LONGTEXT:长文本类型。
query可用参数:
- 模型对象。指定查找这个模型中所有的对象。
- 模型中的属性。可以指定只查找某个模型的其中几个属性。
- 聚合函数。
func.count:统计行的数量。func.avg:求平均值。func.max:求最大值。func.min:求最小值。func.sum:求和。
过滤条件:
过滤是数据提取的一个很重要的功能,以下对一些常用的过滤条件进行解释,并且这些过滤条件都是只能通过filter方法实现的:
-
equals:query.filter(User.name == 'ed') -
not equals:query.filter(User.name != 'ed') -
like:query.filter(User.name.like('%ed%')) -
in:query.filter(User.name.in_(['ed','wendy','jack'])) # 同时,in也可以作用于一个Query query.filter(User.name.in_(session.query(User.name).filter(User.name.like('%ed%')))) -
not in:query.filter(~User.name.in_(['ed','wendy','jack'])) -
is null:query.filter(User.name==None) # 或者是 query.filter(User.name.is_(None)) -
is not null:query.filter(User.name != None) # 或者是 query.filter(User.name.isnot(None)) -
and:from sqlalchemy import and_ query.filter(and_(User.name=='ed',User.fullname=='Ed Jones')) # 或者是传递多个参数 query.filter(User.name=='ed',User.fullname=='Ed Jones') # 或者是通过多次filter操作 query.filter(User.name=='ed').filter(User.fullname=='Ed Jones') -
or:from sqlalchemy import or_ query.filter(or_(User.name=='ed',User.name=='wendy'))