MapReduce
- MapReduce原理非常重要,hive与spark都是基于MR原理
- MapReduce采用多进程,方便对每个任务资源控制和调配,但是进程消耗更多的启动时间,因此MR时效性不高。适合批量,高吞吐的数据处理。Spark采用的是多线程模型。
MapReduce执行流程
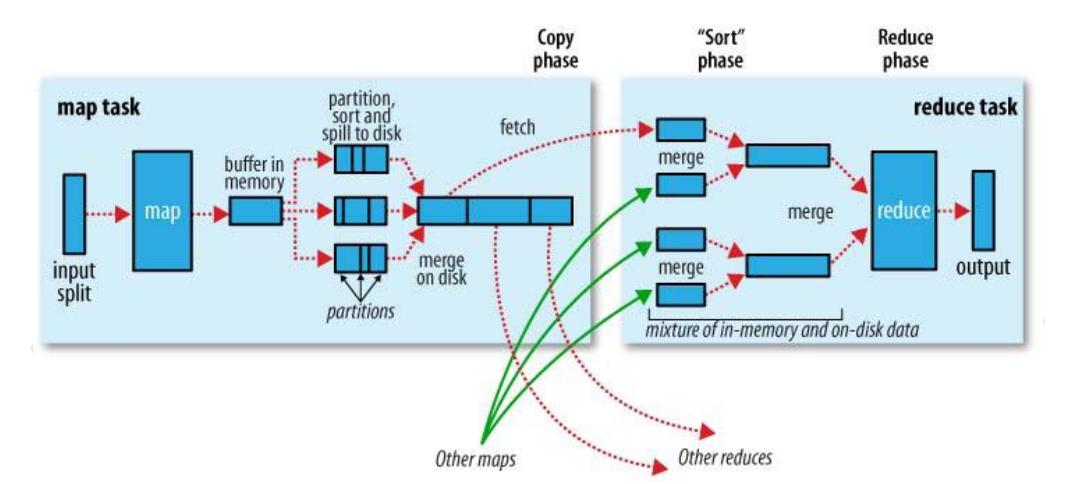
Map过程
- map函数开始产生输出时,并不是直接将数据写到磁盘,它利用缓冲的方式写到内存。每个map任务都有一个环形内存缓冲区用于存储任务输出。在默认情况下,缓冲区大小为100MB。一旦缓冲内容达到阈值(默认80%),便把数据溢出(spill)到磁盘。
Partition过程
- 在map输出数据写入磁盘之前,线程首先根据数据最终要传的reducer把数据划分成相应的分区,这个过程即为partition。
传统hash算法
- hash()%max 括号内随机取数,这样会随机分配到1-max服务器上
一致性hash算法
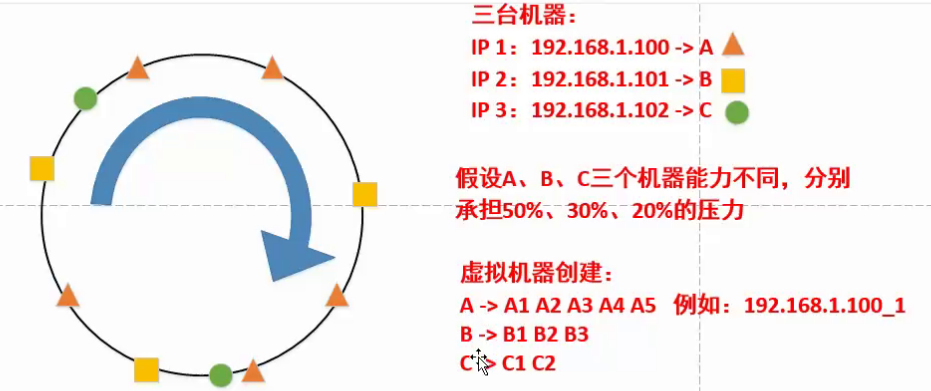
- 一致性哈希算法的优点:形成动态闭环调节,如果有一台服务器出现问题,例如图中B服务器出现问题,A和C可以代替其承担。
Partition的作用
- 对于spill出的数据进行哈希取模,原来数据形式(key, value),取模后变成(partition,key, value)
- reduce有几个partition就有几个
- 在进行MapReduce计算时,有时候需要把最终的输出数据分到不同的文件中,比如按照省份划分的话,需要把同一省份的数据放到一个文件中;按照性别划分的话,需要把同一性别的数据放到一个文件中。我们知道最终的输出数据是来自于Reducer任务。那么,如果要得到多个文件,意味着有同样数量的Reducer任务在运行。Reducer任务的数据来自于Mapper任务,也就说Mapper任务要划分数据,对于不同的数据分配给不同的Reducer任务运行。Mapper任务划分数据的过程就称作Partition。负责实现划分数据的类称作Partitioner。
HDFS中block
- 文件存储在HDFS中,每个文件切分成多个一定大小(默认64M)的block(默认3个备份)存储在多个节点(DataNode)上
- block的修改:hdfs-site.xml配置文件中修改dfs.block.size的值
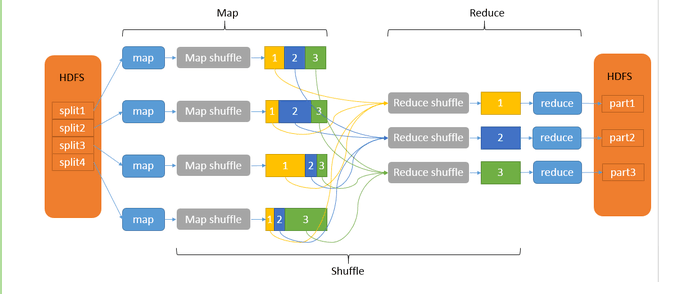
Shuflle
- shuffle是MapReduce的“心脏”,是奇迹发生的地方
- Shuflle包括很多环节:partition sort spill meger combiner copy memery disk