此文紧接Job流程:决定map个数的因素,Map任务被提交到Yarn后,被ApplicationMaster启动,任务的形式是YarnChild进程,在其中会执行MapTask的run()方法。无论是MapTask还是ReduceTask都是继承的Task这个抽象类。
1). Mapper类中 setup() 和 cleanup() 两个方法负责 map 任务的 初始化 和 清理工作(默认是空实现)
2). Mapper类中 run() 方法负责调用用户自定义的 map()方法。最主要的代码在于while()循环。其中,Context类是一个内部类,继承自MapContext接口,间接继承自TaskInputOutputContext类。此类中有一个nextKeyValue()抽象方法,用于将Inputsplit解析成一个个的键值对。在其子类MapContextImpl中提供了具体的解析实现。
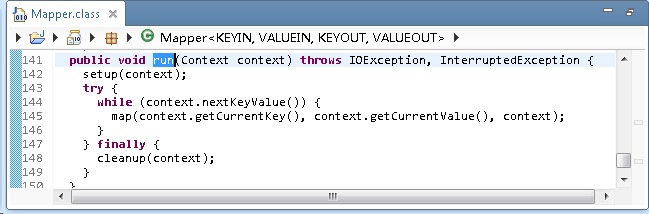
其中,reader是RecordReader类的一个实例。可以看出:map解析Inputsplit成一个个键值对是通过调用RecordReader类的nextKeyValue()方法完成的。
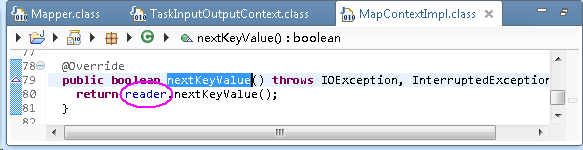
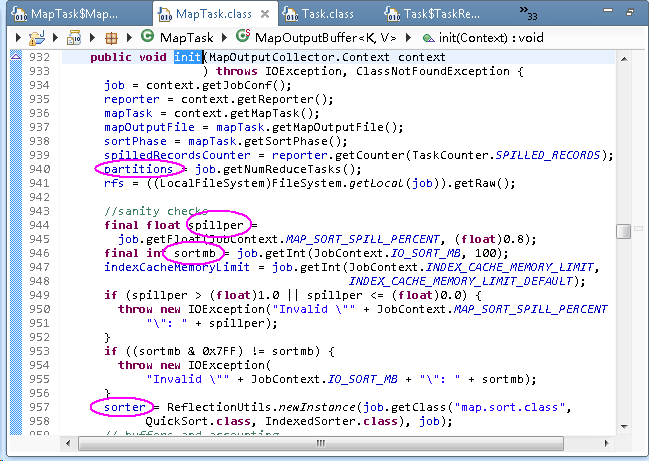
3). map结果是通过context.write()方法写入内存,实际是写入MapOutputBuffer类中。在此类实例化的第一个阶段是初始化init()过程,会根据配置信息初始化内存buf:
- partition:读取job中设置的分区个数,默认为1.
- sortmb:内存buf的大小,默认100MB
- spillper:内存buf的阀值,默认0.8,即100*0.8=80MB
- indexCacheMemoryLimit:内存index的大小。默认为1024*1024
- sorter:对mapper输出的key的排序,默认是快排QuickSort
MR执行流程
1) 客户端提交一个MapReduce的JAR包给JobClient(提交方式:hadoop jar ...),JobClient就是提交节点
2) JobClient通过RPC协议和RM进行通信,返回一个JobId和存放JAR包的HDFS路径
3) JobClient使用FileSystem将JAR包写入到HDFS当中(path = hdfs上的地址 + JobId)。默认10份(mapreduce.client.submit.file.replication),运行结束会被删掉。
4) 开始提交MR任务,提交任务的描述信息(不是JAR包,而是JobId,JAR存放的位置,配置信息等)给RM。
5) RM进行初始化任务。将任务的描述信息存放进调度器(默认是队列调度器)之中,NM通过心跳HeartBeat机制向RM领取任务。NM领取任务之后,NM启动相应的子进程ApplicationMaster运行任务
6) ApplicationMaster读取HDFS上的要处理的文件,开始计算输入分片,每一个分片对应一个MapperTask
7) NM通过HeartBeat心跳机制继续领取任务资源(任务的描述信息)
8) 下载所需的JAR包,配置文件等
9) NM启动一个子进程yarn-child,用来执行具体的子任务(MapperTask或ReducerTask)
10) 将最终结果写入到HDFS当中