设计思想:首先要解决的是读取txt文件的问题,然后把它存入一个数组里面,通过if语句和for循环就可以完成对单词出现次数的统计(但这样似乎很复杂);
设计思想:首先要解决的是读取txt文件的问题,然后把它存入一个数组里面,通过if语句和for循环就可以完成对单词出现次数的统计(但这样似乎很复杂);
问题:网上有读取txt 文件的代码,但问题是我一直看不懂他们是如何读取的,看不懂各段代码的含义,感觉很烦,无力把txt文件写入数组。
package words;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.text.DecimalFormat;
class cs {
public void cs() {
DecimalFormat df = new DecimalFormat("0.00%");
try {
char shu[] = new char[100000];
char zimu[] = new char[52];
int j = 0;
long count[] = new long [52];
String pathname = "D:\piao.txt";
File filename = new File(pathname);
InputStreamReader reader = new InputStreamReader(new FileInputStream(filename));
BufferedReader br = new BufferedReader(reader);
String line[] = new String[100000];
for (int i = 0; i < line.length; i++) {
line[i] = br.readLine();
}
br.close();
int k = 0;
while (line[k] != null) {
for (int i = 0; i < line[k].length(); i++) {
shu[j] = line[k].charAt(i);
j++;
}
k++;
}
for (int i = 0; i < shu.length; i++) {
switch (shu[i]) {
case 'a':
zimu[0] = 'a';
count[0]++;
break;
case 'b':
zimu[1] = 'b';
count[1]++;
break;
case 'c':
zimu[2] = 'c';
count[2]++;
break;
case 'd':
zimu[3] = 'd';
count[3]++;
break;
case 'e':
zimu[4] = 'e';
count[4]++;
break;
case 'f':
zimu[5] = 'f';
count[5]++;
break;
case 'g':
zimu[6] = 'g';
count[6]++;
break;
case 'h':
zimu[7] = 'h';
count[7]++;
break;
case 'i':
zimu[8] = 'i';
count[8]++;
break;
case 'j':
zimu[9] = 'j';
count[9]++;
break;
case 'k':
zimu[10] = 'k';
count[10]++;
break;
case 'l':
zimu[11] = 'l';
count[11]++;
break;
case 'm':
zimu[12] = 'm';
count[12]++;
break;
case 'n':
zimu[13] = 'n';
count[13]++;
break;
case 'o':
zimu[14] = 'o';
count[14]++;
break;
case 'p':
zimu[15] = 'p';
count[15]++;
break;
case 'q':
zimu[16] = 'q';
count[16]++;
break;
case 'r':
zimu[17] = 'r';
count[17]++;
break;
case 's':
zimu[18] = 's';
count[18]++;
break;
case 't':
zimu[19] = 't';
count[19]++;
break;
case 'u':
zimu[20] = 'u';
count[20]++;
break;
case 'v':
zimu[21] = 'v';
count[21]++;
break;
case 'w':
zimu[22] = 'w';
count[22]++;
break;
case 'x':
zimu[23] = 'x';
count[23]++;
break;
case 'y':
zimu[24] = 'y';
count[24]++;
break;
case 'z':
zimu[25] = 'z';
count[25]++;
break;
case 'A':
zimu[26] = 'A';
count[26]++;
break;
case 'B':
zimu[27] = 'B';
count[27]++;
break;
case 'C':
zimu[28] = 'C';
count[28]++;
break;
case 'D':
zimu[29] = 'D';
count[29]++;
break;
case 'E':
zimu[30] = 'E';
count[30]++;
break;
case 'F':
zimu[31] = 'F';
count[31]++;
break;
case 'G':
zimu[32] = 'G';
count[32]++;
break;
case 'H':
zimu[33] = 'H';
count[33]++;
break;
case 'I':
zimu[34] = 'I';
count[34]++;
break;
case 'J':
zimu[35] = 'G';
count[35]++;
break;
case 'K':
zimu[36] = 'K';
count[36]++;
break;
case 'L':
zimu[37] = 'L';
count[37]++;
break;
case 'M':
zimu[38] = 'M';
count[38]++;
break;
case 'N':
zimu[39] = 'N';
count[39]++;
break;
case 'O':
zimu[40] = 'O';
count[40]++;
break;
case 'P':
zimu[41] = 'P';
count[41]++;
break;
case 'Q':
zimu[42] = 'Q';
count[42]++;
break;
case 'R':
zimu[43] = 'R';
count[43]++;
break;
case 'S':
zimu[44] = 'S';
count[44]++;
break;
case 'T':
zimu[45] = 'T';
count[45]++;
break;
case 'U':
zimu[46] = 'U';
count[46]++;
break;
case 'V':
zimu[47] = 'V';
count[47]++;
break;
case 'W':
zimu[48] = 'W';
count[48]++;
break;
case 'X':
zimu[49] = 'X';
count[49]++;
break;
case 'Y':
zimu[50] = 'Y';
count[50]++;
break;
case 'Z':
zimu[51] = 'Z';
count[51]++;
}
}
int ci = 0;
int sum = 0;
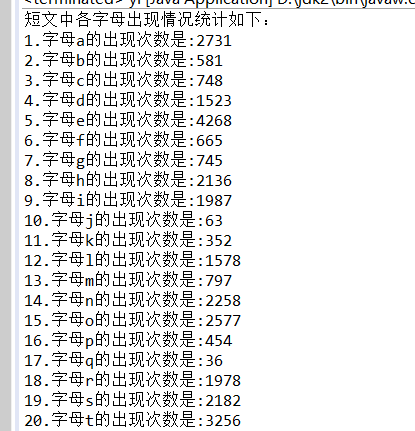
System.out.println("短文中各字母出现情况统计如下:");
for (int i = 0; i < 26; i++) {
count[i]+=count[i+26];
if (count[i] != 0) {
ci++;
sum += count[i];
System.out.println(ci + ".字母" + zimu[i] + "的出现次数是:" + count[i]);
}
}
for (int i = 0; i < 26; i++) {
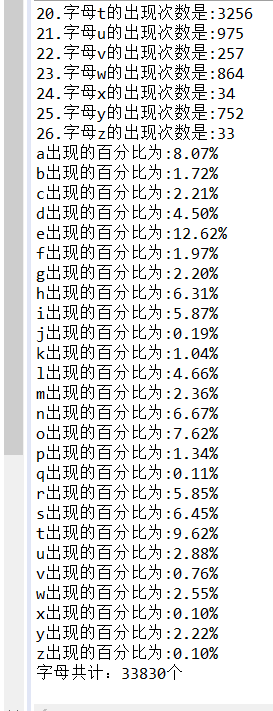
System.out.println(zimu[i]+"出现的百分比为:"+df.format(count[i]*1.0/sum));
}
System.out.println("字母共计:" + sum + "个");
} catch (Exception e) {
e.printStackTrace();
}
}
}
public class yi{
public static void main(String args[]) {
cs s=new cs();
s.cs();
}
}
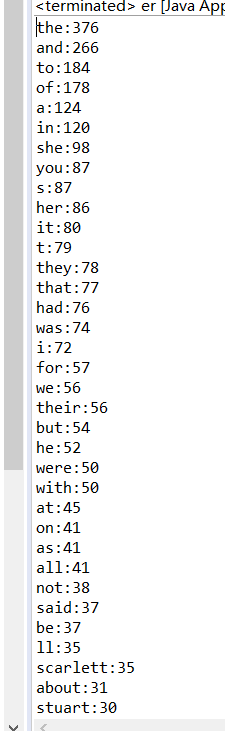
package words; import java.io.BufferedReader; import java.io.FileReader; import java.util.*; public class er { public static void main(String [] args) throws Exception { BufferedReader br = new BufferedReader(new FileReader("D:/piao.txt")); StringBuffer sb = new StringBuffer(); String text =null; while ((text=br.readLine())!= null){ sb.append(text);// 将读取出的字符追加到stringbuffer中 } br.close(); // 关闭读入流 String str = sb.toString().toLowerCase(); // 将stringBuffer转为字符并转换为小写 String[] words = str.split("[^(a-zA-Z)]+"); // 非单词的字符来分割,得到所有单词 Map<String ,Integer> map = new HashMap<String, Integer>() ; for(String word :words){ if(map.get(word)==null ){ // 若不存在说明是第一次,则加入到map,出现次数为1 map.put(word,1); }else { map.put(word,map.get(word)+1); // 若存在,次数累加1 } } // 排序 List<Map.Entry<String ,Integer>> list = new ArrayList<Map.Entry<String,Integer>>(map.entrySet()); Comparator<Map.Entry<String,Integer>> comparator = new Comparator<Map.Entry<String, Integer>>() { public int compare(Map.Entry<String, Integer> left, Map.Entry<String, Integer> right) { return (left.getValue().compareTo(right.getValue())); } }; // 集合默认升序升序 Collections.sort(list,comparator); for(int i=0;i<list.size();i++){// 由高到低输出 System.out.println(list.get(list.size()-i-1).getKey() +":"+list.get(list.size()-i-1).getValue()); } } }
截图: