一、概述
Spark源码整体的逻辑(spark1.3.1):
从saveAsTextFile()方法入手-->saveAsTextFile()
--> saveAsHadoopFile()
--> 封装hadoopConf,并传入saveAsHadoopDataset()方法
--> 拿到写出流SaprkHadoopWriter,调用self.context.runJob(self,writeToFile)
--> runJob方法中,使用dagScheduler划分stage
--> submitJob开始提交作业
-->任务处理器的post方法启动线程,获取队列中的任务,并调用onRecevie()方法提交任务
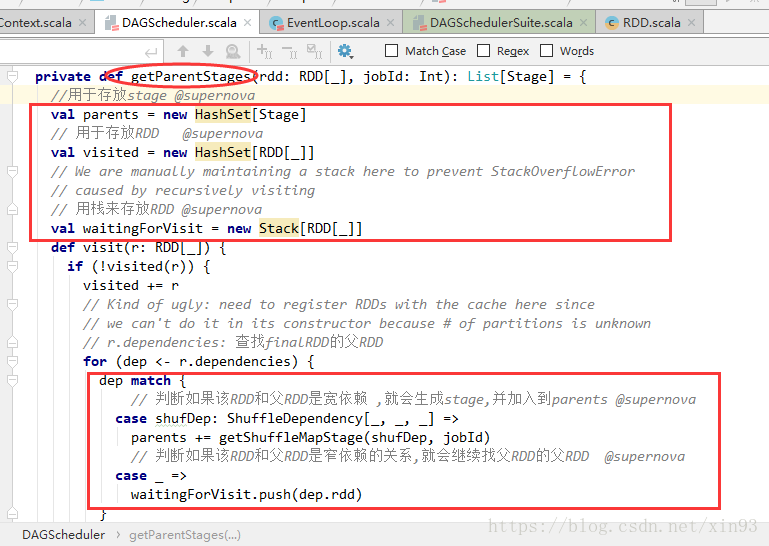
-->调用handleJobSubmitted,使用newStage中的getParentStage方法对stage进行切分
-->getParentStage方法中,使用HashSet、Stack来存放stage和RDD,用栈来存储RDD主要是为了便于后面通过循环进行模式匹配,判断该RDD和父RDD的依赖关系,如果是宽依赖就会生成stage,如果是窄依赖,就会继续找父RDD
二、Spark源码详情
1. 在spark1.3.1的源码中,saveAsTextFile的关键代码在于它内部调用了saveAsHadoopFile()方法。
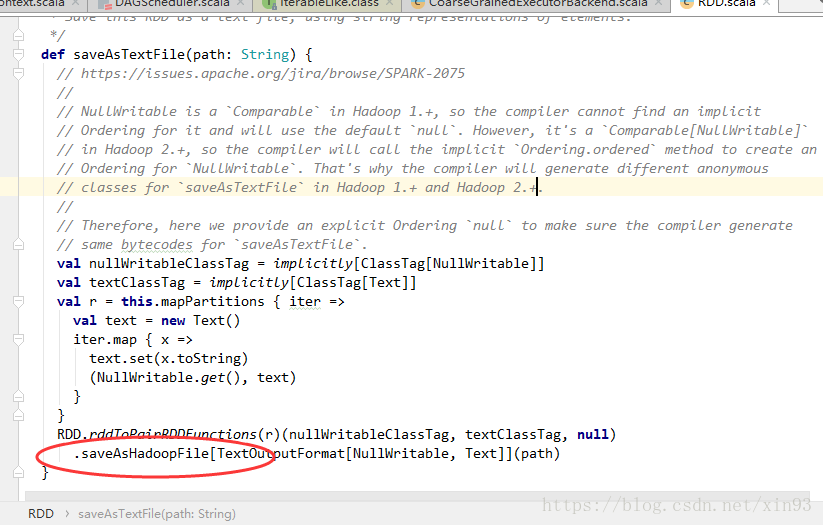
2. 进入到saveAsHadoopFile()方法中,首先spark会对配置信息进行封装,然后将配置信息传入saveAsHadoopDataset( )方法
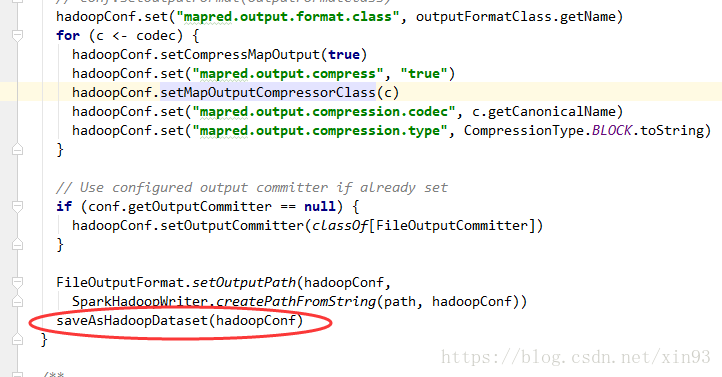
3. saveAsHadoopDataset()方法中将会拿到Spark的写出流,并调用runJob方法准备开始提交作业。

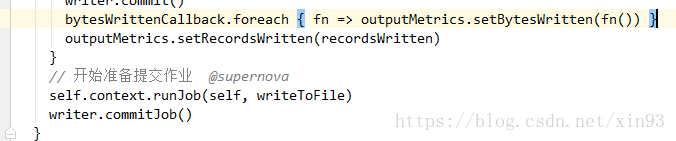
4. 进入runJob方法中,会使用dagScheduler进行stage的切分
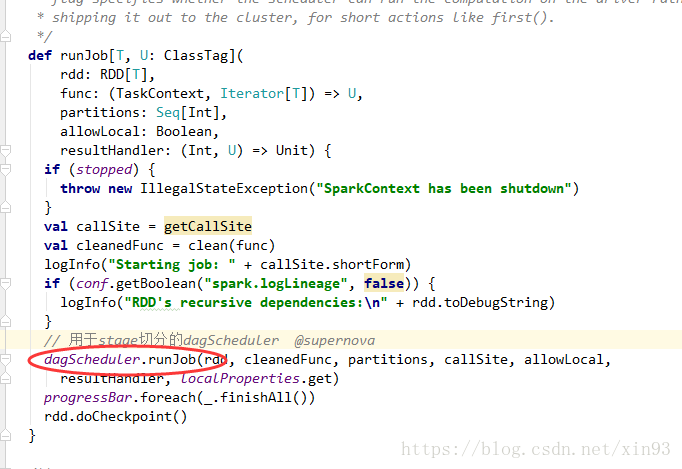
5. submitJob开始提交作业

6. 获取finalRDD的分区数,并调用任务处理器的post方法,循环取出数据放入队列中
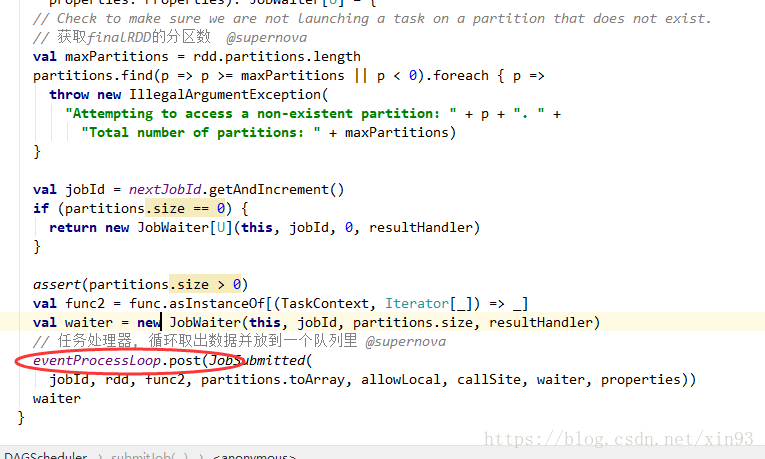
7. post方法中,将启动一个线程,将获取队列中的任务,并调用onRecevie()方法提交任务

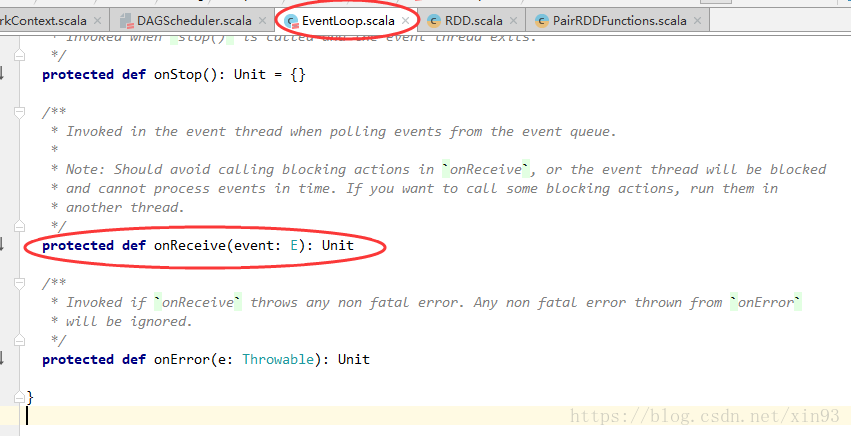
8. 进入onReceive(),可以看到它是一个抽象类中的方法
9. 方法的实现在DAGScheduler中,对方法进行模式匹配。 匹配到任务提交的方法后,调用handleJobSumitted提交任务
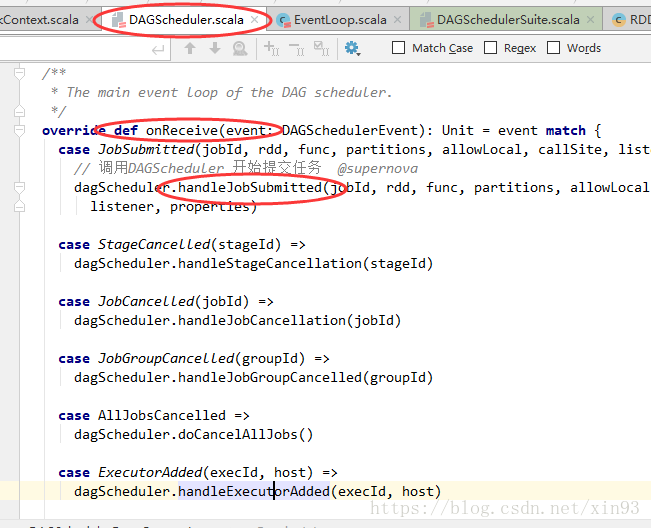
10. handleJobSubmitted中,使用newStage中的getParentStage方法对stage进行切分

11. getParentStage方法中,使用HashSet、Stack来存放stage和RDD,用栈来存储RDD主要是为了便于后面通过循环进行模式匹配,判断该RDD和父RDD的依赖关系,如果是宽依赖就会生成stage,如果是窄依赖,就会继续找父RDD