第一章 环境和概念
2、环境安装
ES:
1)下载
2)解压,双击bin/elasticsearch.bat,访问地址:127.0.0.1:9200
3)修改jvm.options java 虚拟机相关的配置
将-Xms修改为256m(测试环境不需要太大)
4)目录说明:
bin启动文件config配置文件log4j2日志配置文件jvm.options java虚拟机相关的配置elasticsearch.ymlelasticsearch的配置文件! 默认 9200 端口! 跨域!lib相关jar包logs日志!modules功能模块plugins插件!
插件elasticsearch-head-master
1)下载
2)启动(node.js环境)
文档主目录下cmd命令
- npm install(慢)
- npm run start
3)修改ES配置解决跨域问题
- http.cors.enabled: true
- http.cors.allow-origin: "*"
4)访问地址:http://localhost:9100
Kibana
1)下载(版本要和ES一致)
2)汉化!自己修改 kibana 配置即可! zh-CN!
3)启动 /bin/kibana.bat
4)访问 http://localhost:5601
DEMO数据导入
2)使用postman,post请求:localhost:9200/bank/account/_bulk?pretty&refresh
参数选择binary,选择上面下载的文件accounts.json

3、Elastic Stack生态圈

- Logstash:数据处理管道,负责数据采集和转换,可以实时获取IP,排斥敏感字段,拓展插件多,安全等特性
- Beat:轻量数据采集器
- Kibana:数据可视化工具
- Elasticsearch:数据存储
- X-Pack:商业化套件,负责安全
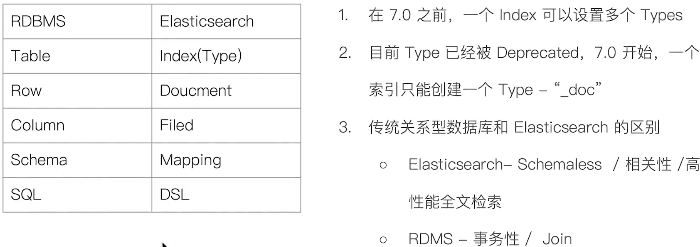
4、概念和数据库类比
5、运维维度,节点、分片
主要围绕两个概念:高可用和拓展性
高可用:简称 HA,是系统一种特征或者指标,体现如下两点:
- 服务可用性:允许部分节点停止服务,整体服务没有影响
- 数据可用性:允许部分节点丢失,最终不会丢失数据
拓展性:将原来节点和增量数据重新从 10 个节点分布到 100 个节点,应对数据的猛增;
节点:是一个ES实例,本质上就是一个java进程,一个机器上可以运行多个实例,但是生产环境建议一台机器上只运行一个ES实例;
节点类型
- Master-eligible Node 和 Master Node:Master Node 负责同步集群状态信息
- Data Node 和 Coordinating Node:数据节点,用于保存数据
- Hot & Warm Node:不同硬件配置的 Data Node,用来实现冷热数据节点架构,降低运维部署的成本
- Machine Learning Node:负责机器学习的节点
- Tribe Node:负责连接不同的集群。支持跨集群搜索 Cross Cluster Search
- master node:通过 node.master 配置,默认 true
- data node:通过 node.data 配置,默认 true
- ingest node:通过 node.ingest 配置,默认 true
- coordinating node:默认每个节点都是 coordinating 节点,设置其他类型全部为 false。
- machine learning:通过 node.ml 配置,默认 true,需要通过 x-pack 开启。
分片
主分片:用来解决数据水平扩展的问题
副本分片:用来备份数据,提高数据的高可用性。副本分片是主分片的拷贝
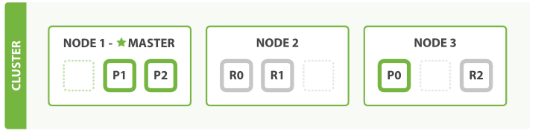
总结:
- 一个节点,对应一个实例
- 一个节点,可以多个索引
- 一个索引,可以多个分片
- 一个分片,对应底层一个 lucene 分片
第二章 基本CRUD
查看集群健康状态
GET _cluster/health *** { "cluster_name" : "elasticsearch", "status" : "green", "timed_out" : false, "number_of_nodes" : 1,//节点数 "number_of_data_nodes" : 1,//数据节点数 "active_primary_shards" : 3,//活跃的主分片 "active_shards" : 3,//总分片数 "relocating_shards" : 0,//? "initializing_shards" : 0,//? "unassigned_shards" : 0,//? "delayed_unassigned_shards" : 0,//? "number_of_pending_tasks" : 0,//? "number_of_in_flight_fetch" : 0,//? "task_max_waiting_in_queue_millis" : 0,//? "active_shards_percent_as_number" : 100.0//? } ***
查看集群状态,并显示列名
GET _cat/nodes?v *** ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name 127.0.0.1 13 69 2 dilm * 3RZNX97CW39V6PU heap.percent:? ram.percent:? ***
查看分片
GET _cat/shards cat命令集合 *** /_cat/allocation #查看单节点的shard分配整体情况 /_cat/shards #查看各shard的详细情况 /_cat/shards/{index} #查看指定分片的详细情况 /_cat/master #查看master节点信息 /_cat/nodes #查看所有节点信息 /_cat/indices #查看集群中所有index的详细信息 /_cat/indices/{index} #查看集群中指定index的详细信息 /_cat/segments #查看各index的segment详细信息,包括segment名, 所属shard, 内存(磁盘)占用大小, 是否刷盘 /_cat/segments/{index}#查看指定index的segment详细信息 /_cat/count #查看当前集群的doc数量 /_cat/count/{index} #查看指定索引的doc数量 /_cat/recovery #查看集群内每个shard的recovery过程.调整replica。 /_cat/recovery/{index}#查看指定索引shard的recovery过程 /_cat/health #查看集群当前状态:红、黄、绿 /_cat/pending_tasks #查看当前集群的pending task /_cat/aliases #查看集群中所有alias信息,路由配置等 /_cat/aliases/{alias} #查看指定索引的alias信息 /_cat/thread_pool #查看集群各节点内部不同类型的threadpool的统计信息, /_cat/plugins #查看集群各个节点上的plugin信息 /_cat/fielddata #查看当前集群各个节点的fielddata内存使用情况 /_cat/fielddata/{fields} #查看指定field的内存使用情况,里面传field属性对应的值 /_cat/nodeattrs #查看单节点的自定义属性 /_cat/repositories #输出集群中注册快照存储库 /_cat/templates #输出当前正在存在的模板信息 ***
创建一个索引
1)创建也给索引并指定类型 PUT /test2 { "mappings": { "properties": { "name": { "type": "text" }, "age": { "type": "long" }, "birthday": { "type": "date" } } } } 2)_create方式创建索引 PUT songjn_index/_create/1 {"name":"songjn","age":"17"} 3)_doc方式创建索引 PUT songjn_index/_doc/1 {"name":"songjn","age":"18"} 说明:创建有两种方式 ①如果创建的过程没有指定索引Field的类型,就会分配固定类型 ②_create:当利用_create关键字进行文档创建的时候,如果该文档存在同一ID则报错 ③_doc:当利用_doc关键字进行文档创建的时候,如果该文档存在则进行删除并新增,版本号+1
get一个索引规则
GET songjn_index
get一个文档
GET songjn_index/_doc/1
update文档
1)post直接更新 POST songjn_index/_doc/2 {"name":"songjn_haha"} 2)put直接更新 PUT songjn_index/_doc/2 {"name":"songjn_haha","age":"18"} 说明:1)2)更新的时候字段要写全,否则其他属性会被更新成空 3)更新最新语法,可以更新部分字段,不会丢失其他字段的值 POST songjn_index/_update/2 { "doc": { "name":"songjn_haha33" } }
删除索引
DELETE .kibana_1
Bulk API
- 支持在一次API调用中,对不同索引进行不同的操作
- 支持的操作类型:Index、Create、Update、Delete
- 操作中,单条失败不会影响其他操作
POST _bulk {"index":{"_index":"songjn_index","_id":"1"}} {"name":"songjianan"} {"delete":{"_index":"songjn_index","_id":"4"}}

批量读取-mget
GET _mget { "docs":[ { "_index":"songjn_index", "_id":"1" }, { "_index":"test2", "_id":"1" } ] }
批量查询-msearch
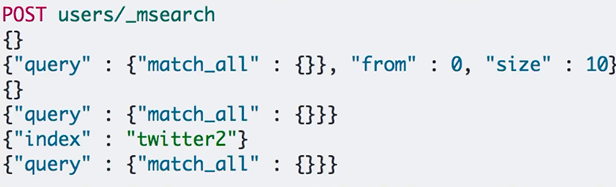
常见错误

第三章 倒排索引
1、举例
1)正排索引

2)倒排索引

2、倒排索引核心组成
-
词条(Term):索引里面最小的存储和查询单元,对于英文来说是一个单词,对于中文来说一般指分词后的一个词。
-
词典(Term Dictionary):或字典,是词条 Term 的集合。搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
-
倒排表(Post list):一个文档通常由多个词组成,倒排表记录的是某个词在哪些文档里出现过以及出现的位置。
每条记录称为一个倒排项(Posting)。倒排表记录的不单是文档编号,还存储了词频等信息。
-
倒排文件(Inverted File):所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
词典和倒排表是 Lucene 中很重要的两种数据结构,是实现快速检索的重要基石。词典和倒排文件是分两部分存储的,词典在内存中而倒排文件存储在磁盘上。
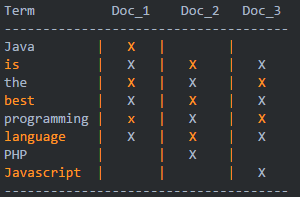
举例:
-
Java is the best programming language.
-
PHP is the best programming language.
-
Javascript is the best programming language.

第四章 分词器
分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词,比如 “我爱北京” 会被分为"我",“爱”,“北”,“京”,这显然是不符合要求的,所以我们需要安装中文分词器 ik 来解决这个问题。
ES内置分词器:
- Standard Analyzer一默认分词器,按词切分,小写处理
- Simple Analyzer 一按照非字母切分(符 号被过滤),小写处理
- Stop Analyzer一小写处理,停用词过滤(the,a,is)
- Whitespace Analyzer一按照空格切分,不转小写
- Keyword Analyzer一不分词,直接将输入当作输出
- Patter Analyzer一正则表达式,默认W+(非字符分隔)
- Language一提供了30多种常见语言的分词器
- Customer Analyzer自定义分词器
分词器测试:
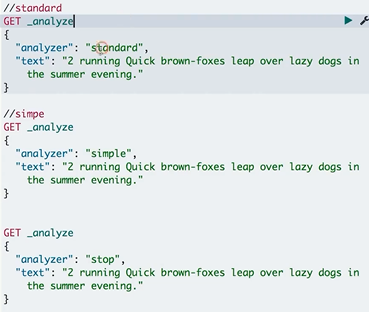
其他中文分词器
1)ICU Analyzer
- 需要安装plugin;
- Elasticsearch-plugin install analysis-icu提供了Unicode的支持,更好的支持亚洲语言
2)IK
- 支持自定义词库,支持热更新分词字典
- https://github.com/medcl/elasticsearch-analysis-ik
3)THULAC
- THU Lexucal Analyzer for Chinese,清华大学自然语言处理和社会人文计算实验室的一套中文分词器
- https://github.com/microbun/elasticsearch-thulac-plugin
第五章 Search API
两种方式:
- URI Search:在URL中使用查询参数
- Request Body Search:使用DSL语句(Query Domain Specific Language)
第一部分 URI Search
指定查询索引:
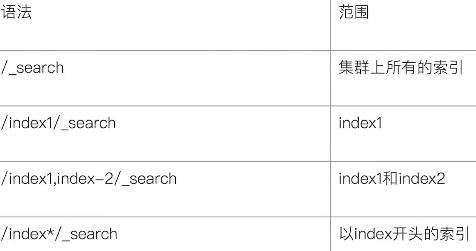
1、URI查询

2、Request Body查询

3、返回说明:

4、搜索示例:
GET/movies/search?q=2O12&df=title&sort=yeardesc&from=O&size=10&timeout=1s { "profile":true }
- q指定查询语句,使用Query String Syntax
- df默认字段,不指定时,会对所有字段进行查询
- Sort排序/from 和size 用于分页
- Profile可以查看查询是如何被执行的
5、语法:
1)指定字段v.s泛查询
- q=title:2012/q=2012
2)Term v.s Phrase
- Beautiful Mind等效于Beautiful OR Mind
- “Beautiful Mind”,等效于Beautiful AND Mind。Phrase 查询,还要求前后顺序保持一致
3)分组与引号
- title:(Beautiful AND Mind)
- title="Beautiful Mind"
4)布尔操作
AND/OR/NOT或者&&/||/!
- 必须大写
- title:(matrix NOT reloaded)
5)分组
- +表示must
- -表示must_not
- title:(+matrix--reloaded)
6)范围查询
区间表示:[]闭区间,{}开区间
- year:{2019 TO 2018]
- year:[* TO 2018]
7)算数符号
- year:>2010
- year:(>2010&&<=2018)
- year:(+>2010 +<=2018)
8)通配符查询(通配符查询效率低,占用内存大,不建议使用。特别是放在最前面)
?代表1个字符,*代表0或多个字符
- title:mi?d
- title:be*
9)正则表达
- title:[bt]oy
10)模糊匹配与近似查询
- title:befutifl~1
- title:"lord rings"~2
第二部分 Request Body Search(高级查询)
- 将查询语句通过HTTP Request Body发送给Elasticsearch
- Query DSL
示例:
POST /bank/_search?ignore_unavailable=true { "profile": "true",//显示profile参数,有分片和查询类型的相关信息 "query": { "match": { "age": 33//年龄属性=30 } } }
分页
POST /bank/_search { "from": 0, "size": 10, "query": { "match_all": {} } }
From从0开始,默认返回10个结果
获取靠后的翻页成本较高
排序
POST /bank/_search { "from": 0, "size": 10, "query": { "match_all": {} }, "sort": [ { "age": {//年龄属性 "order": "asc" } } ] }
最好在“数字型”与“日期型”字段上排序
因为对于多值类型或分析过的字段排序,系统会选一个值,无法得知该值
_source filtering,筛选哪些字段需要返回
POST bank/_search { "_source": ["firstname","age"], "from": 0, "size": 10, "query": { "match_all": {} } }
如果_source 没有存储,那就只返回匹配的文档的元数据
_source 支持使用通配符:_source["name*,"desc*"]
脚本字段:可以根据ES中的"painless“("lang": "painless")脚本计算出来新的结果
GET bank/_search { "script_fields": { "new_field": { "script": { "lang": "painless", //painless,一种脚本计算 "source": "doc['firstname'].value+'hello'"//firstname属性 } } }, "from": 0, "size": 10, "query": { "match_all": {} } }
用例:订单中有不同的汇率,需要结合汇率对,订单价格进行排序!
使用查询表达式-Match,信息匹配
//查询年龄=30的信息 POST bank/account/_search { "query": { "match": { "age": 30 } } } //查询address属性中Sedgwick和Street同实出现的信息 POST bank/_search { "query": { "match": { "address": {//地址属性 "query": "Sedgwick Street"//要匹配的单词 , "operator": "and"//默认写为or,表示地址中有Sedgwick或者Street } } } } //地址中有Sedgwick或者Street POST bank/_search { "query": { "match": { "address": {//地址属性 "query": "Sedgwick Street" , "operator": "or" } } }, "from": 0, "size": 10, "sort": [ { "age": { "order": "desc" } } ] }
短语搜索-Match Phrase,query条件中的词语必须按照顺序出现,
POST bank/_search { "query": { "match_phrase": {//表示"query": "Sedgwick Street"中的词语必须按照顺序出现才能匹配到 "address": {//地址属性 "query": "Sedgwick Street", "slop": 3//可选,中间可以有<3个其他的单词,但是顺序必须是保持一致 } } } }
Query String Query
//address中含有Sedgwick和Street单词,不计顺序 POST bank/_search { "query": { "query_string": { "default_field": "address", "query": "Sedgwick AND Street" } } } //address中含有Sedgwick和Street单词组合或者Bay,不计顺序 POST bank/_search { "query": { "query_string": { "default_field": "address", "query": "(Sedgwick AND Street) OR Bay" } } }
Simple Query String Query
POST bank/_search { "query": { "simple_query_string": { "fields": ["address"], "query": "(Sedgwick+Street)|Bay" } } } ①类似Query String,但是会忽略错误的语法,同时只支持部分查询语法 ②不支持AND OR NOT,会当作字符串处理 ③Term之间默认的关系是OR,可以指定Operator支持部分逻辑 ④+替代AND | 替代OR -替代NOT