本文转自:https://zhuanlan.zhihu.com/p/84688298
1. Count-Min Sketch
Count-Min Sketch 是数据库中用到的一种 Sketch,所谓 sketch 就是用很少的一点数据来描述全体数据的特性,牺牲了准确性但是代价变得很低。
CM-Sketch 的数据模型是这样的:
有一个维度为n 、不断变化的向量(t 表示时间戳)
每个时间 t上会发生一个更新操作,将其中某一个值加上 c,其他值不变
尽管论文还讨论了一些更 general 的情形,我们这里可以简单地理解为,CM-Sketch 要拟合的的数据模型类似一个哈希表加上计数器:假设有一个数据集合里有 n 个 distinct values,ai 表示编号为 i 的值出现的次数,每次更新都在修改这个计数器。
CM-Sketch 作为一个 sketch,目的是用相对小的代价,实现以下几种查询(近似结果):
查询编号为 i 的元素出现的次数(主要功能)
查询编号在
范围内的元素出现的总次数
查询 inner product:
-Quantiles
- Heavy Hitters
2. 实现
CM-Sketch 的内部数据结构是一个二维数组 count,宽度 w,深度 d,此外还需要 d 个两两独立的哈希函数 h1...hd。
更新的时候,用这些哈希函数算出 d 个不同的哈希值,然后把对应的行的值加上 c。
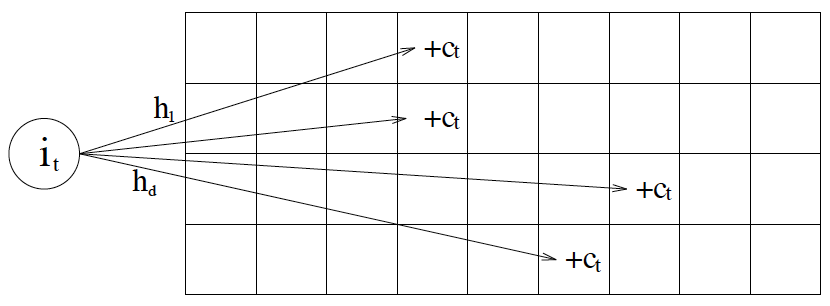
这里的取值是有讲究的:
,
,两个参数的含义是:在
的概率下,总误差(所有元素查询误差的之和)小于
。
3. 结果近似性
这里以 Q(i) 为例,它的近似结果是:
也就是所有哈希到的 count 取最小值。显然真实值一定比这个值更小或者相同,那我们只要证明这个值不会比真实值大太多。
要证的结论:
证明如下:
1) 定义指示变量 表示哈希函数
对于元素
和
是冲突的:他们俩被哈希到同一个 slot 上。站在元素
的角度上看,由于
哈希碰撞,导致元素
的计数加到自己的计数上了。
2) 定义随机变量 ,表示所有元素的
的加和。它表示:哈希函数
未知的情况下,所有元素的总误差。
3) 运用马尔可夫不等式,把期望的 bound 转换成概率的 bound
这也解释了我们之前看到的 d 和 w 的取值是哪来的。