TnsorFlow多层感知机
多层感知机是由感知机推广而来,感知机学习算法(PLA: Perceptron Learning Algorithm)用神经元的结构进行描述的话就是一个单独的。
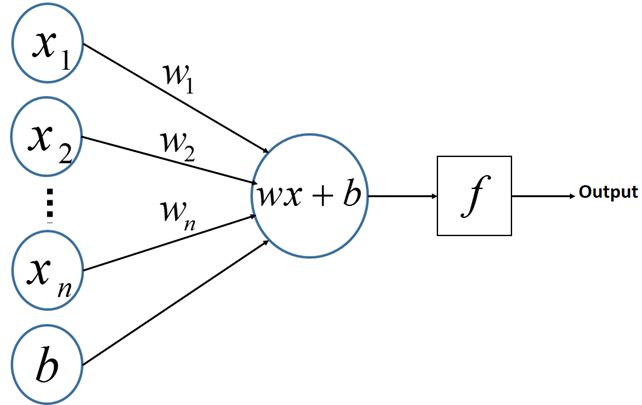
感知机(PLA)的神经网络表示如下:
![]()
从上述内容更可以看出,PLA是一个线性的二分类器,但不能对非线性的数据进行有效的分类。因此便有了对网络层次的加深,理论上,多层网络可以模拟任何复杂的函数。
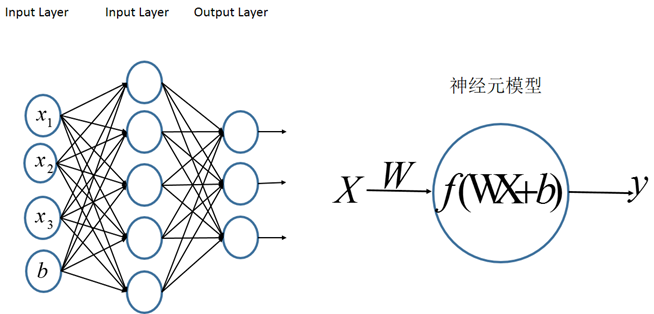
多层感知机MLP多层感知机的一个重要特点就是多层,我们将第一层称之为输入层,最后一层称之有输出层,中间的层称之为隐层。MLP并没有规定隐层的数量,因此可以根据各自的需求选择合适的隐层层数且对于输出层神经元的个数也没有限制。
MLP神经网络结构模型如下,本图中只涉及了一个隐层,输入只有三个变量[x1,x2,x3]和一个偏置量b,输出层有三个神经元。相比于感知机算法中的神经元模型对其进行了集成。
前向传播
前向传播指的是信息从第一层逐渐地向高层进行传递的过程,以下图为例来进行前向传播的过程的分析。
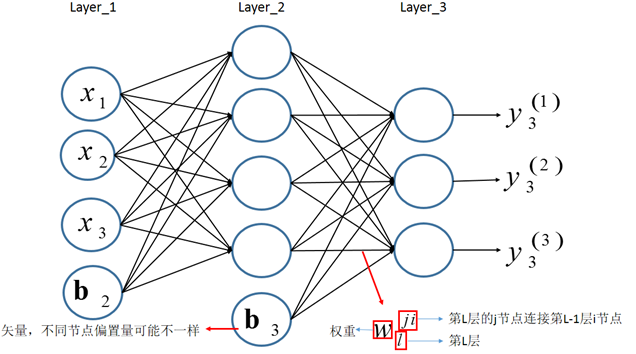
假设第一层为输入层,输入的信息为[x1,x2,x3]。对于层l,用Ll表示该层的所有神经元,其输出为yl,其中第j个节点的输出为yl(j) ,该节点的输入为ul(j),连接第l层与第(l−1)层的权重矩阵为Wl,上一层(第l−1层)的第i个节点到第l层第j个节点的权重为wl(ji)。
结合之前定义的字母标记,对于第二层的三个神经元的输出则有
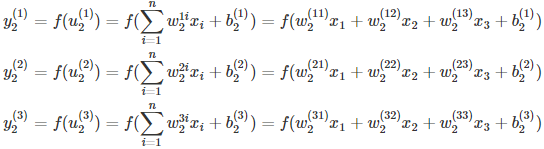
将上述的式子转换为矩阵表达式:
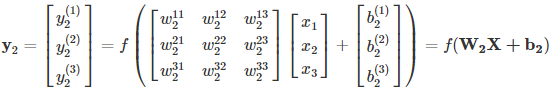
将第二层的前向传播计算过程推广到网络中的任意一层,则:
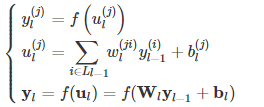
其中f(⋅)为激活函数,bl(j)为第l层第j个节点的偏置。
反向传播
基本的模型搭建完成后,训练的时候所做的就是完成模型参数的更新。由于存在多层的网络结构,因此无法直接对中间的隐层利用损失来进行参数更新,但可以利用损失从顶层到底层的反向传播来进行参数的估计。(约定:小写字母—标量,加粗小写字母—向量,大写字母—矩阵)
假设多层感知机用于分类,在输出层有多个神经元,每个神经元对应一个标签。输入样本为x=[x1,x2,⋯,xn],其标签为t;对于层l,用Ll表示该层的所有神经元,其输出为yl,其中第j个节点的输出为yl(j),该节点的输入为ul(j),连接第l层与第(l−1)层的权重矩阵为Wl,上一层(第l−1层)的第i个节点到第l层第j个节点的权重为wl(ji)。
对于网络的最后一层第k层——输出层,现在定义损失函数:
![]()
为了极小化损失函数,通过梯度下降来进行推导:
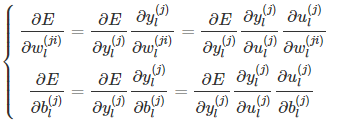
在上面式子中,根据之前的定义,很容易得到:
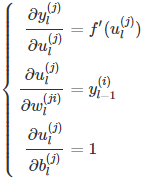
那么则有:
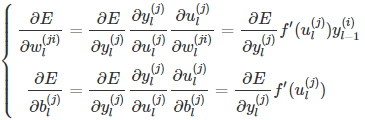
另有,下一层所有结点的输入都与前一层的每个结点输出有关,因此损失函数可以认为是下一层的每个神经元结点输入的函数。那么:
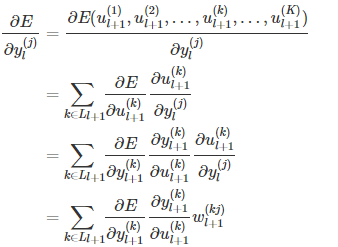
此处定义节点的灵敏度为误差对输入的变化率,即:
![]()
那么第l层第j个节点的灵敏度为:
![]()
结合灵敏度的定义,则有:
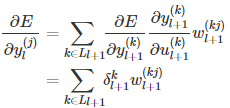
上式两边同时乘上f ′(ul(j)),则有
![]()
注意到上式中表达的是前后两层的灵敏度关系,而对于最后一层,也就是输出层来说,并不存在后续的一层,因此并不满足上式。但输出层的输出是直接和误差联系的,因此可以用损失函数的定义来直接求取偏导数。那么:
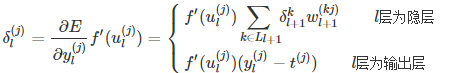
至此,损失函数对各参数的梯度为:
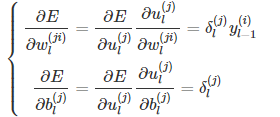
上述的推导都是建立在单个节点的基础上,对于各层所有节点,采用矩阵的方式表示,则上述公式可以写成:

其中运算符∘表示矩阵或者向量中的对应元素相乘。
常见的几个激活函数的导数为:
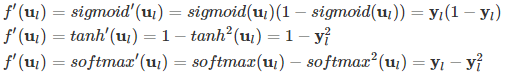
根据上述公式,可以得到各层参数的更新公式为:
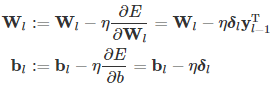
源代码:
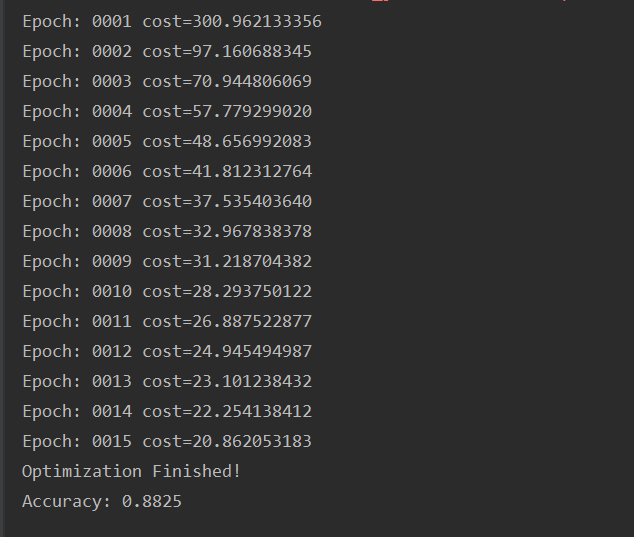
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data import os os.environ["CUDA_VISIBLE_DEVICES"]="0" mnist=input_data.read_data_sets("/home/yxcx/tf_data",one_hot=True) #Parameters learning_rate=0.001 training_epochs=15 batch_size=100 display_step=1 #Network Parameters n_hidden_1=256 n_hidden_2=256 n_input=784 n_classes=10 # tf Graph input X=tf.placeholder("float",[None,n_input]) Y=tf.placeholder("float",[None,n_classes]) #Store layers weight & bias weights={ "h1":tf.Variable(tf.random_normal([n_input,n_hidden_1])), "h2":tf.Variable(tf.random_normal([n_hidden_1,n_hidden_2])), "out":tf.Variable(tf.random_normal([n_hidden_2,n_classes])) } biases={ 'b1':tf.Variable(tf.random_normal([n_hidden_1])), 'b2':tf.Variable(tf.random_normal([n_hidden_2])), 'out':tf.Variable(tf.random_normal([n_classes])) } # Create model def multiplayer_perceptron(x): # Hidden fully connected layer with 256 neurons layer_1=tf.add(tf.matmul(x,weights['h1']),biases['b1']) #Hidden fully connected layer with 256 neurons layer_2=tf.add(tf.matmul(layer_1,weights['h2']),biases['b2']) #Output fully connected layer with a neuron for each class out_layer=tf.matmul(layer_2,weights['out'])+biases['out'] return out_layer #Construct model logits=multiplayer_perceptron(X) #Define loss and optimizer loss_op=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits( logits=logits,labels=Y)) train_op=tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss_op) # Initializing the variables init=tf.global_variables_initializer() with tf.Session() as sess: sess.run(init) #Training cycle for epoch in range(training_epochs): avg_cost=0 total_batch=int(mnist.train.num_examples/batch_size) #loop over all batches for i in range(total_batch): batch_x,batch_y=mnist.train.next_batch(batch_size) #Run optimizeation op and cost op to get loss value _,c=sess.run([train_op,loss_op],feed_dict={X:batch_x,Y:batch_y}) #computer average loss avg_cost+=c/total_batch #Display logs per epoch step if epoch % display_step==0: print("Epoch:","%04d"%(epoch+1),"cost={:.9f}".format(avg_cost)) print("Optimization Finished!") #Test model pred=tf.nn.softmax(logits) correct_prediction=tf.equal(tf.argmax(pred,1),tf.argmax(Y,1)) # Calculate accuracy accuracy=tf.reduce_mean(tf.cast(correct_prediction,"float")) print("Accuracy:",accuracy.eval({X:mnist.test.images,Y:mnist.test.labels}))
结果截图: