本讲从二个方面阐述:
- 数据清理原因和现象
- 数据清理代码解析
Spark Core从技术研究的角度讲 对Spark Streaming研究的彻底,没有你搞不定的Spark应用程序。
Spark Streaming一直在运行,不断计算,每一秒中在不断运行都会产生大量的累加器、广播变量,所以需要对对象及
元数据需要定期清理。每个batch duration运行时不断触发job后需要清理rdd和元数据。Clinet模式
可以看到打印的日志,从文件日志也可以看到清理日志内容。
现在要看其背后的事情:
Spark运行在jvm上,jvm会产生对象,jvm需要对对象进行回收工作,如果
我们不管理gc(对象产生和回收),jvm很快耗尽。现在研究的是Spark Streaming的Spark GC
。Spark Streaming对rdd的数据管理、元数据管理相当jvm对gc管理。
数据、元数据是操作DStream时产生的,数据、元数据的回收则需要研究DStream的产生和回收。
看下DStream的继承结构:
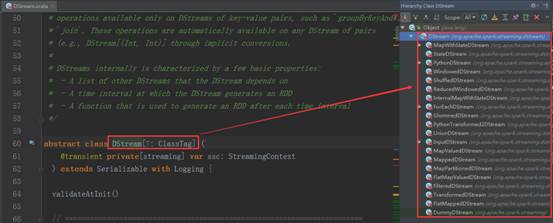
接收数据靠InputDStream,数据输入、数据操作、数据输出,整个生命周期都是基于DStream构建的;得出结论:DStream负责rdd的生命周期,rrd是DStream产生的,对rdd的操作也是对DStream的操作,所以不断产生batchDuration的循环,所以研究对rdd的操作也就是研究对DStream的操作。
源码分析:
通过对DirectKafkaInputDStream 会产生kafkardd:
override def compute(validTime: Time): Option[KafkaRDD[K, V, U, T, R]] = {
val untilOffsets = clamp(latestLeaderOffsets(maxRetries))
val rdd = KafkaRDD[K, V, U, T, R](
context.sparkContext, kafkaParams, currentOffsets, untilOffsets, messageHandler)
// Report the record number and metadata of this batch interval to InputInfoTracker.
val offsetRanges = currentOffsets.map { case (tp, fo) =>
val uo = untilOffsets(tp)
OffsetRange(tp.topic, tp.partition, fo, uo.offset)
}
val description = offsetRanges.filter { offsetRange =>
// Don't display empty ranges.
offsetRange.fromOffset != offsetRange.untilOffset
}.map { offsetRange =>
s"topic: ${offsetRange.topic} partition: ${offsetRange.partition} " +
s"offsets: ${offsetRange.fromOffset} to ${offsetRange.untilOffset}"
}.mkString("
")
// Copy offsetRanges to immutable.List to prevent from being modified by the user
val metadata = Map(
"offsets" -> offsetRanges.toList,
StreamInputInfo.METADATA_KEY_DESCRIPTION -> description)
val inputInfo = StreamInputInfo(id, rdd.count, metadata)
ssc.scheduler.inputInfoTracker.reportInfo(validTime, inputInfo)
currentOffsets = untilOffsets.map(kv => kv._1 -> kv._2.offset)
Some(rdd)
}
foreachRDD会触发ForEachDStream:
/**
* An internal DStream used to represent output operations like DStream.foreachRDD.
* @param parent Parent DStream
* @param foreachFunc Function to apply on each RDD generated by the parent DStream
* @param displayInnerRDDOps Whether the detailed callsites and scopes of the RDDs generated
* by `foreachFunc` will be displayed in the UI; only the scope and
* callsite of `DStream.foreachRDD` will be displayed.
*/
private[streaming]
class ForEachDStream[T: ClassTag] (
parent: DStream[T],
foreachFunc: (RDD[T], Time) => Unit,
displayInnerRDDOps: Boolean
) extends DStream[Unit](parent.ssc) {
override def dependencies: List[DStream[_]] = List(parent)
override def slideDuration: Duration = parent.slideDuration
override def compute(validTime: Time): Option[RDD[Unit]] = None
override def generateJob(time: Time): Option[Job] = {
parent.getOrCompute(time) match {
case Some(rdd) =>
val jobFunc = () => createRDDWithLocalProperties(time, displayInnerRDDOps) {
foreachFunc(rdd, time)
}
Some(new Job(time, jobFunc))
case None => None
}
}
}
再看DStream源码foreachRDD:
/**
* Apply a function to each RDD in this DStream. This is an output operator, so
* 'this' DStream will be registered as an output stream and therefore materialized.
* @param foreachFunc foreachRDD function
* @param displayInnerRDDOps Whether the detailed callsites and scopes of the RDDs generated
* in the `foreachFunc` to be displayed in the UI. If `false`, then
* only the scopes and callsites of `foreachRDD` will override those
* of the RDDs on the display.
*/
private def foreachRDD(
foreachFunc: (RDD[T], Time) => Unit,
displayInnerRDDOps: Boolean): Unit = {
new ForEachDStream(this,
context.sparkContext.clean(foreachFunc, false), displayInnerRDDOps).register()
}
/**
* Get the RDD corresponding to the given time; either retrieve it from cache
* or compute-and-cache it.
*/
private[streaming] final def getOrCompute(time: Time): Option[RDD[T]] = {
// If RDD was already generated, then retrieve it from HashMap,
// or else compute the RDD
generatedRDDs.get(time).orElse {
// Compute the RDD if time is valid (e.g. correct time in a sliding window)
// of RDD generation, else generate nothing.
if (isTimeValid(time)) {
val rddOption = createRDDWithLocalProperties(time, displayInnerRDDOps = false) {
// Disable checks for existing output directories in jobs launched by the streaming
// scheduler, since we may need to write output to an existing directory during checkpoint
// recovery; see SPARK-4835 for more details. We need to have this call here because
// compute() might cause Spark jobs to be launched.
PairRDDFunctions.disableOutputSpecValidation.withValue(true) {
compute(time)
}
}
rddOption.foreach { case newRDD =>
// Register the generated RDD for caching and checkpointing
if (storageLevel != StorageLevel.NONE) {
newRDD.persist(storageLevel)
logDebug(s"Persisting RDD ${newRDD.id} for time $time to $storageLevel")
}
if (checkpointDuration != null && (time - zeroTime).isMultipleOf(checkpointDuration)) {
newRDD.checkpoint()
logInfo(s"Marking RDD ${newRDD.id} for time $time for checkpointing")
}
generatedRDDs.put(time, newRDD)
}
rddOption
} else {
None
}
}
}
DStream随着时间进行,不断在内存数据结构,generatorRDD中时间窗口和窗口下的rdd实例,
按照batchDuration存储rdd以及删除掉rdd的。有时候会调用DStream的cache操作,cache就是persist操作,其实是对rdd的cache操作。
Rdd本身释放,产生rdd有数据源和元数据,释放rdd时山方面都需要考虑。数据周期性产生和周期性释放,需要找到时钟,需要找jobGenerator下的时钟:
private val timer = new RecurringTimer(clock, ssc.graph.batchDuration.milliseconds,
longTime => eventLoop.post(GenerateJobs(new Time(longTime))), "JobGenerator")
根据时间发给eventloop,这边receive的时候不断的有generatorjobs产生:
/** Generate jobs and perform checkpoint for the given `time`. */
private def generateJobs(time: Time) {
// Set the SparkEnv in this thread, so that job generation code can access the environment
// Example: BlockRDDs are created in this thread, and it needs to access BlockManager
// Update: This is probably redundant after threadlocal stuff in SparkEnv has been removed.
SparkEnv.set(ssc.env)
Try {
jobScheduler.receiverTracker.allocateBlocksToBatch(time) // allocate received blocks to batch
graph.generateJobs(time) // generate jobs using allocated block
} match {
case Success(jobs) =>
val streamIdToInputInfos = jobScheduler.inputInfoTracker.getInfo(time)
jobScheduler.submitJobSet(JobSet(time, jobs, streamIdToInputInfos))
case Failure(e) =>
jobScheduler.reportError("Error generating jobs for time " + time, e)
}
eventLoop.post(DoCheckpoint(time, clearCheckpointDataLater = false))
}
短短几行代码把整个作业的生命周期处理的清清楚楚。
/** Processes all events */
private def processEvent(event: JobGeneratorEvent) {
logDebug("Got event " + event)
event match {
case GenerateJobs(time) => generateJobs(time)
case ClearMetadata(time) => clearMetadata(time)
case DoCheckpoint(time, clearCheckpointDataLater) =>
doCheckpoint(time, clearCheckpointDataLater)
case ClearCheckpointData(time) => clearCheckpointData(time)
}
}
看下clearMetadata方法:
/** Clear DStream metadata for the given `time`. */
private def clearMetadata(time: Time) {
ssc.graph.clearMetadata(time)
// If checkpointing is enabled, then checkpoint,
// else mark batch to be fully processed
if (shouldCheckpoint) {
eventLoop.post(DoCheckpoint(time, clearCheckpointDataLater = true))
} else {
// If checkpointing is not enabled, then delete metadata information about
// received blocks (block data not saved in any case). Otherwise, wait for
// checkpointing of this batch to complete.
val maxRememberDuration = graph.getMaxInputStreamRememberDuration()
jobScheduler.receiverTracker.cleanupOldBlocksAndBatches(time - maxRememberDuration)
jobScheduler.inputInfoTracker.cleanup(time - maxRememberDuration)
markBatchFullyProcessed(time)
}
}
Inputinfotracker里面是保存了元数据。
defclearMetadata(time: Time) {
logDebug("Clearing metadata for time " + time)
this.synchronized {
outputStreams.foreach(_.clearMetadata(time))
}
logDebug("Cleared old metadata for time " + time)
}
清理完成后输出日志。
有很多类型数据输出,先清理outputds的内容,有不同的outputds,其实就是foreachds。
继续跟踪ds类的清理方法:
/**
* Clear metadata that are older than `rememberDuration` of this DStream.
* This is an internal method that should not be called directly. This default
* implementation clears the old generated RDDs. Subclasses of DStream may override
* this to clear their own metadata along with the generated RDDs.
*/
private[streaming] def clearMetadata(time: Time) {
val unpersistData = ssc.conf.getBoolean("spark.streaming.unpersist", true)
val oldRDDs = generatedRDDs.filter(_._1 <= (time - rememberDuration))//batchdration的倍数
logDebug("Clearing references to old RDDs: [" +
oldRDDs.map(x => s"${x._1} -> ${x._2.id}").mkString(", ") + "]")
generatedRDDs --= oldRDDs.keys
if (unpersistData) {
logDebug("Unpersisting old RDDs: " + oldRDDs.values.map(_.id).mkString(", "))
oldRDDs.values.foreach { rdd =>
rdd.unpersist(false)
// Explicitly remove blocks of BlockRDD
rdd match {
case b: BlockRDD[_] =>
logInfo("Removing blocks of RDD " + b + " of time " + time)
b.removeBlocks()
case _ =>
}
}
}
logDebug("Cleared " + oldRDDs.size + " RDDs that were older than " +
(time - rememberDuration) + ": " + oldRDDs.keys.mkString(", "))
dependencies.foreach(_.clearMetadata(time))
}
除了清理rdd还需要清理元数据。
随着时间推移,不断收到清理的消息,不用担心driver内存问题。
接下来需要删除RDD:
/**
* Remove the data blocks that this BlockRDD is made from. NOTE: This is an
* irreversible operation, as the data in the blocks cannot be recovered back
* once removed. Use it with caution.
*/
private[spark] def removeBlocks() {
blockIds.foreach { blockId =>
sparkContext.env.blockManager.master.removeBlock(blockId)
}
_isValid = false
}
基于rdd肯定背blockmanager,需要删除block的话需要告诉blockmanager master来做。
接下来需要处理depanedcied foreach需要把依赖的父ds都会被清理掉。
最后一个问题:清理是在什么时候被触发的?
根据源码分析,作业产生的jobGenerator类中有下面的方法:
/**
* Callback called when a batch has been completely processed.
*/
def onBatchCompletion(time: Time) {
eventLoop.post(ClearMetadata(time))
}
/**
* Callback called when the checkpoint of a batch has been written.
*/
def onCheckpointCompletion(time: Time, clearCheckpointDataLater: Boolean) {
if (clearCheckpointDataLater) {
eventLoop.post(ClearCheckpointData(time))
}
}
每个batchDuration处理完成后都会被回调、发消息,checkpoint完成之后也会调用checkpointdata,需要从作业运行来分析:JobScheduler类下的jobHandler方法:private def processEvent(event: JobSchedulerEvent) {
try {
event match {
case JobStarted(job, startTime) => handleJobStart(job, startTime)
case JobCompleted(job, completedTime) => handleJobCompletion(job, completedTime)
case ErrorReported(m, e) => handleError(m, e)
}
} catch {
case e: Throwable =>
reportError("Error in job scheduler", e)
}
}
private def handleJobCompletion(job: Job, completedTime: Long) {
val jobSet = jobSets.get(job.time)
jobSet.handleJobCompletion(job)
job.setEndTime(completedTime)
listenerBus.post(StreamingListenerOutputOperationCompleted(job.toOutputOperationInfo))
logInfo("Finished job " + job.id + " from job set of time " + jobSet.time)
if (jobSet.hasCompleted) {
jobSets.remove(jobSet.time)
jobGenerator.onBatchCompletion(jobSet.time)
logInfo("Total delay: %.3f s for time %s (execution: %.3f s)".format(
jobSet.totalDelay / 1000.0, jobSet.time.toString,
jobSet.processingDelay / 1000.0
))
listenerBus.post(StreamingListenerBatchCompleted(jobSet.toBatchInfo))
}
job.result match {
case Failure(e) =>
reportError("Error running job " + job, e)
case _ =>
}
}
完成后调用onBatchCompletion:
/**
* Callback called when a batch has been completely processed.
*/
def onBatchCompletion(time: Time) {
eventLoop.post(ClearMetadata(time))
}
总结:
Spark Streaming在batchDuration处理完成后都会对产生的信息做清理,对输出DStream清理、依赖关系进行清理、清理默认也会清理rdd数据信息、元数据清理。
感谢王家林老师的知识分享
Spark Streaming发行版笔记16
新浪微博:http://weibo.com/ilovepains
微信公众号:DT_Spark
博客:http://blog.sina.com.cn/ilovepains
手机:18610086859
QQ:1740415547
邮箱:18610086859@vip.126.com