一:推文
Kafka学习之路 (一)Kafka的简介
Kafka学习之路 (二)Kafka的架构
Kafka学习之路 (三)Kafka的高可用
Kafka学习之路 (四)Kafka的安装
Kafka学习之路 (五)Kafka在zookeeper中的存储
二:Kafka架构原理
(一)Kafka应用场景
Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
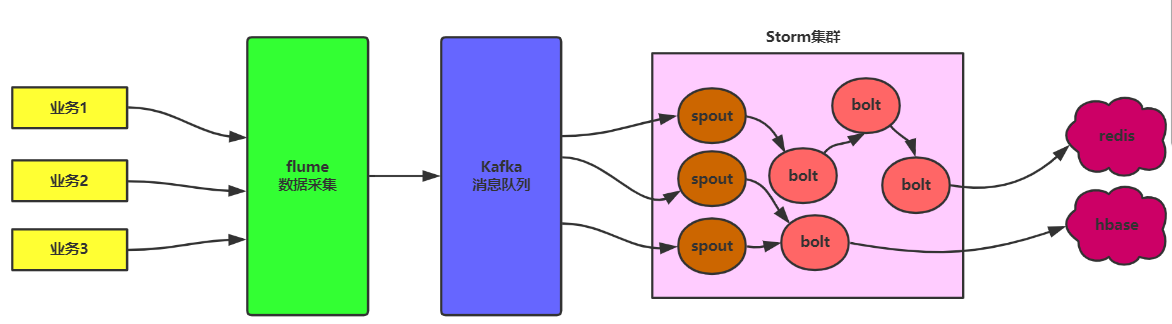
主要应用场景是:日志收集系统和消息系统。
(二)Kafka集群系统
Kafka是一个分布式集群,内部有很多server组成,这些server称为blocker(中间商),blocker管理数据时,会对数据进行分区操作。
因为一个Kafka集群会对很多子系统进行服务,不同子系统发送的消息需要进行区分,则可以通过topics主题进行区分。 而每一个topic中的消息都会进行分区,例如:partition1、partition2.....通过分区可以进行负载均衡。将各个分区可以放入到不同的server中,可以进行负载均衡。
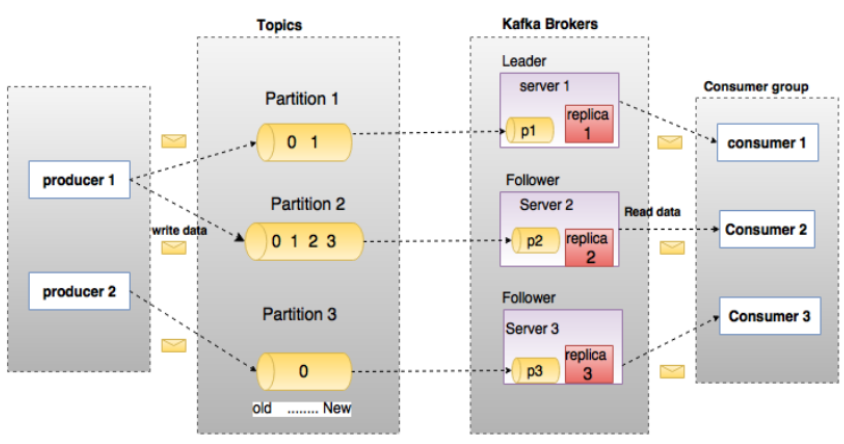
注意:一个生产者可以在topics中设置多个分区,例如producer 1
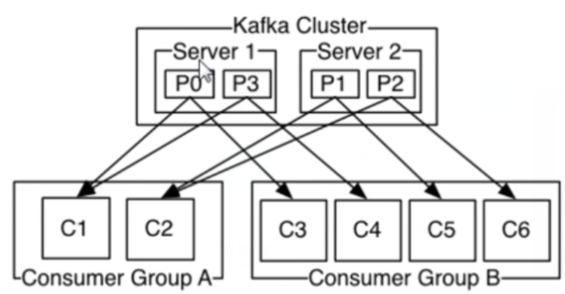
1:kafka是一个分布式的消息缓存系统 2:kafka集群中的服务器都叫做broker 3:kafka有两类客户端,一类叫producer(消息生产者),一类叫做consumer(消息消费者),客户端和broker服务器之间采用tcp协议连接 4:kafka中不同业务系统的消息可以通过topic进行区分,而且每一个消息topic都会被分区,以分担消息读写的负载 5:每一个分区都可以有多个副本,以防止数据的丢失 6:某一个分区中的数据如果需要更新,都必须通过该分区所有副本中的leader来更新 7:消费者可以分组,比如有两个消费者组A和B,共同消费一个topic:order_info,A和B所消费的消息不会重复 比如 order_info 中有100个消息,每个消息有一个id,编号从0-99,那么,如果A组消费0-49号,B组就消费50-99号 8:消费者在具体消费某个topic中的消息时,可以指定起始偏移量(例如:在消费某个消息时,中途故障,那么下一次可以指定起始偏移量,接着之前的数据下载)
三:Kafka安装
(一)需要提前安装zookeeper,进行集群协调
(二)集群安装
1、解压 2、修改server.properties broker.id=1 注意:每一个节点的id都应该唯一 zookeeper.connect=hadoopH5:2181,hadoopH6:2181,hadoopH7:2181 3、将zookeeper集群启动 4、在每一台节点上启动broker bin/kafka-server-start.sh config/server.properties
补充:在4中,启动集群以后,可以使用zookeeper进行节点查看
补充:可以使用 1>/dev/null 2>&1 &将进程启动的标准输出定义到null中,不进行输出,把标准错误同样输出到null.最后使用&可以后台启动
zkCli.sh
ls /brokers/ids
![]()
启动进程查看:
![]()
(三)在集群中创建topic
5、在kafka集群中创建一个topic bin/kafka-topics.sh --create --zookeeper hadoopH5:2181 --replication-factor 3 --partitions 1 --topic order
注意:副本数不能大于启动节点数。我们这里启动3节点,所有设置副本3.分区1(分区越少,顺序性越强)
![]()
可以使用 bin/kafka-topics.sh --list --zookeeper hadoopH5:2181来查看集群topic
![]()
(四)使用生产者向Kafka的topic写入消息
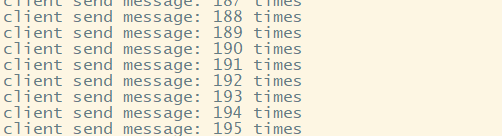
6、用一个producer向某一个topic中写入消息 bin/kafka-console-producer.sh --broker-list hadoopH5:9092 --topic order

开启后,每输入一行数据,就是一个消息。
(五)使用消费者进行消息读取
7、用一个comsumer从某一个topic中读取信息 bin/kafka-console-consumer.sh --zookeeper hadoopH5:2181 --from-beginning --topic order

生产和消费都是同步的。from-beginning设置偏移量从头开始,即读取全部消息。若是不设置,则从当前时刻开始读取消息
(六)分区状态查看
8、查看一个topic的分区及副本状态信息 bin/kafka-topics.sh --describe --zookeeper hadoopH5:2181 --topic order

总体信息:Topic:order PartitionCount:1 ReplicationFactor:3 Configs: 详细信息:Topic: order Partition: 0 分区号 Leader: 2 2号blocker是leader Replicas: 2,3,1 副本所在blocker位置 Isr: 2,3,1
四:Kafka客户端编写
(一)编写生产者
package cn.storm.kafka; import java.util.Properties; import kafka.javaapi.producer.Producer; import kafka.producer.KeyedMessage; import kafka.producer.ProducerConfig; public class ProducerDemo { public static void main(String[] args) throws InterruptedException { Properties props = new Properties(); props.put("zk.connect", "hadoopH5:2181,hadoopH6:2181,hadoopH7:2181"); //指定zookeeper集群信息 props.put("metadata.broker.list", "hadoopH5:9092,hadoopH6:9092,hadoopH7:9092"); //指定broker集群信息 props.put("serializer.class","kafka.serializer.StringEncoder"); //设置消息编码类型,同下面泛型中参数一致 ProducerConfig config = new ProducerConfig(props); Producer<String, String> producer = new Producer<String, String>(config); //泛型指定了topics和消息类型 //发送业务消息 //1.读取文件 2.读取内存数据库 3.读取socket端口数据 for(int i=1;i<=1000;i++) { Thread.sleep(500);//休眠半秒 producer.send(new KeyedMessage<String, String>("order", "client send message: "+i+" times")); } } }
(二)消费者客户端编写
package cn.storm.kafka; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.Properties; import kafka.consumer.Consumer; import kafka.consumer.ConsumerConfig; import kafka.consumer.KafkaStream; import kafka.javaapi.consumer.ConsumerConnector; import kafka.message.MessageAndMetadata; public class ConsumerDemo { private static final String topic = "order"; //设置topic private static final Integer threads = 1; //设置线程数 public static void main(String[] args) { Properties props = new Properties(); props.put("zookeeper.connect", "hadoopH5:2181,hadoopH6:2181,hadoopH7:2181"); props.put("group.id", "11"); //设置组id props.put("auto.offset.reset", "smallest"); //偏移量重新设置,从头开始 ConsumerConfig config = new ConsumerConfig(props); ConsumerConnector consumer = Consumer.createJavaConsumerConnector(config); Map<String,Integer> topicCountMap =new HashMap<String, Integer>(); topicCountMap.put(topic, threads); //可以添加多个topic主题进行查询 Map<String,List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCountMap); //获取的消息流也是Map类型(含多个,按topic区分) List<KafkaStream<byte[], byte[]>> streams= consumerMap.get(topic); //获取一个topic的消息流,消息流可能含有多个分区partition //获取消息流,是阻塞式的 for(final KafkaStream<byte[], byte[]> kafkaStream: streams) { new Thread(new Runnable() { //每一个分区,我们采用一个线程处理,互不干扰 @Override public void run() { for(MessageAndMetadata<byte[], byte[]> mm:kafkaStream) { String msg = new String(mm.message()); System.out.println(msg); } } }).start(); } } }

五:Kafka和storm联合使用
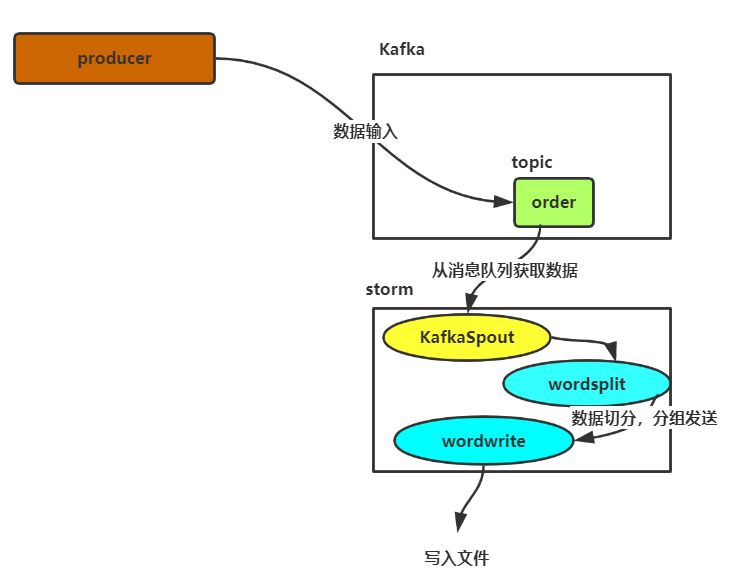
(一)需要引入storm-kafka对应的jar包
![]()
(二)注意:导入Kafka的lib中jar包时,不要导入zookeeper的jar包,不然会和我们自己安装的zookeeper冲突
(三)代码编写

1.WordSplitBolt
package cn.storm.stormkafka; import org.apache.commons.lang.StringUtils; import backtype.storm.topology.BasicOutputCollector; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseBasicBolt; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Tuple; import backtype.storm.tuple.Values; public class WordSplitBolt extends BaseBasicBolt{ @Override public void execute(Tuple tuple, BasicOutputCollector collector) { String line = tuple.getString(0); //获取一行数据 String[] words=line.split(" "); for(String word:words) { word = word.trim(); //去除两边空格 if(StringUtils.isNotBlank(word)) { word = word.toLowerCase(); //转小写 collector.emit(new Values(word)); } } } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("word")); } }
2.WordWriteBolt
package cn.storm.stormkafka; import java.io.FileWriter; import java.io.IOException; import java.util.Map; import java.util.UUID; import backtype.storm.task.TopologyContext; import backtype.storm.topology.BasicOutputCollector; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseBasicBolt; import backtype.storm.tuple.Tuple; public class WordWriteBolt extends BaseBasicBolt{ private FileWriter fw = null; @Override public void prepare(Map stormConf, TopologyContext context) { try { fw = new FileWriter("E:\storm-kafka\"+"wordcount"+UUID.randomUUID()); } catch (IOException e) { e.printStackTrace(); } } @Override public void execute(Tuple tuple, BasicOutputCollector controller) { String word = tuple.getString(0); try { fw.write(word); fw.write(" "); fw.flush(); //从内存刷新到文件中 } catch (IOException e) { e.printStackTrace(); } } @Override public void declareOutputFields(OutputFieldsDeclarer arg0) { // TODO Auto-generated method stub } }
3.KafkaTopo
package cn.storm.stormkafka; import backtype.storm.Config; import backtype.storm.LocalCluster; import backtype.storm.StormSubmitter; import backtype.storm.generated.AlreadyAliveException; import backtype.storm.generated.InvalidTopologyException; import backtype.storm.spout.SchemeAsMultiScheme; import backtype.storm.topology.TopologyBuilder; import backtype.storm.tuple.Fields; import storm.kafka.BrokerHosts; import storm.kafka.KafkaSpout; import storm.kafka.SpoutConfig; import storm.kafka.ZkHosts; public class KafkaTopo { public static void main(String[] args) throws AlreadyAliveException, InvalidTopologyException { String topic = "order"; //设置topic String zkRoot = "/kafka-storm"; //storm是消费者,在zookeeper集群中(zookeeper根目录/kafka-storm)记录一些消费信息,例如topic、数据所在broker String spoutId = "KafkaSpout"; //设置spoutID BrokerHosts brokerHosts = new ZkHosts("hadoopH5:2181,hadoopH6:2181,hadoopH7:2181");//指定zookeeper集群信息,从中获取broker主机信息 SpoutConfig spoutconf = new SpoutConfig(brokerHosts, topic, zkRoot, spoutId);//将配置信息封装到SpoutConfig中 spoutconf.forceFromStart=true;//设置读取数据偏移量 /* * scheme:将kafka传到spout里的数据格式进行转化. record->tuple * mapper:将storm传到kafka的数据格式进行转化.tuple->record */ spoutconf.scheme = new SchemeAsMultiScheme(new MessageScheme()); //配置消息格式,自定义类 TopologyBuilder builder = new TopologyBuilder(); //设置一个spout用来从kaflka消息队列中读取数据并发送给下一级的bolt组件,此处用的spout组件并非自定义的,而是storm中已经开发好的KafkaSpout builder.setSpout(spoutId, new KafkaSpout(spoutconf)); //读取到Kafka消息,放入到之前配置文件中指定的spoutid中的spout builder.setBolt("wordsplit", new WordSplitBolt(),4).shuffleGrouping(spoutId); builder.setBolt("wordwrite", new WordWriteBolt(),4).fieldsGrouping("wordsplit",new Fields("word")); Config conf = new Config(); conf.setNumAckers(0); conf.setNumWorkers(4); conf.setDebug(false); //LocalCluster用来将topology提交到本地模拟器运行,方便开发调试 LocalCluster cluster = new LocalCluster(); cluster.submitTopology("WordCount", conf, builder.createTopology()); //提交topology到storm集群中运行 //StormSubmitter.submitTopology("WordCount", conf, builder.createTopology()); } }
4.MessageScheme
package cn.storm.stormkafka; import java.io.UnsupportedEncodingException; import java.util.List; import backtype.storm.spout.Scheme; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Values; public class MessageScheme implements Scheme { /** * 创建一个类的时候如果需要实现 java.io.Serializable 接口的时候,往往需要设置 serialVersionUID。 */ private static final long serialVersionUID = 6417356846166053480L; @Override //进行反序列化操作 public List<Object> deserialize(byte[] bytes) { try { String msg=new String(bytes,"UTF-8"); return new Values(msg); //从kafka中获取数据后,返回tuple类型给spout } catch (UnsupportedEncodingException e) { // TODO Auto-generated catch block e.printStackTrace(); } return null; } @Override public Fields getOutputFields() { return new Fields("msg"); } }
(四)如果上传到服务器运行,调试问题
https://www.jianshu.com/p/70c3a7f56386
(五)本地运行