一、函数的初识
函数的定义:函数最主要的目的是封装一个功能,一个函数就是一个功能
定义函数的格式:
def 函数名():
函数体
def my_len():
count = 0
s1 = 'hahahahaha'
for i in s1:
count += 1
def 关键字,定义函数
函数名: 命名跟变量的命名相似,注重描述性
函数体:代码块
执行函数的格式:
函数名()
my_len() # 执行函数(函数的执行者)
函数的优点:① 减少代码的重复率 ② 增强代码的阅读行(根据函数名的描述知道其函数的功能)
工作中,函数中尽量不要出现print(print用于调试时使用)
二、函数的返回值 return
return的作用:
① 函数中如果遇到return,直接结束函数
② 给函数的执行者返回值 ( 函数的执行者即函数名() )
return 无返回值,默认会返回None
def my_len():
pass
print(my_len())
# 结果
None
return 单个值,返回的值的类型就是值的数据类型,原封不动的返回
def fun():
return 'haha'
print(fun(),type(fun()))
# 结果
haha <class 'str'>
return 多个值,返回的是由值组成的元素,所有的值都是元组的一个元素
def fun():
return 1,'ha',[1,2,'a']
print(fun(),type(fun()))
# 结果
(1, 'ha', [1, 2, 'a']) <class 'tuple'>
三、三元运算
三元运算:只针对与简单的 if...else 结构才能使用,不能有 elif
① 为真的结果 if 判定条件 else 为假时的结果
def num_max(x,y):
return x if x > y else y # 假如x>y就返回x,否则返回y
print(num_max(100,105))
# 结果
105
② 判断条件 and 为真的结果 or 为假的结果
def num_max(x,y):
return x > y and x or y # 假如x>y成立就返回and后面的,否则返回or后面的
print(num_max(10,5))
# 结果
10
四、函数的参数
Python中对函数参数的传递采用 传引用 的方式,即实参和形参都是引用,它们指向同一个对象实体(换言之,即形参是实参的浅拷贝)
def test_len(s):
count = 0
for i in s:
count += 1
return count
test_len('abcdefgh')
以上的过程称为传递参数,'abcdefgh'这个就是调用函数时从传递的参数,传递参数可以传递多个参数
函数的参数分为形参与实参,形参是形式参数,实参是实际参数
形参: 在定义函数的时候它只是一个形式,表示这里有参数。例如:s
实参:'已经定义从初始化好的数据,实际要交给函数的内容。例如:'abcdefgh'
五、实参
调用函数时,可以指定两种类型的参数:位置参数和关键字参数
① 位置参数:形参和实参必须按照个数和顺序一一对应
def num_max(x,y):
return x,y
num_max(10,20)
② 关键字参数
def num_max(x,y,z):
return x,y,z
ret = num_max(y=20,z=100,x=10)
print(ret)
# 结果
(10, 20, 100)
③ 位置参数、关键字参数混合使用
注意:关键字参数一定要放在位置参数的后面,并且与形参一一对应
def num_max(a,b,x,y):
return a,b,x,y
ret = num_max(5,10,y=200,x=100)
print(ret)
# 结果
(5, 10, 100, 200)
六、形参
只有一个参数时,变量用argv
① 位置参数:按照顺序一一对应
def fun(x,y,z):
return x,y,z
② 默认参数:
如果形参设置了默认参数,该值被传递了就使用传递的值,如果没传递值,就是使用默认的值。
给其传值,会将原默认参数覆盖掉,不传值不报错,使用的时默认值
默认参数一般设置的是不可变数据类型(str、int、bool)
def fun(x,y=1):
return x*y
fun(5) # 只传递给x,使用y的默认值
fun(5,2) # x和y都传递,不使用yde默认值
默认参数设置的是可变数据类型,每次使用他始终指向的是同一个,都是同一个内存地址
def fun(x,li = []):
li.append(x)
return li
l1 = fun(5)
print(l1,id(l1))
l2 = fun(10) # 在li的列表上追加值,原本的值还存在,它们都是指向同一个内存地址
print(l2,id(l2))
# 结果
[5] 1798941451208
[5, 10] 1798941451208
七、动态参数
为了拓展,对于传入的实参数量不固定,需要万能参数,即动态参数
*args
**kwargs
在函数定义时,在 *args为位置参数,起聚合的作用。
*args是聚合的意思,将元素集合到元组中,将所有实参的位置参数聚合到一个元组,并将这个元组赋值给args
def func(*args):
return args
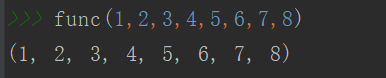
**kwargs 将关键字参数聚合到字典中
def func(**kwargs):
return kwargs

*args是可变参数,args接收的是一个tuple;
**kw是关键字参数,kw接收的是一个dict。
*的魔性用法:
① 在函数的定义时,在 *为位置参数,**为关键字参数,起到聚合的作用
def func(*args):
return args
>>>func(1,2,3,'a','b','c')
(1, 2, 3, 'a', 'b', 'c')
def func(**kwargs):
return kwargs
>>>func(a=1,b=2,c=3)
{'a': 1, 'b': 2, 'c': 3}
② 在函数的调用(执行)时,在 *位置参数,**关键字参数,起到打散的作用
def func(*args):
return args
>>>func(*(1,2,3),*['a','b','c'])
(1, 2, 3, 'a', 'b', 'c')
def func(**kwargs):
return kwargs
>>>func(**{'a':1,'b':2},**{'c':3,'d':5})
{'a': 1, 'b': 2, 'c': 3, 'd': 5}
位置参数*args 与 默认参数的位置关系:位置参数*args 一定要在默认参数的前面,否则默认参数无意义,会被覆盖
① 位置参数 *args 默认参数
② 位置参数 *args 默认参数 **kwargs
def func(a,b,*args,z=0,**kwargs):
print(a,b)
print(args)
print(z)
print(kwargs)
>>>func(13,14,'a',2,3,6,7,8,z='yes',x=1,y=2)
13 14
('a', 2, 3, 6, 7, 8)
yes
{'x': 1, 'y': 2}
八、名称空间,作用域,取值顺序、加载顺序
名称空间存储的是变量与值内存地址的对应关系,
命名空间是一个字典的实现,键为变量名,值是变量对应的值。
程序从上到下执行,遇到变量和值,会创建名称空间,会存储变量与值内存地址的关系;当遇到函数,将函数和函数体的对应关系加载到内存,但是代码不加载,直到执行函数时,加载临时名称空间。
当函数调用时,会临时开辟一块空间,存储函数里的变量和值的关系,函数执行完时名称空间就会消失
名称空间分三种:
① 全局命名空间(除函数以外)
② 局部命名空间 (临时)
③ 内置命名空间 len,input,print等内部方法,类
作用域:
① 全局作用域(包含全局名称空间和内置名称空间的所有内容)
② 局部作用域 局部名称空间
取值顺序:
在局部调用:局部命名空间->全局命名空间->内置命名空间
在全局调用:全局命名空间->内置命名空间
综上所述,在找寻变量时,从小范围,一层一层到大范围去找寻。
就近原则;单向从小到大范围;
先从局部名称空间找,没有就到全局名称空间找,再没有就到内置名称空间找。
LEGB:
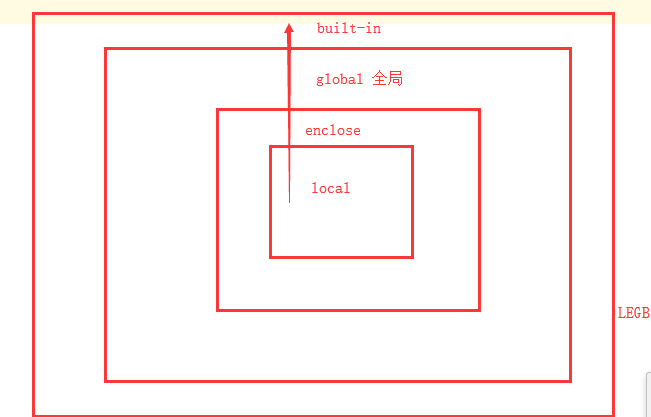
加载顺序:
内置名称空间先加载到内存,全局名称空间加载到内存(当程序开始执行时),局部名称空间(当函数调用的时候)
内置命名空间(程序运行前加载)->全局命名空间(程序运行中:从上到下加载)->局部命名空间(程序运行中:调用时才加载)
取值顺序和加载顺序相反
九、global和nonlocal
global :
局部名称空间,对全局名称空间的变量可以引用,但是不能修改;全局名称空间和临时名称空间是两个值
a = 1
def fun():
a = 2
print(a)
>>>fun()
2
>>>a
1
在局部空间对变量的值进行修改,解释器会认为变量在局部命名空间已经定义了,如果局部命名空间没存在该变量会报错
为了解决该问题,需要使用关键字global(一般在局部命名空间定义)
a = 1
def fun():
global a
a += 2
return a
>>>fun()
3
① 在局部命名空间声明一个全局变量,即在函数里定义全局变量,将局部命名空间的变量搬到全局命名空间里
② 在局部命名空间可以对全局命名空间的变量进行修改
global关键字用来在函数或其他局部作用域中使用全局变量。但是如果不修改全局变量也可以不使用global关键字。
nonlocal
nonlocal关键字用来在函数或其他作用域中使用外层(非全局)变量。
用于子函数对父函数的变量进行修改。
nonlocal只能操作局部命名空间的变量,global操作全局命名空间的变量,修改了以后,父函数的变量也改变了,只要不是全局的就可以了
注意:此变量不能是全局变量,要绑定一个局部变量,不能修改全局变量
def fun1():
a = 1
print(a)
def fun2():
nonlocal a
a += 2
print(a)
fun2()
>>>fun1()
1
3
十、函数名的应用
函数名类似于特殊的变量,打印函数名就是打印函数的内存地址
① 函数名就是函数的内存地址
def func():
pass
>>>func
<function func at 0x000001C0BDDAF400>
② 函数名可以作为变量
def func():
print(666)
f = func
f() # f() == func()
③ 函数名可以作为函数的参数传入
def func1():
print(666)
def func2(x):
x() # x() == func1()
func2(func1)
④ 函数名可以当作函数的返回值
def fun1():
def fun2():
print(666)
return fun2
f = fun1() # f = fun2
f() # f() == fun2()
⑤ 函数名可以作为容器类类型的元素
def func1():
print(111)
def func2():
print(222)
def func3():
print(333)
li = [func1,func2,func3]
for i in li:
i() # func1(),func2(),func3()
Python中一切皆对象,函数名就是第一类对象
global() # 将所有全局变量以字典的形式返回
a = 1
b = 2
c = 3
print(globals())
# 结果
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x000001F867E586A0>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'D:/Day11/exercise.py', '__cached__': None, 'a': 1, 'b': 2, 'c': 3}
locals() # 将当前作用域(当前位置)的局部变量以字典的形式返回
def func():
a = 1
b = 2
c = 3
print(locals())
>>>func()
{'c': 3, 'b': 2, 'a': 1}
LEGB
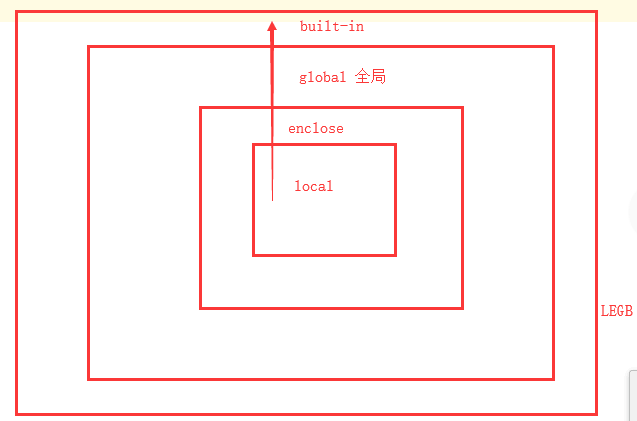
十一、闭包
装饰器的本质就是闭包
面试题:闭包在哪里使用?(爬虫和装饰器会用到闭包)
定义:内层函数对外层函数的变量(非全局变量)的引用,并将函数名返回,这样就形成了闭包。
子函数对父级函数的变量进行引用,并且返回函数名,就是闭包。
函数内部定义的函数称为内部函数,内部函数包含对外部作用域而非全剧作用域变量的引用,该内部函数称为闭包函数
def wraaper():
name = 'xiaoming'
def inner():
print(name)
inner()
return inner
wraaper()
# 结果
xiaoming
函数名.__closure__
name = 'xiaoming'
def wraaper(args):
def inner():
print(args)
inner()
print(inner.__closure__)
return inner
wraaper(name)
# 结果
xiaoming
(<cell at 0x000001CAD4F678B8: str object at 0x000001CAD4E40A30>,)
返回None就不是闭包
name = 'xiaoming'
def wraaper():
def inner():
print(name)
inner()
print(inner.__closure__)
return inner
wraaper()
# 结果
xiaoming
None
闭包的作用:
当程序执行时,遇到了函数执行,它会在内存中开辟一个空间,叫局部名称空间,随着函数的结束而消失。
如果这个函数内部形成了闭包,那么它就不会随着函数的结束而消失,在内存中会一直存在。
十二、迭代器
可迭代对象:对象内部含有__iter__方法就是可迭代对象
可迭代对象:str(字符串)、list(列表)、dict(字典)、tuple(元组)、set(集合)、range()
可以被迭代要满足的要求就叫做可迭代协议。可迭代协议的定义非常简单,就是内部实现了__iter__方法。
判断对象是否可迭代对象的方法:
① 判断__iter__是否在对象的方法中,用dir()
dir() 查看对象内的所有属性和方法
s = 'abcde'
print('__iter__'in dir(s)) # dir() 查看对象内的所有属性和方法
# 结果
True
② isinstance() 判断是否可迭代对象
iisinstance() 判断是否属于某个已知类型,sinstance() 能判断从属于哪种类型,type()判断哪种基本数据类型
from collections import Iterable
li = [1,2,3,4,5]
print(isinstance(li,Iterable)) # 判断对象是否可迭代对象
迭代器:对象内部含有__iter__方法且含有__next__方法就是迭代器
判断对象是否迭代器
① 对象是否含有__iter__和__next__方法
li = [1,2,3,4,5]
print('__iter__' in dir(li))
print('__next__' in dir(li))
# 结果
True
False
② isinstance 判断是否迭代器
from collections import Iterator
dic = {'a':1 ,'b':2 ,'c':3}
print(isinstance(dic,Iterator))
# 结果
False
可迭代对象是不能取值,迭代器就是通过__next__方法可以一个一个取值。
for循环可迭代对象是for循环内部做了优化才能取值,for含有__next__方法,因为可迭代对象没有__next__方法
十三、可迭代对象可以转化为迭代器
转化方法一:__iter__() 方法
from collections import Iterator
dic = {'a':1 ,'b':2 ,'c':3}
itel = dic.__iter__() # 转化为迭代器
print(itel) # 打印是否迭代器
print(isinstance(itel,Iterator)) # 判断对象是否迭代器
# 结果
<dict_keyiterator object at 0x000002049DC76868>
True
转化方法二: iter() 方法
from collections import Iterator
li = ['a','b','c',1,2,3]
itel = iter(li) # 转化为迭代器
print(itel) # 打印是否迭代器
print(isinstance(itel,Iterator)) # 判断对象是否迭代器
# 结果
<list_iterator object at 0x0000016BEA6F7748>
True
十四、迭代器的取值
迭代器的取值方式:通过__next__()方法取值,next一次取一个值
Iterator.__next__()
li = ['a','b','c',1,2,3]
itel = iter(li) # 转化为迭代器
i = itel.__next__() # 通过__next__()方法取值
print(i)
i = itel.__next__() # 通过__next__()方法取值
print(i)
# 结果
a
b
十五、迭代器的好处:
① 可迭代对象不能取值,迭代器是可以取值的
② 迭代器非常节省内存 (__next__()一次就加载一个,加载下一个元素后,上一个元素就会释放掉,跟for的机制相似)
③ 迭代器每次在内存中只会取一个值(一个 next 对应取一个值)
④ 迭代器单向的,不反复,一条路走到头。next下一个就找不到上一个了,只能全部取完再重新找
迭代器的使用:
① 迭代器没索引,为了取值
② 数据量大的时候
for 循环机制:
① 将可迭代对象转化为迭代器
② 调用__next__()方法取值
③ 利用异常处理停止报错
while 循环模拟for循环的机制
s1 = 'abcdefghijklmn'
iter = s1.__iter__()
while 1:
try:
print(iter.__next__())
except StopIteration:
break
文件就是迭代器
十六、迭代器补充
__iter__() 就是 iter(),iter() 调用的就是__iter__()
__next__() 就是 next(),next()调用的就是__next__()
__closure__ 不是判断闭包的方法
十七、生成器
生成器就是自己用python代码写的迭代器,生成器的本质就是迭代器
构建生成器的两种方式:
① 生成器函数
def func(x):
x += 3
print('one')
yield x
x += 5
print('two')
yield x
g = func(5) # func(5) 是生成器对象
print(g.__next__()) # 调用__next__() 方法取值,一次执行一个yield以上的内容
print(g.__next__())
# 结果
one
8
two
13
解释:函数名() 是生成器对象,不执行函数。要想取值需要通过next()方法
一个next对应一个yield,一个next截止到一个yield,yield以上代码都会执行
yield将值返回给 生成器对象.next
② 生成器表达式 即:将列表推导式的中括号[ ]换成括号( )
g = (i for i in range(1,100)) # 生成器表达式,g是生成器对象
print(next(g)) # 生成器通过next(生成器对象)方法取值,一次next取一次值
print(next(g))
print(next(g))
# 结果
1
2
3
yield 和 return 的区别:
return 结束函数,返回给函数的执行者返回值
yield 不会结束函数,会将值返回给生成器对象 ,通过next()方法取值
生成器函数 和 迭代器的区别:
① 自定制的区别
生成器可以随时随地的取值
② 内存级别的区别
迭代器式需要可迭代对象进行转化,可迭代对象非常占内存
生成器是直接创建,不需要转化,从本质上就节省内存
工作总一般用生成器,不会用迭代器
send()
格式:
对象.send()
def func(x):
x += 1
s = yield x
print(s)
x += 1
yield x
g = func(8)
print(next(g)) # 取值
print(g.send('haha')) # 将字符串赋值给上一个yield,即s; 同时取值
# 结果
9
haha
10
send()的作用:
① send()具备next()的功能,对生成器进行取值(执行一个yield)的方法
② send() 可以给上一个yield传一个值
send的陷阱:
① 第一次取值永远是next(),用send()会报错
② 最后一个yield永远得不到send()传的值
def func():
for i in range(10000):
yield i
g = func()
print(next(g))
print(next(g))
print(next(g))
g.close() # 手动关闭生成器函数,后面的调用会直接返回StopIteration异常
print(next(g))
# 结果
0
1
2
print(next(g))
StopIteration
close() 手动关闭生成器函数,后面的调用会直接返回StopIteration异常
十八、列表推导式
模式1:循环模式
格式:[变量(加工后的变量) for 变量 in iterable]
li = [i for i in range(1,10)]
print(li)
# 结果
[1, 2, 3, 4, 5, 6, 7, 8, 9]
模式2:筛选模式[变量(加工后的变量) for 变量 in iterable if 条件]
li = [i for i in range(1,31) if i % 3 == 0]
print(li)
# 结果
[3, 6, 9, 12, 15, 18, 21, 24, 27, 30]
优点:一行解决,优化代码,方便。
缺点:容易着迷
不易排错,不能超过三次循环
总结:列表推导式不能解决所有列表的问题,不要太刻意使用
十九、字典表达式:
格式:{键:值 for 值 in iterable}
mcase = {'a': 10, 'b': 34, 'A': 7, 'Z': 3}
mcase_frequency = {k.lower(): mcase.get(k.lower(), 0) + mcase.get(k.upper(), 0) for k in mcase.keys()}
print(mcase_frequency)
# 结果
{'a': 17, 'b': 34, 'z': 3}
二十、集合推导式
squared = {x**2 for x in [-1,1,2]}
print(squared)
# 结果
{1, 4}
二十一、内置函数
globals() 将全部的全局变量以字典的形式返回
locals() 将当前作用域的所有变量以字典的形式返回
a = 1
b = 2
def func(x):
c = 3
d = 4
print(locals()) # 当前作用域的所有变量以字典的形式返回
print(globals()) # 全局所有的变量以字典的形式返回
func(1)
# 结果
{'d': 4, 'c': 3, 'x': 1}
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x00000221481C87B8>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'D:/骑士计划1期/Day13/review.py', '__cached__': None, 'a': 1, 'b': 2, 'func': <function func at 0x00000221465A2E18>}
eval() 把字符串的引号去除,执行字符串的内容并返回
s = '1 * 2 * 3'
print(eval(s),type(eval(s)))
# 结果
6 <class 'int'>
exec() 执行字符串里的代码,但不返回结果
s = '''
for i in range(3):
print(i)
'''
exec(s)
# 结果
0
1
2
总结:字符串里的结果,需要得到结果就用eval
字符串里是没结果或者是代码流,就用exec
但是两者都不建议使用,除非字符串不做任何的修改
compile() 函数将一个字符串编译为字节代码,通过exec或者eval来执行
语法:compile(source, filename, mode[, flags[, dont_inherit]])
source -- 字符串或者AST(Abstract Syntax Trees)对象。。
filename -- 代码文件名称,如果不是从文件读取代码则传递一些可辨认的值。
mode -- 指定编译代码的种类。可以指定为 exec, eval, single。
flags -- 变量作用域,局部命名空间,如果被提供,可以是任何映射对象。。
flags和dont_inherit是用来控制编译源码时的标志
s = "for i in range(3):print(i)"
com = compile(s,'','exec') # 编译为直接代码对象
exec(com)
# 结果
0
1
2
input() 函数接受一个标准输入数据,返回为 string 类型
用户输入的内容都是str类型,一般后面要添加strip() 去除两端空格
>>>a = input("input:")
input:>? 123
>>>type(a)
<class 'str'>
print() 打印内容
语法:print(self, *args, sep=' ', end=' ', file=None)
sep='' 用来分隔,分割符,默认是空格
end=' ' 打印结尾内容,默认是换行符
file=None 写入的文件对象,默认是None
print('h','e','l','l','o','',sep='-',end='')
print(123)
# 结果
h-e-l-l-o-123
注意:print() 能接收可变参数*args,不能接收关键字参数**kwargs
print() 能打印*args,不能打印**kwargs
print(*[1,2,3]) # 加*将列表打散
print([1,2,3])
# 结果
1 2 3
[1, 2, 3]
id() # 获取对象的内存地址
字符串的ID是等长度的
print(id(1))
print(id('1'))
print(id('abc'))
# 结果
1954570464
1585777572976
1585778570328
hash() # 获取对象的哈希值,
只针对不可变数据类型,可变数据类型是不可哈希的,哈希可变数据类型会报错。
print(hash('abc'))
print(hash('qwertyuioplkjhgfdsazxcvbbnm'))
# 结果
5828273204391538033
7013223571618619052
整型的哈希值跟值一致
print(hash(1))
print(hash(10000))
# 结果
1
10000
open() 函数用于打开一个文件,创建一个 file 对象,相关的方法才可以调用它进行读写
语法:open(file, mode='r', buffering=None, encoding=None, errors=None, newline=None, closefd=True)
__import__ 函数用于动态加载类和函数
help() 函数用于查看函数或模块用途的详细说明
 View Code
View Code
callable 函数用于检查一个对象是否是可调用的。如果返回True,object仍然可能调用失败;但如果返回False,调用对象ojbect绝对不会成功。
print(callable('abc'))
print(callable(str))
# 结果
False
True
dir() 函数不带参数时,返回当前范围内的变量、方法和定义的类型列表;带参数时,返回参数的属性、方法列表。
print(dir())
# 结果
['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__']
print(dir(str))
# 结果
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
range() 函数可创建一个整数列表,一般用在for循环总
for i in range(3):
print(i)
# 结果
0
1
2
python2版本:range(3) -----> [0,1,2] 列表
xrange(3)-----> 迭代器
python3版本:range(3) -----> range(0,3) 可迭代对象
next() 调用__next__()方法,返回迭代器的下一个项目
语法:next(iterator, default=None)
iter() 调用__iter__()方法,函数用来生成迭代器
语法:iter(source, sentinel=None)
bool() 函数用于将给定参数转换为布尔类型,如果没有参数,返回 False。
可以用于and or 的条件判断
b = bool(1 > 3 and 5 < 6 or 7 > 2 and 9 > 0 or 1 > 6)
print(b)
# 结果
True
空参数返回False
print(bool())
# 结果
False
int()
用途:① 将字符串变成数字
a = int('123456')
print(a,type(a))
# 结果
123456 <class 'int'>
② 取整
print(int(5.938576))
# 结果
5
③ base关键字,base代表是进制,前面的内容必须是该进制的数字;将对应进制转换为十进制数
a = int('1100',base=2)
print(a)
# 结果
12
float() 函数用于将整数和字符串转换成浮点数。
print(float(1))
print(float('999'))
# 结果
1.0
999.0
complex 函数用于创建一个值为 real + imag * j 的复数或者转化一个字符串或数为复数。如果第一个参数为字符串,则不需要指定第二个参数。(一般用于科学计算领域)
print(complex(1,2))
print(complex('1'))
# 结果
(1+2j)
(1+0j)
bin() 将十进制数转化为二进制,0b代表二进制
oct() 将十进制数转化为八进制,0o代表二进制
hex() 将十进制数转化为十六进制,0x代表二进制
print(bin(999))
print(oct(999))
print(hex(999))
# 结果
0b1111100111
0o1747
0x3e7
abs() 返回数字的绝对值
一般与排序、比较大小相结合
>>>abs(-99)
99
divmod() 计算除数与被除数的结果,返回商和余数的元组
一般用于项目的分页功能
>>>divmod(100,9)
(11, 1)
round() 保留浮点数的小数位数(四舍五入)
无第二参数默认不保留小数位
>>>round(3.14159265358979323846,6)
3.141593
>>>round(3.14159265358979323846)
3
pow() 返回 xy(x的y次方) 的值,对第三个参数取余
>>>pow(2,3)
8
>>>pow(2,3,3) # 2的3次幂的结果取3取余
2
sum() 对可迭代对象求和
语法:sum(iterable,startnum初始值) 在第二个参数设置初始值
>>>sum([1,2,3])
6
>>>sum([1,2,3],100) # 第二个参数可设置初始值,默认0
106
min() 求可迭代对象的最小值
max() 求可迭代对象的最大值
语法:min(*args, key=None)
key关键字是可调用的对象,例如函数名,将每个元素当参数调用到函数里,默认是按每个元素的第一个值排大小
>>>min([-1,-2,1],key=abs)
-1
dic = {'a':1,'b':2,'c':3}
def func(x): # 定义函数,字典的键值对元组传入
return x[1] # 获取元组的索引返回比较
a = (min(dic.items(),key=func)) # 将字典的键值对形成元组
print(a)
# 结果
('a', 1)
步骤:①它会将iterable的每一个元素当作函数的参数传进去
② 它会按照函数返回值来比较大小
③ 函数会返回的是遍历的元素
list() 将一个可迭代对象转化为列表
字典转为列表:会将所有键转化为列表
字符串转为列表:键每个字符转化为列表
s = 'abc'
dic = {'a':1,'b':2,'c':3}
print(list(s)) # 字符串的字符逐个转为列表
print(list(dic)) # 将字典的键转为列表
# 结果
['a', 'b', 'c']
['a', 'b', 'c']
tuple() 将一个可迭代对象转化为元组
字典转为元组:会将所有键转化为元组
字符串转为元组:键每个字符转化为元组
s = 'abc'
dic = {'a':1,'b':2,'c':3}
print(tuple(s)) # 字符串的字符逐个转为元组
print(tuple(dic)) # 将字典的键转为列表
# 结果
('a', 'b', 'c')
('a', 'b', 'c')
slice() 实现切片对象
制作了切片的规则,方便其他的切片可以调用
调用方法跟切片相似,列表[切片对象]
li = [i for i in range(1,11)]
section = slice(0,9,2)
print(li[section])
# 结果
[1, 3, 5, 7, 9]
str() 将数据类型转化为字符串
s = str(123456789)
print(s,type(s))
# 结果
123456789 <class 'str'>
可以将bytes类型的字符转为str,需要加编码encoding
s = str(b'xe4xbdxa0xe5xa5xbd',encoding='utf-8')
print(s)
# 结果
你好
format() 与数据相关,一般用于科学计算
print(format('右对齐','>20')) # 第一参数是任何类型,第二参数>右对齐和字符串的长度
print(format('左对齐','<20')) # 第一参数是任何类型,第二参数<左对齐和字符串的长度
print(format('居中','^20')) # 第一参数是任何类型,第二参数^居中和字符串的长度
# 结果
右对齐
左对齐
居中
print(format(99,'b')) # 第一参数转化为二进制
print(format(99,'d')) # 第一参数转化为十进制
print(format(99,'o')) # 第一参数转化为八进制
print(format(99,'x')) # 第一参数转化为十六进制,小写字母表示
print(format(99,'X')) # 第一参数转化为十六进制,大写字母表示
print(format(99,'n')) # 第一参数转化为十进制
print(format(99,'c')) # 第一参数转化为unicode字符
print(format('123')) # 默认
# 结果
1100011
99
143
63
63
99
c
123
bytes() 将unicode转化为bytes类型
格式:bytes(字符串,encoding=编码)
s = '哈哈哈'
b = bytes(s,encoding='utf-8')
print(b)
# 结果
b'xe5x93x88xe5x93x88xe5x93x88'
将整型转化为bytes类型(不能加encoding)
b = bytes(10)
print(b,type(b))
# 结果
b'x00x00x00x00x00x00x00x00x00x00' <class 'bytes'>
将可迭代对象转化为bytes类型(不能加encoding)
b = bytes([1,2,3])
print(b,type(b))
# 结果
b'x01x02x03' <class 'bytes'>
bytearray() 返回一个新字节数组
可以将字符串转化为unicode码,通过切片或者索引替换值,改变原来的值,id不变
ret1 = bytearray('你好',encoding='utf-8')
print(id(ret1)) # 2082285910312
print(ret1) # bytearray(b'xe4xbdxa0xe5xa5xbd')
print(ret1[:3]) # bytearray(b'xe4xbdxa0')
ret1[:3] = b'xe6x82xa8' # 通过切片替换值
print(ret1) # bytearray(b'xe6x82xa8xe5xa5xbd')
print(id(ret1)) # 2082285910312
memoryview() 函数返回给定参数的内存查看对象(Momory view)。
所谓内存查看对象,是指对支持缓冲区协议的数据进行包装,在不需要复制对象基础上允许Python代码访问。
v = memoryview(bytearray('abc',encoding='utf-8'))
print(v[0]) # 97
print(v[-1]) # 99
ret2 = memoryview(bytes('你好',encoding='utf-8'))
print(id(ret2)) # 1745227157576
print(ret2) # <memory at 0x0000019657A51048>
print(bytes(ret2).decode('utf-8')) # 你好
ord() 输入字符找该字符编码的位置,unicode的字符编码或者ascii的字符编码
print(ord('好')) # 22909
chr() 输入位置数字找出对应的字符,unicode的字符编码或者ascii的字符编码,跟ord相反
print(chr(22909)) # 好
ascii 函数类似 repr() 函数, 返回一个表示对象的字符串, 但是对于字符串中的非 ASCII 字符则返回通过 repr() 函数使用 x, u 或 U 编码的字符
print(ascii('a')) # 'a'
print(ascii('好')) # 'u597d'
repr() 返回一个对象的string形式
dic = {'baidu':'baidu.com','google':'google.com'}
print(repr(dic),type(repr(dic))) # {'baidu': 'baidu.com', 'google': 'google.com'} <class 'str'>
s = 'google'
print(repr(s)) # 'google'
用途:① 研究json pickle序列化模块,特殊字符串与python字符串的区别
② 格式化输出 %r
print("I'll do a %r search" % ('Google'))
# 结果
I'll do a 'Google' search
dict() 创建一个字典
dic = dict(zip(['a','b','c'],[1,2,3]))
# {'a': 1, 'b': 2, 'c': 3}
set() 创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等
frozenset() 返回一个冻结的集合,冻结后集合不能再添加或删除任何元素。
li = frozenset([1,2,3,4,5])
# frozenset({1, 2, 3, 4, 5})
len() 返回对象中元素的个数
print(len([i for i in range(10)]))
# 10
sorted() 对所有可迭代的对象进行排序操作
通过原对象排序后形成新的对象,对原对象无影响
默认按对象的元素的索引0的元素排序
dic = {'b':1,'c':3,'a':2}
print(sorted(dic))
# 结果
['a', 'b', 'c']
参数key可以添加函数来比较。
dic = {'b':1,'c':3,'a':2}
def func(x): # 字典的是传入键
return dic[x] # 返回键对应的值
print(sorted(dic,key=func,reverse=True)) # 通过函数的返回值来排序,reverse是倒序
# 结果
['c', 'a', 'b']
all() 可迭代对象里的元素全是True才返回True
any() 可迭代对象里的元素有一个True就返回True
li = [1,2,3,'',()]
print(all(li))
print(any(li))
# 结果
False
True
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表
拉链方法:以长度最短的可迭代对象为主,写多个可迭代对象,将纵向组成一个个元组,按顺序排列;组合是一个迭代器。
li = [1,2,3,4,5]
tu = ('a','b','c')
dic = {'i':10,'k':20,'j':30}
print(zip(li,tu,dic)) # <zip object at 0x000002452FD4AFC8> 迭代器
for i in zip(li,tu,dic):
print(i)
# 结果
(1, 'a', 'i')
(2, 'b', 'k')
(3, 'c', 'j')
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象,如果要转换为列表,可以使用 list() 来转换。
类似于筛选模式下的列表推导式
格式:filter(function or None, iterable)
def func(x):return x % 2 == 1
l1 = [i for i in range(10)]
f1 = filter(func,l1)
print(f1) # <filter object at 0x0000026A61F47908> 迭代器
print(list(f1)) # [1, 3, 5, 7, 9]
# 结果
<filter object at 0x0000026A61F47908>
[1, 3, 5, 7, 9]
map() 会根据提供的函数对指定序列做映射。
第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
类似于列表推导式的循环模式,根据提供的函数对指定序列做映射
def func(x):return pow(x,3)
li = [1,3,5,8,9]
l2 = map(func,li)
print(l2) # <map object at 0x0000022EE54A7A20> 迭代器
print(list(l2)) # [1, 27, 125, 512, 729]
# 结果
<map object at 0x0000022EE54A7A20>
[1, 27, 125, 512, 729]
重点掌握:print、min、max、sum、map、sorted、reversed、filter、zip
有key的内置函数:min、max、map、sorted、filter、zip
二十二、匿名函数
lambda 表达式 就是匿名函数,一行函数
普通函数,有且只有返回值的函数才可以使用匿名函数进行简化,一行函数。
匿名函数一般不单独使用,多余内置函数配合使用。
格式:
func = lambda x:x*2
函数名 = lambda 参数 :返回值
func = lambda x : pow(x,3)
print(func(2)) # 8
匿名函数的返回值可以放三元运算
func = lambda x : x > 13 and x or x**2
print(func(10)) # 100
二十三、递归函数
函数的自我调用,就称为递归函数。
递归能解决的函数也能解决,而且递归算法解题的运行效率较低。
使用递归函数一定要用 return
# 求 8!
def func(x):
if x == 1:
return x
return x * func(x-1)
print(func(8))
python默认递归深度有限制的,默认998次,以免消耗尽内存
def func(x):
print(x)
x += 1
return func(x)
func(1)
# 结果
1
2
...
...
...
996
997
998
Traceback (most recent call last):
File "D:/Day14/review.py", line 256, in <module>
func(1)
File "D:/Day14/review.py", line 255, in func
return func(x)
File "D:/Day14/review.py", line 255, in func
return func(x)
File "D:/Day14/review.py", line 255, in func
return func(x)
[Previous line repeated 993 more times]
File "D:/Day14/review.py", line 253, in func
print(x)
RecursionError: maximum recursion depth exceeded while calling a Python object
可以对深度进行修改,导入sys模块
import sys
sys.setrecursionlimit(100000)
def func(x):
print(x)
x += 1
return func(x)
func(1)
# 结果
1
2
3
...
...
...
3219
3220
3221