函数式编程风格中有一个“纯函数”的概念,纯函数是一种无副作用的函数,除此之外纯函数还有一个显著的特点:对于同样的输入参数,总是返回同样的结果。在平时的开发过程中,我们也应该尽量把无副作用的“纯计算”提取出来实现成“纯函数”,尤其是涉及到大量重复计算的过程,使用纯函数+函数缓存的方式能够大幅提高程序的执行效率。本文的主题即是函数缓存实现的及应用,必须强调的是Memoization起作用的对象只能是纯函数
函数缓存的概念很简单,先来一个最简单的实现来说明一下:
function memoize(func) {
const cache = {};
return function(...args) {
const key = JSON.stringify(args)
return cache[key] || (cache[key] = func.apply(this, args))
}
}
memoize就是一个高阶函数,接受一个纯函数作为参数,并返回一个函数,结合闭包来缓存原纯函数执行的结果,可以简单的测试一下:
function sum(n1, n2) {
const sum = n1 + n2
console.log(`${n1}+${n2}=${sum}`)
return sum
}
const memoizedSum = memoize(sum)
memoizedSum(1, 2) // 会打印出:1+2=3
memoizedSum(1, 2) // 没有输出
memoizedSum在第一次执行时将执行结果缓存在了闭包中的缓存对象cache中,因此第二次执行时,由于输入参数相同,直接返回了缓存的结果。
上面memoize的实现能够满足简单场景下纯函数结果的缓存,但要使其适用于更广的范围,还需要重点考虑两个问题:
- 1.缓存器
cache对象的实现问题 - 2.缓存器对象使用的
key值计算问题
下面着重完善这两个问题。
1.cache对象问题
上述实现版本使用普通对象作为缓存器,这是我们惯用的手法。问题不大,但仍要注意,例如最后返回值的语句,存在一个容易忽略的问题:如果cache[key]为“假值”,比如0、null、false,那会导致每次都会重新计算一次。
return cache[key] || (cache[key] = func.apply(this, args))
因此为了严谨,还是要多做一些判断,
function memoize(func) {
const cache = {};
return function(...args) {
const key = JSON.stringify(args)
if(!cache.hasOwnProperty(key)) {
cache[key] = func.apply(this, args)
}
return cache[key]
}
}
更好的选择是使用ES6+支持的Map对象
function memoize(func) {
const cache = new Map()
return function(...args) {
const key = JSON.stringify(args)
if (cache.has(key)) {
return cache.get(key)
}
const result = func.apply(this, args)
cache.set(key, result)
return result
}
}
2.缓存器对象使用的key值计算问题
ES6+的支持使得第一个问题很容易就完善了,毕竟这年头什么代码不是babel加持;而缓存器对象key的确定却是一个让人脑壳疼的问题。key直接决定了函数计算结果缓存的效果,理想情况下,函数参数与key满足一对一关系,上述实现中我们通过const key = JSON.stringify(args)将参数数组序列化计算key,在大多数情况下已经满足了一对一的原则,用在平时的开发中大概也不会有问题。但是需要注意的是序列化将会丢失JSON中没有等效类型的任何Javascript属性,如函数或Infinity,任何值为undefined的属性都将被JSON.stringify忽略,如果值作为数组元素序列化结果又会有所不同,如下图所示。
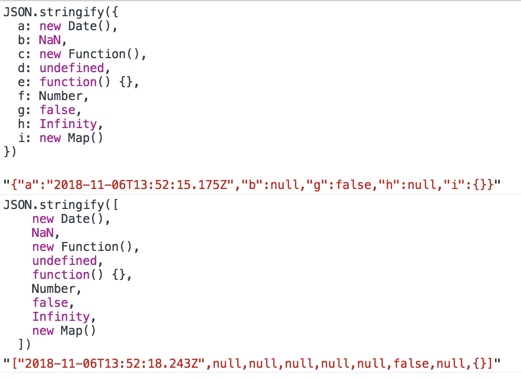 

虽然我们很少将这些特殊类型作为函数参数,但也不能排除这种情况。比如下面的例子,函数calc接收两个普通参数和一个算子,算子则执行具体的计算,如果使用上面的方法缓存函数结果,可以发现第二次输入的是减法函数,但仍然打印出结果3而不是-1,原因是两个参数序列化结果都是[1,2,null],第二次打印的是第一次的缓存结果。
function sum(n1, n2, ) {
const sum = n1 + n2
return sum
}
function sub(n1, n2, ) {
const sub = n1 - n2
return sub
}
function calc(n1, n2, operator){
return operator(n1, n2)
}
const memoizedCalc = memoize(calc)
console.log(memoizedCalc(1, 2, sum)) // 3
console.log(memoizedCalc(1, 2, sub)) // 3
既然JSON.stringify不能产生一对一的key,那么有什么办法可以实现真正的一对一关系呢,参考Lodash的源码,其使用了WeakMap对象作为缓存器对象,其好处是WeakMap对象的key只能是对象,这样如果能够保持参数对象的引用相同,对应的key也就相同。
function memoize(func) {
const cache = new WeakMap()
return function(...args) {
const key = args[0]
if (cache.has(key)) {
return cache.get(key)
}
const result = func.apply(this, args)
cache.set(key, result)
return result
}
}
function sum(n1, n2) {
const sum = n1 + n2
console.log(`${n1}+${n2}:`, sum)
return sum
}
function sub(n1, n2, ) {
const sub = n1 - n2
console.log(`${n1}-${n2}:`, sub)
return sub
}
function calc(param){
const {n1, n2, operator} = param
return operator(n1, n2)
}
const memoizedCalc = memoize(calc)
const param1 = {n1: 1, n2: 2, operator: sum}
const param2 = {n1: 1, n2: 2, operator: sub}
console.log(memoizedCalc(param1))
console.log(memoizedCalc(param2))
console.log(memoizedCalc(param2))
执行打印的结果为
1+2: 3
3
1-2: -1 // 只在第一次做减法运算时打印
-1
-1 // 第二次执行减法直接打印出结果
使用WeakMap作为缓存对象还是有很多局限性,首选参数必须是对象,再比如我们把上例最后几行代码改成下面的代码,会发现后面减法的输出还是错误的,因为前后参数引用的对象都是param1,因此对应的key是相同的,而且在开发过程中我们不太可能一直保存参数的引用,大对数重读计算的场景下,我们都会构造新的参数对象,即使有些参数对象看起来长的一样,但却对应不同的引用,也就对应不同的key,这就失去了缓存的效果。
console.log(memoizedCalc(param1)) // 3
param1.operator = sub
console.log(memoizedCalc(param1)) // 3
console.log(memoizedCalc(param1)) // 3
为了使开发具有最高的灵活性,在Memoization过程中,key的计算最好由开发者自己决定使用何种规则产生与函数结果一一对应的关系,实际上Lodash和Ramda都提供了类似的实现。
function memoize(func, resolver) {
if (typeof func != 'function' || (resolver != null && typeof resolver != 'function')) {
throw new TypeError('Expected a function')
}
const cache = new Map() //可以根据实际情况使用WeakMap或者{}
return function(...args) {
const key = resolver ? resolver.apply(this, args) : args[0]
if (cache.has(key)) {
return cache.get(key)
}
const result = func.apply(this, args)
cache.set(key, result)
return result
}
}
上述代码memoize除了接收需要缓存的函数,还接收一个resolver函数,方便用户自行决定如果计算key。