Spark,缺点是批计算,Spark-Streaming的流本质上还是批(微批)计算。
Flink真正流计算,实时分布式处理框架,支持高吞吐,低延迟,高性能。
一、Flink
Apache Flink是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。
1,有界流和无界流
任何类型的数据都可以形成一种事件流。信用卡交易,传感器测量,机器日志,网站或移动应用程序上的用户交互记录,所有这些数据都形成一种流。
无界流:有定义流的开始,但没有定义流的结束。它们会无休止的产生数据。无界流的数据必须持续处理,即数据被摄取后需要立即处理。流计算。
有界流:有定义流的开始,也有定义流的结束。有界流所有数据可以被排序,所以并不需要有序摄取。批计算。
2,有状态
Spark Stream有些算子是有状态的,默认是没有状态的。
Flink默认就是有状态的。
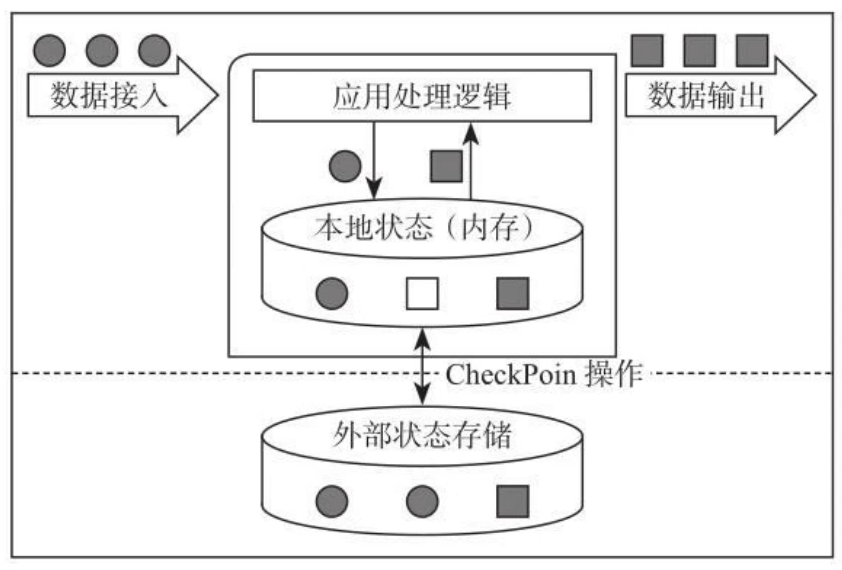
状态保存在本机,可以用CheckPoint机制,每隔一段时间把内存中的状态CheckPoint。
3,为什么用Flink?

Flink可以做实时智能推荐,复杂事件处理(CEP),实时欺诈检测,实时数仓与ETL类型,流数据分析类型,实时报表分析(双十一)等实时业务场景。
4, Flink的特点和优势
1)同时支持高吞吐,低延迟,高性能
低延迟,状态保存在内存中,很快计算完。
2)支持事件时间(Event Time) 概念
Process TIme,大多数框架窗口计算采用的都是系统时间(process time),也是事件传输到计算框架处理时,系统主机的当前时间。
Event Time,Flink支持基于事件时间(Event Time)语义进行窗口计算,也就是使用事件产生的时间,这种基于事件驱动的机制使得事件即使乱序到达,流系统也能够计算出精确的结果,保持了事件原本产生时的时序性,尽可能避免网络传输或硬件系统的影响。
3)支持有状态计算
4)支持高度灵活的窗口(Window)操作。
Flink中除了滚动窗口,滑动窗口还有基于数量的窗口Count,基于会话的窗口Session。
5)基于轻量级的分布式快照(CheckPoint)来实现容错
6)基于JVM实现独立的内存管理
7)Save Point保存点
CheckPoint是自动的,做容错。Save Point是手动的,处理程序升级。
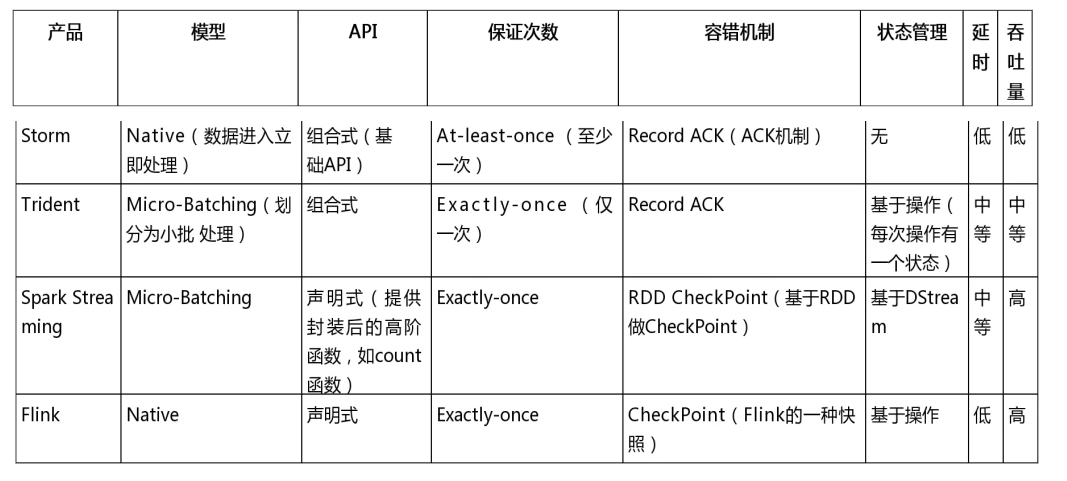
5,Flink与其他框架对比

二、Flink 入门
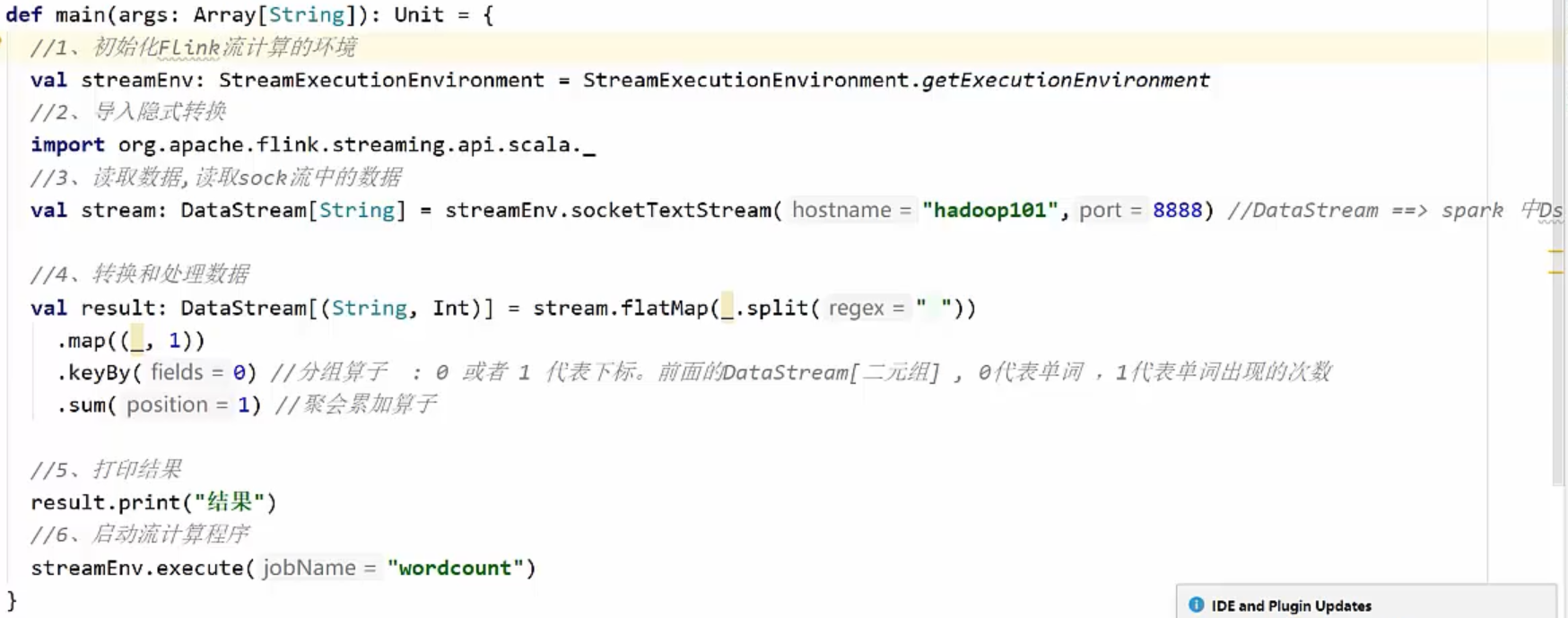
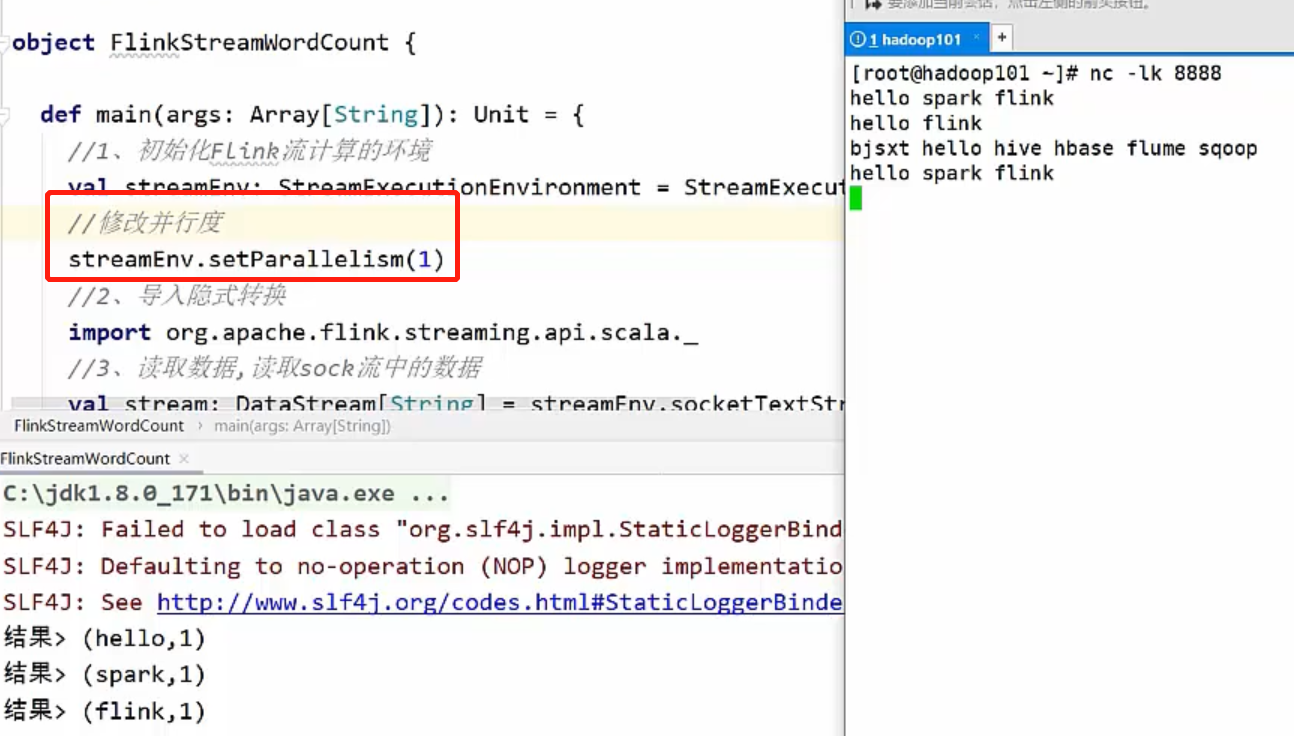
1,Flink流计算的WorkCount

2,Flink批计算的WorkCount

三、Flink的架构
1,集群基本架构
1,概述
集群模式:
- Standalone
- Flink on Yarn
- Mesos
- Docker
- Kubernetes
- AWS
- Google Compute Engine
Flink整个系统主要由两个组件组成,分别为JobManager和TaskManager。Flink架构也遵循Master-Slave架构设计原则,JobManager为Master节点,TaskManager为Worker(Slave)节点。所有组件(节点)之间的通信都是借助于Akka Framework,包括任务的状态以及Checkpoint触发等信息。
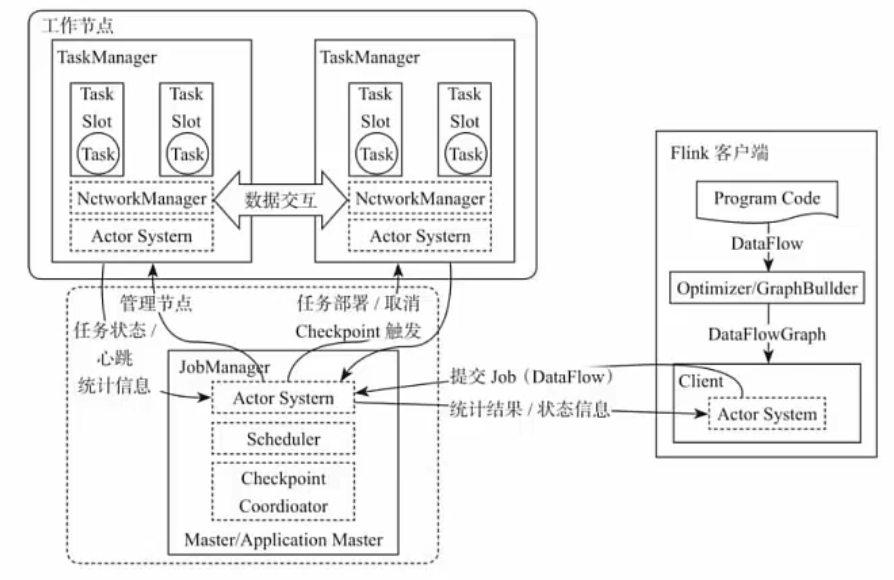
Flink客户端提交给JobManager。
Job Manager把一个程序的多个Task分发到Task Manager上。
每一个TaskManager上有多个Task Slot,Slot上就可以运行Task。
一个TaskManager上有几个Task Slot,是由集群配置的时候自己配置的。
一个Job Manager和多个Task Manager直接通过Actor System通信。
2,Client客户端
客户端负责将任务提交到集群,与JobManager构建Akka连接,然后将任务提交到JobManager,通过和JobManager之间进行交互获取任务执行状态。
客户端将任务提交到集群有3种方式,CLI方式,Flink WebUI方式,通过程序指定JobManager的RPC网络端口构建ExecutionEnvironment提交Flink应用。
WebUI:上传一个jar包,指定一个你要运行的类,点击Submit提交。

Flink客户端程序,通过Program Code生成DataFlow,DataFlow通过优化器Optimizer/GraphBullder生成一个DataFlowGraph数据流图,数据流程图通过Actor System通信系统提交到Job Manager。客户端提交完后接收Job Manager的反馈,执行的状态,执行进度。
![]()
3,Job Manager
整个集群中有且仅有一个活跃的JobManager,JobManager负责整个Flink集群的任务调度以及资源管理。
1,资源管理。根据集群中所有TaskManager上的TaskSlot的使用情况,做资源管理,为应用分配相应的TaskSlots资源,并命令TaskManager启动从客户端获取的应用。
2,任务调度。JobManager和TaskManager之间通过ActorSystem进行通信,获取任务执行的情况并通过Actor System将应用的任务执行情况发送给客户端。
3,触发Checkpoints。所有的Checkpoint协调过程都是在Flink的Job Manager中完成。每个TaskManager节点收到Checkpoint指令后,完成Checkpoint操作。
4,Task Manager
TaskManager负责具体的任务执行和对应任务在每个Slot上的资源申请和管理。
TaskManager从JobManager接收到需要部署的任务,然后使用Slot资源启动Task,建立数据接入的网络连接,接收数据并开始处理数据。同时TaskManager之间的数据交互都是通过ActorSystem数据流的方式进行的。TaskManager进程通过Slot来管理资源和隔离资源。
Flink的任务运行采用多线程的方式,可以极大的提高CPU的使用效率。多个任务多个线程之间通过TaskSlot共享进程资源。
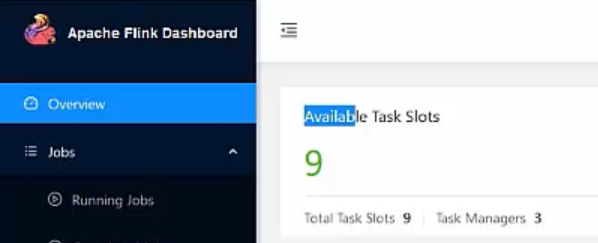
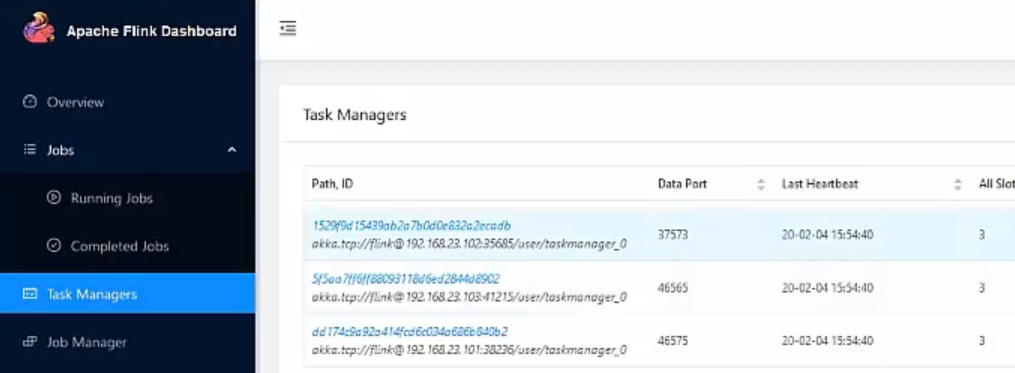
2,JobManager的WebUI
所有可用的Task Slots。Slot可以认为就是资源。
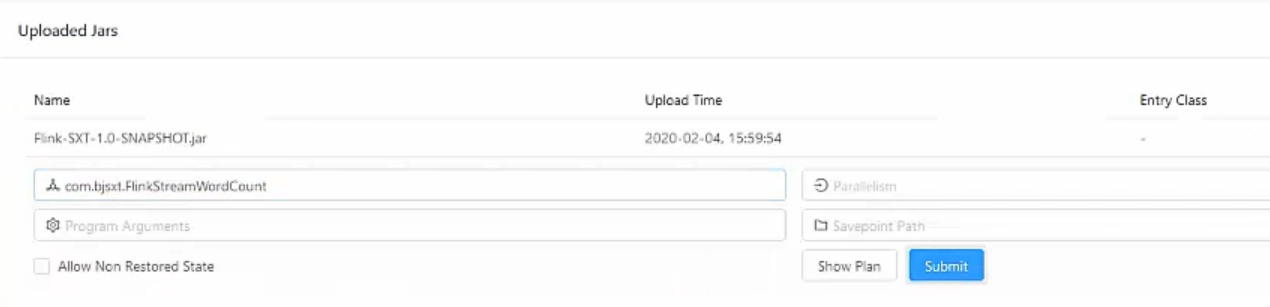
Maven=>compile=>package 打好jar包。上传。

并行度多少,运行哪个主类。填好后提交。
启动后,可以看到流程图
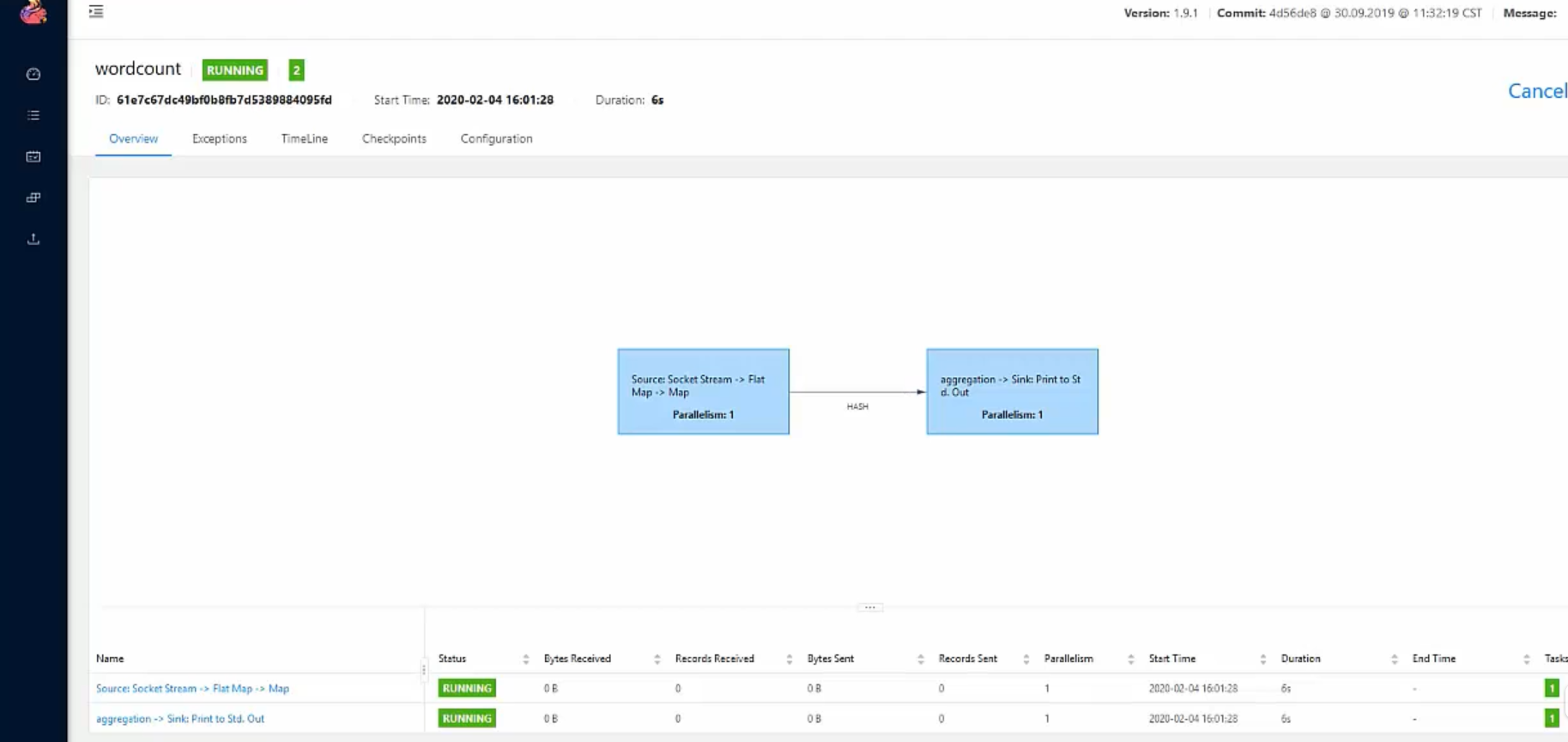
任务链。
配置:

四、Flink API
1,API分层
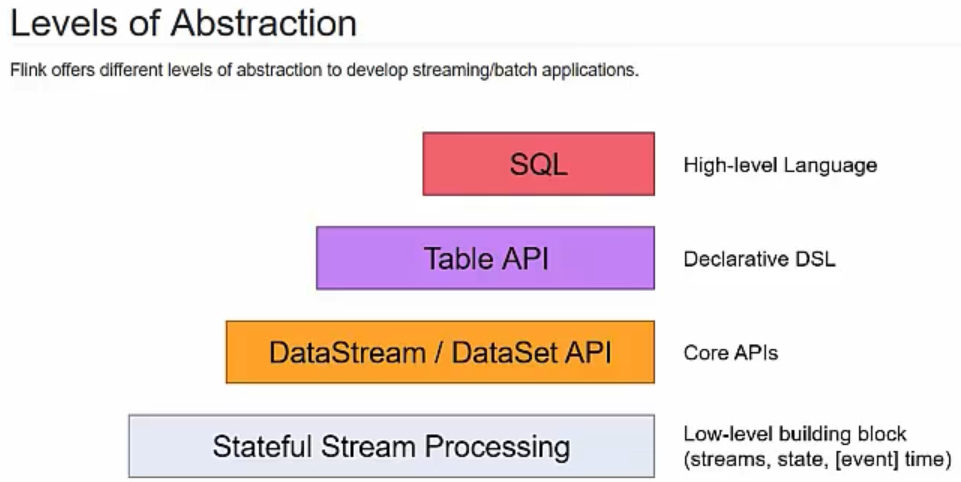
ProcessFunction是Flink最底层的接口。ProcessFunction可以处理一或者两条输入数据流中的单个事件或者归入一个特定窗口内的多个事件。它提供了对时间和状态的细粒度控制。
DataStream API比ProcessFunction多了一些算子。DataStream API为许多通用的流处理操作提供了原语。
SQL&Table API:创建表,定义表的结构,删除表,注册表。Flink支持两种关系型的API,Table API和SQL。这两个API是批处理和流处理统一的API。
扩展库:复杂事件处理CEP,Gelly做图计算的,是一个可扩展的图形处理和分析库。
2,DataStream的编程模型
DataStream的编程模型包括4个部分:Environment,DataSource,Transformation,Sink。

source是输入,输入数据源可以有多个。transformation对输入进行处理,sync把处理后的结果进行落地。
3,DataSource数据源
数据源有多种,基于文件的Source,基于集合的Source,基于Kafka的Source,自定义Source。
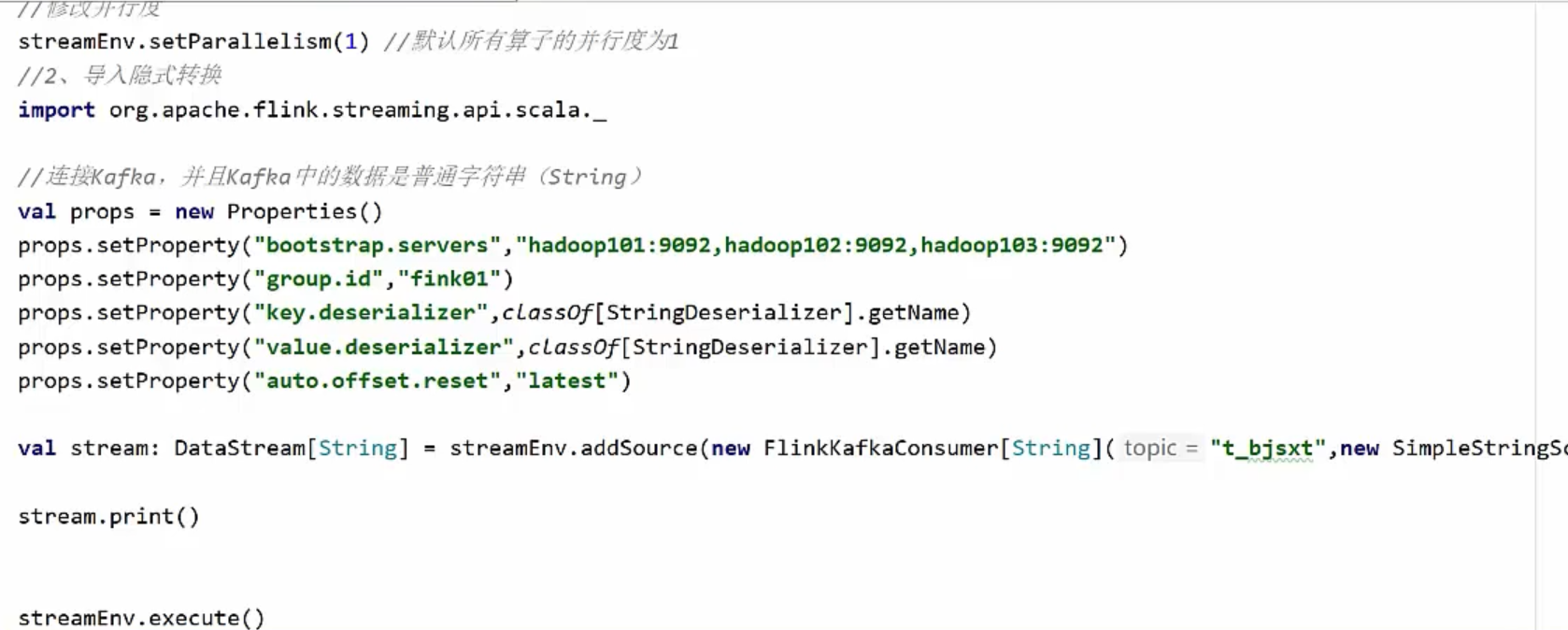
基于Kafka的Source。
1)依赖
2)Kafak数据
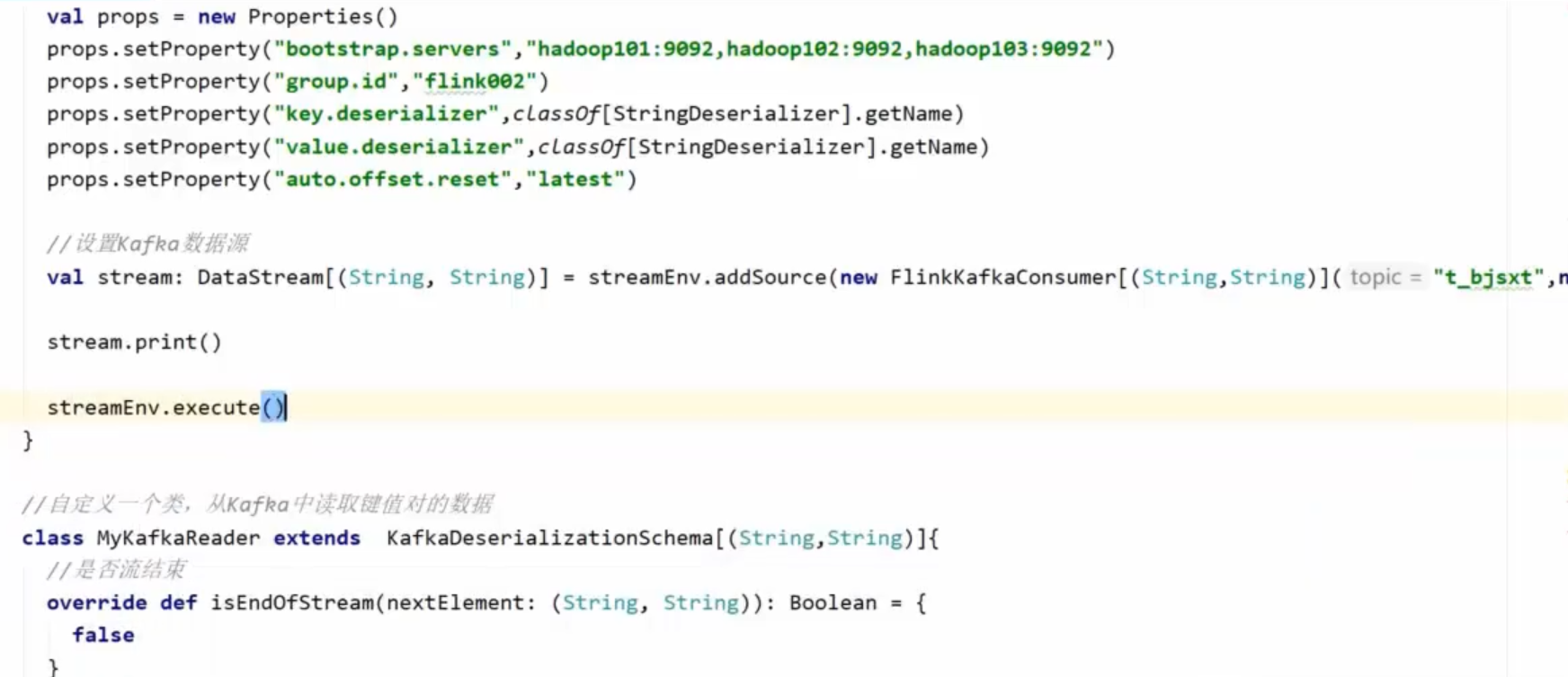
Kafka中数据是String
Kafak总数据是KeyValue
设置FlinkKafkaConsumer[(String,String)]()
自定义一个MyKafkaReader类。
4,Sink
分为基于HDFS的Sink,基于Redis的Sink,基于Kafka的Sink,自定义的Sink。
基于kafka的Sink,把结果写入Kafka。
1)配置Kafka连接器的以来配置
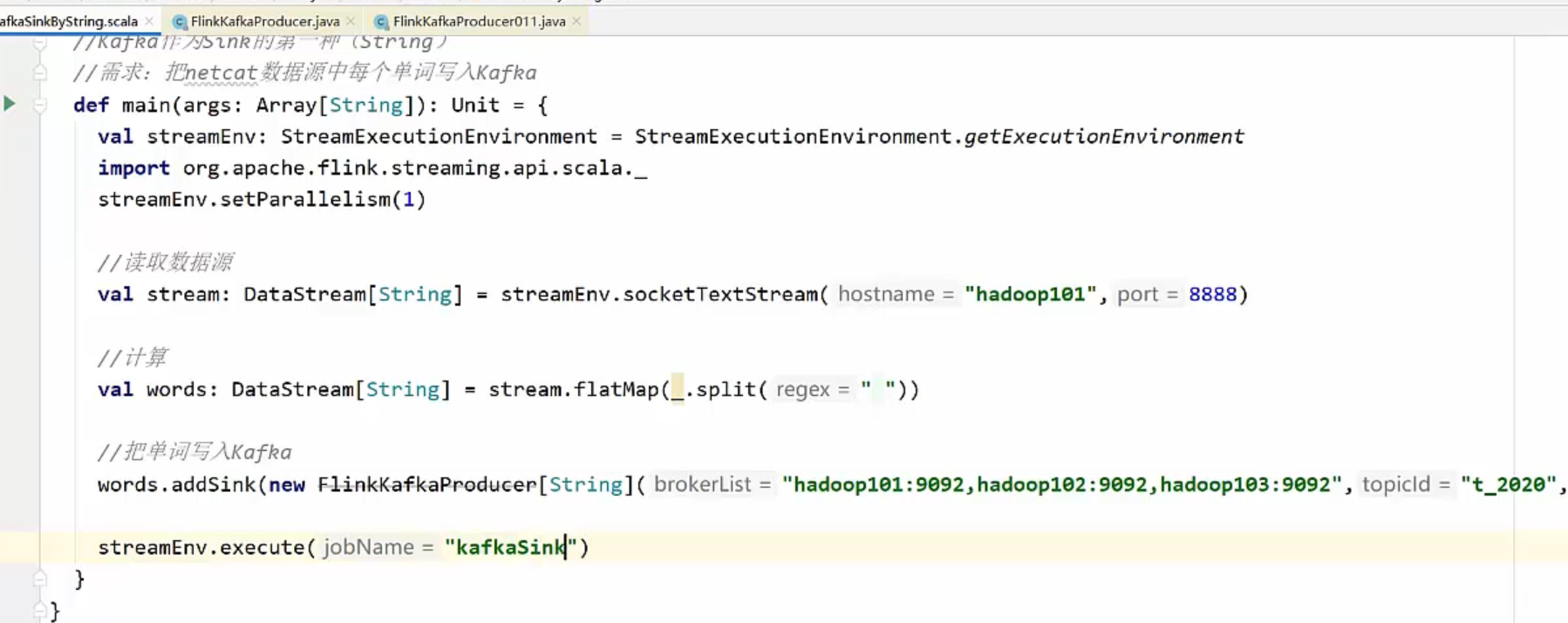
1)把普通字符串写到Kafka中去
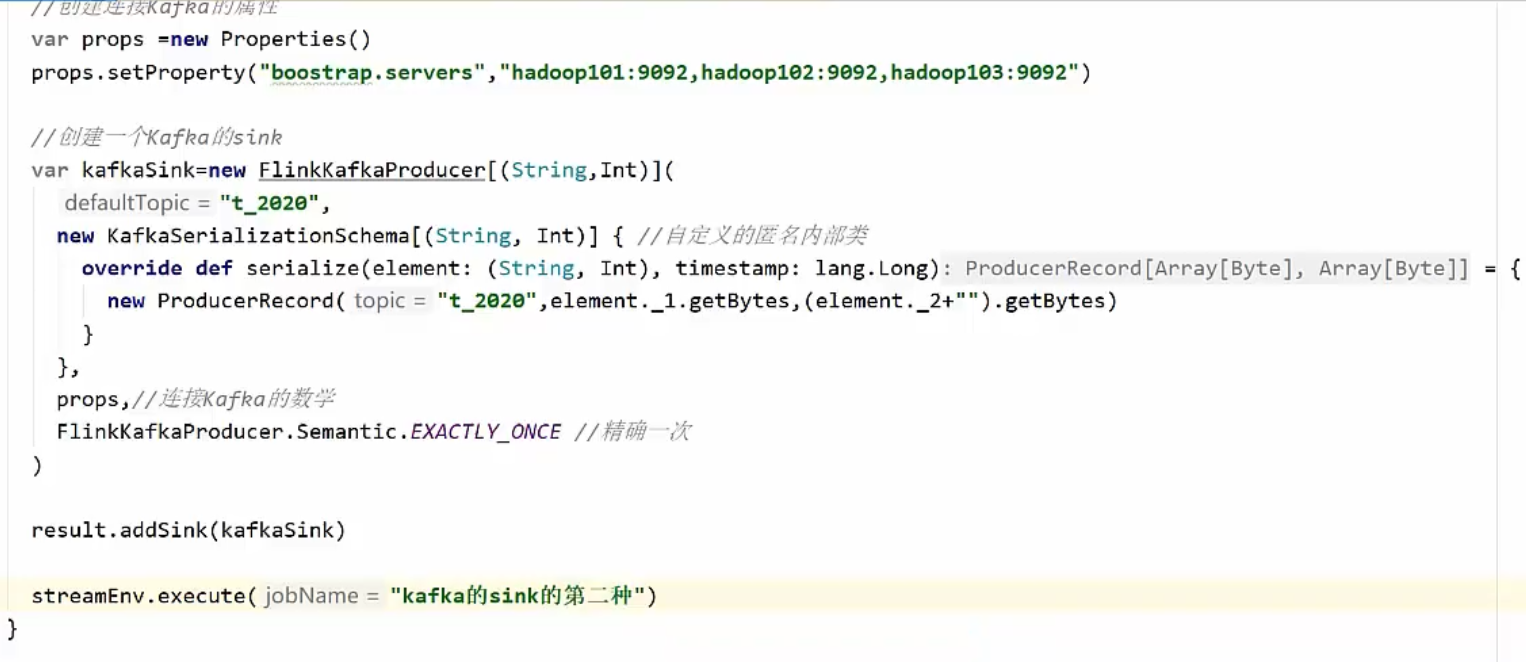
2)把Key,Value写入kafka
案例:把netcat作为数据源,统计每个单词的数量,并且把统计的结果写入Kafka

5,DataSet API & DataStream API
transformation阶段用到一些算子,处理有限数据流的DataSet API和处理无限数据流的DataStream API。
DataSetAPI是Flink用于批处理的核心API。提供基础算子:map,reduce,(outer)join,co-group,iterate等

map的输出只有一个,flatMap的输出可能有多个。

DataStream还有一些自己独有的API,比如聚合函数aggregations。
流上面最经典最常用的window函数。

Flink的Window支持了很多种不同的类型,比如说滑动窗口,滚动窗口和session window等等。