场景描述
假如我们现在有3台缓存服务器,当有一张图片要缓存时,我们希望缓存均匀的分布在3台服务器上,可以使用如下公式来判断要缓存到哪台服务器,
hash(图片名称) % 3

当我们想增加或减少服务器时,如增加到4台,得到的余数就和之前存放缓存的结果不同了,结果就是所有缓存在一段时间内就算失效了,可能造成系统崩溃。
一致性哈希算法
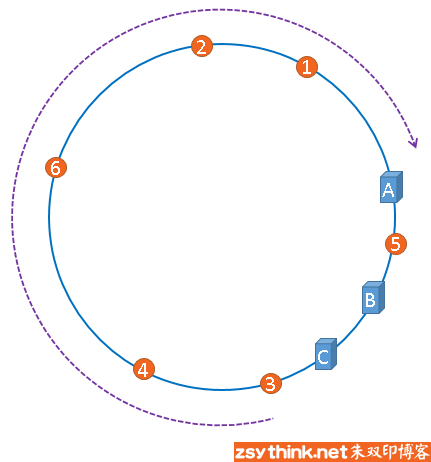
定义一个由2^32个数组成的环
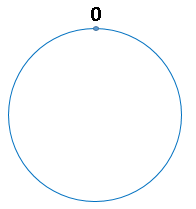
使用如下公式将服务器A,B,C映射到环上
hash(服务器A的IP地址) % 2^32
hash(服务器B的IP地址) % 2^32
hash(服务器C的IP地址) % 2^32
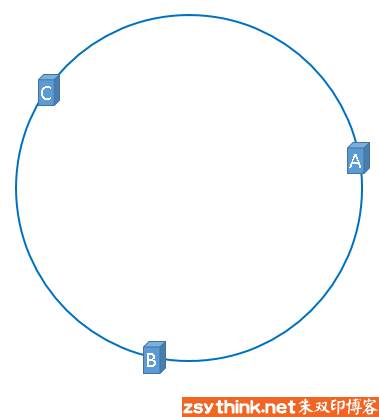
将要缓存的图片也映射到环上
hash(图片名称) % 2^32
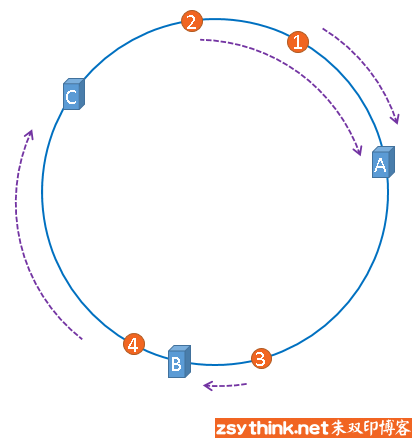
从被缓存对象顺时针寻找,遇到的第一个服务器就是当前对象被缓存的服务器。
当我们想增加或减少服务器数量时,如去除服务器B
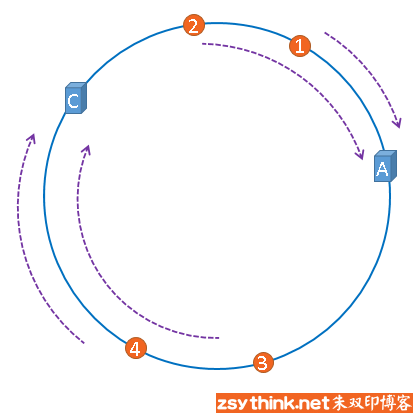
1,2仍然存储在服务器A,4也仍然存储在服务器C,只有3的存储位置有变化,之前在服务器B,现在要存储到服务器C。
一致性哈希的优点就是当增加或减少服务器时,只有要增加或减少的服务器上的数据有变化,其余服务器不变,对于缓存来说就是并不会造成所有的缓存都失效。
环数据偏斜
服务器列表有可能并不会均匀的映射到环上
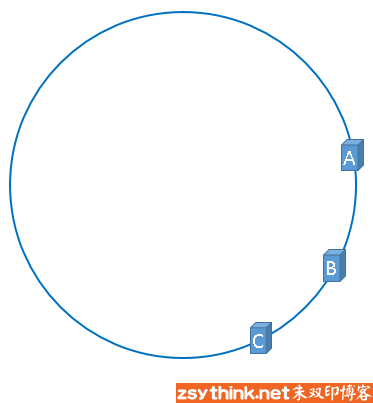
这种情况可能大部分数据都会集中到服务器A
如果服务器A出现故障,极端情况下,仍然可能造成系统崩溃,可以使用虚拟节点解决这个问题。
虚拟节点
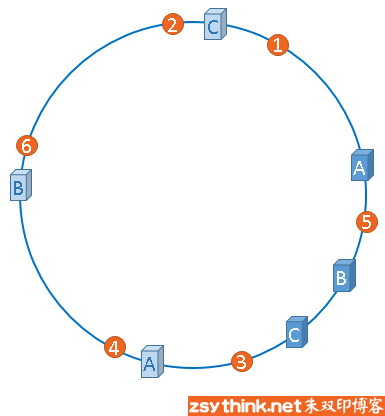
对每个实际节点复制出一个虚拟节点,一个实际节点可以有多个虚拟节点,虚拟节点越多,数据分布越均匀。
代码实现
import java.util.Collection;
import java.util.SortedMap;
import java.util.TreeMap;
import java.util.function.Function;
public class ConsistentHash<T> {
/**
* Hash计算对象,用于自定义hash算法
*/
private Function<String, Integer> hashFunc;
/**
* 复制的节点个数
*/
private final int numberOfReplicas;
/**
* 一致性Hash环
*/
private final SortedMap<Integer, T> circle = new TreeMap<>();
/**
* 构造,使用Java默认的Hash算法
*
* @param numberOfReplicas 复制的节点个数,增加每个节点的复制节点有利于负载均衡
* @param nodes 节点对象
*/
public ConsistentHash(int numberOfReplicas, Collection<T> nodes) {
this.numberOfReplicas = numberOfReplicas;
this.hashFunc = this::fnvHash;
//初始化节点
for (T node : nodes) {
add(node);
}
}
/**
* 改进的32位FNV算法1
* https://en.wikipedia.org/wiki/Fowler–Noll–Vo_hash_function
* @param data 字符串
* @return hash结果
*/
private int fnvHash(String data) {
final int p = 16777619;
int hash = (int) 2166136261L;
for (int i = 0; i < data.length(); i++) {
hash = (hash ^ data.charAt(i)) * p;
}
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
return Math.abs(hash);
}
/**
* 构造
*
* @param hashFunc hash算法对象
* @param numberOfReplicas 复制的节点个数,增加每个节点的复制节点有利于负载均衡
* @param nodes 节点对象
*/
public ConsistentHash(Function<String, Integer> hashFunc, int numberOfReplicas,
Collection<T> nodes) {
this.numberOfReplicas = numberOfReplicas;
this.hashFunc = hashFunc;
//初始化节点
for (T node : nodes) {
add(node);
}
}
/**
* 增加节点<br> 每增加一个节点,就会在闭环上增加给定复制节点数<br> 例如复制节点数是2,则每调用此方法一次,增加两个虚拟节点,这两个节点指向同一Node
* 由于hash算法会调用node的toString方法,故按照toString去重
*
* @param node 节点对象
*/
public void add(T node) {
for (int i = 0; i < numberOfReplicas; i++) {
circle.put(hashFunc.apply(node.toString() + i), node);
}
}
/**
* 移除节点的同时移除相应的虚拟节点
*
* @param node 节点对象
*/
public void remove(T node) {
for (int i = 0; i < numberOfReplicas; i++) {
circle.remove(hashFunc.apply(node.toString() + i));
}
}
/**
* 获得一个最近的顺时针节点
*
* @param key 为给定键取Hash,取得顺时针方向上最近的一个虚拟节点对应的实际节点
* @return 节点对象
*/
public T get(Object key) {
if (circle.isEmpty()) {
return null;
}
int hash = hashFunc.apply(key.toString());
if (!circle.containsKey(hash)) {
SortedMap<Integer, T> tailMap = circle.tailMap(hash); //返回此映射的部分视图,其键大于等于 hash
hash = tailMap.isEmpty() ? circle.firstKey() : tailMap.firstKey();
}
//正好命中
return circle.get(hash);
}
}
调用
import java.util.List;
import java.util.Map;
import java.util.TreeMap;
public class Client {
public static void main(String[] args) {
//物理节点
List<String> ipNodes = List
.of("192.168.1.101", "192.168.1.102", "192.168.1.103", "192.168.1.104");
ConsistentHash<String> consistentHash = new ConsistentHash<>(100, ipNodes);
// 统计
statistics(consistentHash, 0, 65536);
consistentHash = new ConsistentHash<>(10000, ipNodes);
statistics(consistentHash, 0, 65536);
}
private static void statistics(ConsistentHash<String> consistentHash, int objectMin,
int objectMax) {
Map<String, Integer> objectNodeMap = new TreeMap<>(); // IP => COUNT
for (int object = objectMin; object <= objectMax; object++) {
String nodeIp = consistentHash.get(Integer.toString(object));
Integer count = objectNodeMap.getOrDefault(nodeIp, 0);
objectNodeMap.put(nodeIp, count + 1);
}
// 打印
double totalCount = objectMax - objectMin + 1;
String label = "统计";
System.out.println("======== " + label + " ========");
for (Map.Entry<String, Integer> entry : objectNodeMap.entrySet()) {
long percent = (int) (100 * entry.getValue() / totalCount);
System.out.println("IP=" + entry.getKey() + ": RATE=" + percent + "%");
}
}
}
输出结果为
======== 统计 ========
IP=192.168.1.101: RATE=23%
IP=192.168.1.102: RATE=26%
IP=192.168.1.103: RATE=20%
IP=192.168.1.104: RATE=28%
======== 统计 ========
IP=192.168.1.101: RATE=25%
IP=192.168.1.102: RATE=24%
IP=192.168.1.103: RATE=24%
IP=192.168.1.104: RATE=25%
可以看到虚拟节点越多,数据分布越均匀。