- YOLOv1算法简介
是继RCNN,Fast-RCNN和Faster-RCNN之后,对DL目标检测速度问题提出的另外一种框架。使用深度神经网络进行对象的位置检测以及分类,
主要特点是速度快,准确率高,采用直接预测目标对象的边界框的方法,将候选区和对象识别两个阶段合二为一。
yolov1将原始图片分割成互不重合的小方块,(也就是将图像分成S x S个网格),然后通过卷积最后生产这样大小的特征图,基于上面的分析,
可以认为特征图的每个元素也是对应原始图片的小方块,然后利用每个元素来可以预测那些中心点在改小方格的目标
yolo是将物体检测任务当做回归问题来做
论文下载:http://arxiv.org/abs/1506.02640 代码下载:https://github.com/pjreddie/darknet
- YOlOv1的算法原理
如图所示,分成7*7个小格子,每个格子预测两个bounding box,
每个bonding box除了要回归自身的位置( (x, y, w, h) 和 confidence 共5个值)之外,还要附带预测一个confidence值(置信度)
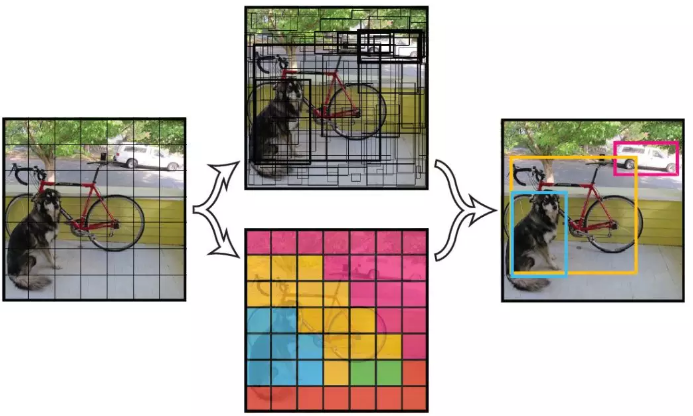
如果一个目标的中心落入一个网格单元中,该网格单元负责检测 该目标。
对每一个切割的小单元格预测(置信度,边界框的位置),每个bounding box需要4个数值来表示其位置,
(Center_x,Center_y,width,height),即(bounding box的中心点的x坐标,y坐标,bounding box的宽度,高度),
也就是要预测 (x, y, w, h) 和 confidence 共5个值,每个网格还要预测一个类别信息,记为 C 类。则 SxS个 网格,
每个网格要预测 B 个 bounding box 还要预测 C 个 categories。
输出就是 S x S x (5*B+C) 的一个 tensor。
置信度定义为是否存在目标与iou值的乘积 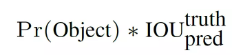
注意:class 信息是针对每个网格的,confidence 信息是针对每个 bounding box 的。
举例说明: 在 PASCAL VOC 中,图像输入为 448x448,取 S=7,B=2,一共有20 个类别(C=20),则输出就是 7x7x30 的一个 tensor。
算法流程
1、将图像resize到448 * 448作为神经网络的输入
2、运行神经网络,得到一些bounding box坐标、box中包含物体的置信度和class probabilities
3、进行非极大值抑制,筛选Boxes
算法结构
网络方面主要采用GoogLeNet,(YOLO未使用inception module,而是采用1*1卷积层,为了跨通道信息整合+3*3卷积层简单代替)
包含24个卷积层和2个全连接层,卷积层主要用来提取图像特征,全连接层主要用来预测图像位置和类别概率,
最后输出是7*7*30(30是5*2+20),7*7就是切分的网格(grid cell)的数量,可能对于inception的改动,最后几层全连接的改动,
重点在于最后一层的输出是7*7*30
输入图像分辨率为448*448,所有预测结果归一化0~1,使用Leaky Relu作为激活函数,第一个全连接层后面接了一个ratio=0.5的Dropout层
参考链接 :http://www.imooc.com/article/36391

直接把训练好的YOLO网络模型输入一张图片,得到一个7*7*30的结果向量,通过NMS(非极大值抑制)来选择最终的结果;
NMS就是通过打分来选出最好的结果,与这个结果重叠的对象去掉,是一个不断迭代的过程。
score = 某个对象的概率 * 置信度
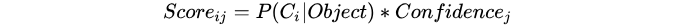
所以对于每个网格有20*2个得分,每个对象有49*2个得分;这里的2是bounding box的个数;
具体的过程是:
1,设置一个分数阈值,低于的直接置为0;
2,遍历对于每个对象:
选出分数最高的那个及其bounding box放到输出列表中;
将其他的与上面选出的分数最高的那个计算IOU,设置一个阈值,大于阈值的表示重叠度较高,把分数置为0;
如果所有的bounding box都在输出列表中或者分数为0,那么这个对象的NMS就结束
对接下来的对象执行此过程
3.得出输出结果;
算法优点
1、YOLO检测物体非常快
2、YOLO可以很好的区分背景与物体,不像其他物体检测使用滑窗或者region proposal,分类器只能得到局部图像的局部信息,
YOLO在训练和测试时都能看到一整张图像的信息,因此YOLO在检测物体时能很好的利用上下文信息,从而不容易背景上预测储错误的物体信息。
和Fast-RCNN相比,YOLO的背景错误不到Fast-RCNN的一半
3、YOLO具有高度泛化能力,因此应用新领域或碰到意外的的输入时不太可能出现故障
算法缺点
1、位置精确性差,容易产生物体的定位错误,输入尺寸固定
2、对相互靠的很近的物体,对于小目标物体,很小的群体检测效果不好
3、YOLO虽然可以降低将背景检测为物体的概率,但同时导致召回率较低
参考博客:
https://blog.csdn.net/duanyajun987/article/details/81940284
http://www.imooc.com/article/36391
https://www.cnblogs.com/ywheunji/p/10761239.html