一、Shell 的含义
1、Shell 的含义
程序是为实现特定目标或解决特定问题而用计算机语言编写的命令序列的集合。简单来说,电脑里面的应用都是程 序来控制的,程序天天见。程序是由序列组成的,告诉计算机如何完成一个具体的任务。由于现在的计算机还不能 理解人类的自然语言,所以还不能用自然语言编写计算机程序,不过现在语音识别技术己经很历害了,在不久的将 来,估计,电脑就自己会编程序了
2、Shell 在Linux中的存在形式
由于Linux不同于Windows,Linux是内核与界面分离的,它可以脱离图形界面而单独运行,同样也可以在内核的 基础上运行图形化的桌面。 这样,在Linux系统中,就出现了两种Shell表现形式,一种是在无图形界面下的终端运 行环境下的Shell,另一种是桌面上运行的类似Windows 的MS-DOS运行窗口,前者我们一般习惯性地简称为终 端,后者一般直接称为Shell
3、Shell 如何执行用户的指令
1、Shell有两种执行指令的方式:
第一种方法是用户事先编写一个sh脚本文件,内含Shell脚本,而后使用Shell程序执行该脚本,这种方式,我 们习惯称为Shell编程。
第二种形式,则是用户直接在Shell界面上执行Shell命令,由于Shell界面的关系,大家都习惯一行行的书写, 很少写出成套的程序来一起执行,所以也称命令行。
总结 Shell 只是为用户与机器之间搭建成的一个桥梁,让我们能够通过Shell来对计算机进行操作和交互,从而达到 让计算机为我们服务的目的。
二、Shell 的分类
Linux中默认的Shell是/bin/bash,流行的Shell有ash、bash、ksh、csh、zsh等,不同的Shell都有自己的特点以 及用途。
1、bash
大多数Linux系统默认使用的Shell,bash Shell是Bourne Shell 的一个免费版本,它是最早的Unix Shell,bash 还有一个特点,可以通过help命令 来查看帮助。包含的功能几乎可以涵盖Shell所具有的功能,所以一般的Shell脚本都会指定它为执行路径。 千锋云计算学院
2、csh
C Shell 使用的是“类C”语法,csh是具有C语言风格的一种Shell,其内部命令有52个,较为庞大。目前使用的 并不多,已经被/bin/tcsh所取代。
3、ksh
Korn Shell 的语法与Bourne Shell相同,同时具备了C Shell的易用特点。许多安装脚本都使用ksh,ksh 有42条 内部命令,与bash相比有一定的限制性。
4、tcsh
tcsh是csh的增强版,与C Shell完全兼容。
5、sh
是一个快捷方式,已经被/bin/bash所取代。
6、nologin
指用户不能登录
7、zsh
目前Linux里最庞大的一种 zsh。它有84个内部命令,使用起来也比较复杂。一般情况下,不会使用该Shell。
三、Shell 能做什么呢
自动化批量系统初始化程序 (update,软件安装,时区设置,安全策略...)
自动化批量软件部署程序 (LAMP,LNMP,Tomcat,LVS,Nginx)
应用管理程序 (KVM,集群管理扩容,MySQL,DELLR720批量RAID)
日志分析处理程序(PV, UV, 200, !200, top 100, grep/awk)
自动化备份恢复程序(MySQL完全备份/增量 + Crond)
自动化管理程序(批量远程修改密码,软件升级,配置更新)
自动化信息采集及监控程序(收集系统/应用状态信息,CPU,Mem,Disk,Net,TCP Status,Apache,MySQL)
配合Zabbix信息采集(收集系统/应用状态信息,CPU,Mem,Disk,Net,TCP Status,Apache,MySQL)
自动化扩容(增加云主机——>业务上线)
zabbix监控CPU 80%+|-50% Python API AWS/EC2(增加/删除云主机) + Shell Script(业务上线)
俄罗斯方块,打印三角形,打印圣诞树,打印五角星,运行小火车,坦克大战,排序算法实现 Shell可以做任何事(一切取决于业务需求)
四、bash 的初始化
1、bash环境变量文件的加载
1、/etc/profile
全局(公有)配置,不管是哪个用户,登录时会读取该文件。
2、/etc/bashrc
ubuntu没有此文件,与之对应的是/etc/bash.bashrc
3、~/.profile
若bash以login方式执行时,读取~/.bash_profile,若它不存在,则读取~/.bash_login,若前两者都不存在,读取~/.profile
4、~/.bash_login
若bash是以login方式执行时,读取~/.bash_profile,若它不存在,则读取~/.bash_login,若前两者都不存在,读取~/.profile
5、bash_profile
Ubuntu默认没有此文件,可新建
只有bash 是已login行驶执行时,则才会读取此文件,通常该配置文件还会读取~/.bashrc
6、~/.bashrc
当bash时以non-login形式执行时,读取此文件,若是以login形式执行时,则不会读取。
7、~/.bash_logout
注销时,且是login形式,此文件才会被读取,再文本模式注销时,此文件会被读取,图形模式,此文件不会被读取。
2、bash环境变量的加载
- 图形模式登录时,顺序读取:/etc/profile和~/.profile
- 图形模式登录后,打开终端时,顺序读取:/etc/bash.bashrc和~/.bashrc
- 文本模式登录时,顺序读取:/etc/bash.bashrc,/etc/profile 和 ~/.bash_profile
- 从其他用户su到改用户,则分两种情况:
- 如果带 -l 参数(或-参数,--login 参数),如:su -l username,则 bash 是 login 的,它将顺序读取以 下配置文件:/etc/bash.bashrc,/etc/profile 和~/.bash_profile。
- 如果没有带 -l 参数,则 bash 是 non-login 的,它将顺序读取:/etc/bash.bashrc 和 ~/.bashrc
- 注销时,或退出 su 登录的用户,如果是 longin 方式,那么 bash 会读取:~/.bash_logout
- 执行自定义的 Shell 文件时,若使用 bash -l a.sh 的方式,则 bash 会读取行:/etc/profile 和 ~/.bash_profile,若使用其它方式,如:bash a.sh,./a.sh,sh a.sh(这个不属于bash Shell),则不 会读取上面的任何文件
- 上面的例子凡是读取到 ~/.bash_profile 的,若该文件不存在,则读取 ~/.bash_login,若前两者不存 在,读取 ~/.profile。
- 执行自定义的 Shell 文件时,若使用 bash -l a.sh 的方式,则 bash 会读取行:/etc/profile 和 ~/.bash_profile,若使用其它方式,如:bash a.sh,./a.sh,sh a.sh(这个不属于bash Shell),则不 会读取上面的任何文件
五、bash的特性
1、命令和文件自动补齐
很多命令都会提供一个 bash-complete 的脚本,在执行该命令时,敲 tab 可以自动补全参数,会极大提高生 产效率。
linux命令自动补全需要安装 bash-completion
yum install bash‐completion
2、命令历史记忆功能
Bash 有自动记录命令的功能,自动记录到.bash_history隐藏文件中。还可以在下次需要是直接调用历史记录中的命令
centos 可以通过/etc/profile中的文件来定义一些参数、 在bash中,使用history 命令来查看和操作之前的命令,以此来提高工作效率。
history是bash的内部命令,所以可以使用 help history命令调出history命令的帮助文档。
调用命令的方法:


# 查看之前使用的所有命令 [root@hostname ~]# history # 显示最近的n个命令 [root@hostname ~]# history n # 删除相应的第n个命令 [root@hostname ~]# history ‐d n # 指定执行命令历史中的第n条语句 [root@hostname ~]# !n # 指定执行命令历史中倒数第n条语句 [root@hostname ~]# !‐n # 执行命令历史中最后一条语句 [root@hostname ~]# !! # 执行命令历史中最近一条以[String]开头的语句 [root@hostname ~]# ![String] # 引用上一个命令中的最后一个参数 [root@hostname ~]# !$ # COMMAND + Esc键 + . 输入COMMAND之后,按下Esc键,松开后再按 . 则可以自动输入最近一条语句使用的参数 # COMMAND + Alt + . 输入COMMAND之后,同时按下Alt和. 键,也可以自动输入最近一条语句使用的参数 # 将命令历史写入命令历史的文件中 [root@hostname ~]# history ‐w # 回显 echo 之后的语句,而使用 echo $FILENAME 命令可以查看该 file 所在的路径 [root@hostname ~]# echo $HISTFILE # 查看命令历史的内容 [root@hostname~]# cat .bash_history # 删除所有的命令历史记录 [root@hostname ~]# history ‐c
3、别名功能
alias命令,别名的好处是可以把本来很长的指令简化缩写,来提高工作效率。
[root@hostname ~]# alias #查看系统当前所有的别名 [root@hostname ~]# alias h5=‘head ‐5’ #定义新的别名。这时候输入h5就等于输入’head‐5‘ [root@hostname ~]# unalias h5 #取消别名定义
4、快捷键
| 快捷键 | 作用 |
| ctrl+A | 把光标移动到命令行开头。如果我们输入的命令过长,想要把光标移动到命令行开头时使用。 |
| ctrl+E | 把光标移动到命令行结尾。 |
| Ctrl+C | 强制终止当前的命令。 |
| ctrl+L | 清屏,相当于clear命令。 |
| ctrl+U | 删除或剪切光标之前的命令。我输入了一行很长的命令,不用使用退格键一个一个字符的删除,使 用这个快捷键会更加方便 |
| ctrl+K | 删除或剪切光标之后的内容。 |
| ctrl+Y | 粘贴ctrl+U或ctul+K剪切的内容。 |
| ctrl+R | 在历史命令中搜索,按下ctrl+R之后,就会出现搜索界面,只要输入搜索内容,就会从历史命令中 搜索。 |
| ctrl+D | 退出当前终端。 |
| ctrl+Z | 暂停,并放入后台。这个快捷键牵扯工作管理的内容,我们在系统管理章节详细介绍。 |
| ctrl+S | 暂停屏幕输出。 |
| ctrl+Q | 恢复屏幕输出。 |
5、前后台作业控制
Linux bash Shell单一终端界面下,经常需要管理或同时完成多个作业,如一边执行编译,一边实现数据备份,以 及执行SQL查询等其他的任务。所有的上述的这些工作可以在一个 bash 内实现,在同一个终端窗口完成
1、前后台作业的定义
前后台作业实际上对应的也就是前后台进程,因此也就有对应的 pid。在这里统称为作业。
无论是前台作业还是后台作业,两者都来自当前的Shell,是当前Shell的子程序。
前台作业:可以由用户参与交互及控制的作业我们称之为前台作业。
后台作业:在内存可以自运行的作业,用户无法参与交互以及使用[ctrl]+c来终止,只能通过bg或fg来调用该 作业。
2、几个常用的作业命令
- command & 直接让作业进入后台运行
- [ctrl]+z 将当前作业切换到后台
- jobs 查看后台作业状态
- fg %n 让后台运行的作业n切换到前台来
- bg %n 让指定的作业n在后台运行
- kill %n 移除指定的作业
- n "n" 为jobs命令查看到的job编号,不是进程id。
- 每一个job会有一个对应的job编号,编号在当前的终端从1开始分配。
- job 编号的使用样式为[n],后面可能会跟有 "+" 号或者 "-" 号,或者什么也不跟。
- "+" 号表示最近的一个job, "-" 号表示倒数第二个被执行的Job。
- 注,"+" 号与 "-" 号会随着作业的完成或添加而动态发生变化。
- 通过jobs方式来管理作业,当前终端的作业在其他终端不可见。
3、演示后台作业命令
# 直接将作业放入到后台(附加 & 符号) [root@hostname ~]# tar ‐czvf temp.tar.gz qfedu.tar.gz & [1] 12500 [root@hostname ~]# qfedu.tar.gz [root@hostname ~]# # 此时可进行其它操作,作业一旦完成,会弹出如下的提示 [1]+ Done tar ‐czvf temp.tar.gz qfedu.tar.gz [root@hostname ~]# ls ‐hltr temp* ‐rwxr‐xr‐x 1 robin oinstall 490M 2013‐05‐02 17:48 qfedu.tar.gz ‐rw‐r‐‐r‐‐ 1 robin oinstall 174M 2013‐05‐02 17:50 temp.tar.gz # 已经开始执行,但需要放入后台(使用[ctrl]+z) [root@hostname ~]# tar ‐czvf temp2.tar.gz qfedu.tar.gz qfedu.tar.gz [1]+ Stopped tar ‐czvf temp2.tar.gz qfedu.tar.gz [root@hostname ~]# jobs [1]+ Stopped tar ‐czvf temp2.tar.gz qfedu.tar.gz # 下面同时发布两个作业,并且在中途按下[ctrl]+z以便将当前作业提交到后台 [root@hostname ~]# find /u02 ‐type f ‐size +100000k [root@hostname ~]# find / ‐type f ‐size +100000k # 再次查看当前的jobs时,jobs管理器里出现了3个处于stopp状态的job [root@hostname ~]# jobs [1] Stopped tar ‐czvf temp2.tar.gz qfedu.tar.gz [2]‐ Stopped find / ‐type f ‐size +100000k [3]+ Stopped find /u02 ‐type f ‐size +100000k [root@hostname ~]# jobs ‐l # 使用‐l参数查看当前Shell下所有的作业以及对应的job number,进程pid [1] 32682 Stopped tar ‐czvf temp2.tar.gz qfedu.tar.gz [2]‐ 32687 Stopped find /u02 ‐type f ‐size +100000k [3]+ 32707 Stopped find / ‐type f ‐size +100000k # 下面通过pid可以查看到对应的进程信息 [root@hostname ~]# ps ‐ef | grep 32707 | grep ‐v grep robin 32707 32095 0 09:48 pts/1 00:00:00 find / ‐type f ‐size +100000 [root@hostname ~]# tty # 当前终端的信息为pts/1 /dev/pts/1 # 打开另外一个终端 [root@hostname ~]# tty /dev/pts/3 [root@hostname ~]# jobs # 此时可以看到jobs命令无任何返回 [root@hostname ~]# ps ‐ef | grep 32707 | grep ‐v grep # 仅仅根据进程id可以找到对应的作业 robin 32707 32095 0 09:48 pts/1 00:00:00 find / ‐type f ‐size +100000 # 由上可知,对于当前 Shell 下的 jobs,仅当前 Shell (终端)可见 # 将后台作业切换到前台(fg命令) [root@hostname ~]# fg # 省略 Job number 的情形,则将缺省的 job 切换到前台 find / ‐type f ‐size +100000k /u02/database/old/BK/undo/undotbsBK.dbf ...... [ctrl]+z [root@hostname ~]# fg %1 tar ‐czvf temp2.tar.gz qfedu.tar.gz [root@hostname ~]# jobs [2]‐ Stopped find /u02 ‐type f ‐size +100000k [3]+ Stopped find / ‐type f ‐size +100000k # 运行后台中暂停的作业(bg命令) # 前面有2个job处于stopped状态,现在我们让其在后台运行,直接输入bg命令则缺省的job继续运行,否则输入job编 号,运行指定的job [root@hostname ~]# bg 2 # 输入bg 2之后,可以看到原来的命令后被追加了& [2]‐ find /u02 ‐type f ‐size +100000k & [root@hostname ~]# jobs [2]‐ Running find /u02 ‐type f ‐size +100000k & [3]+ Stopped find / ‐type f ‐size +100000k # 移除指定的作业n(kill) [root@hostname ~]# jobs [3]+ Stopped find / ‐type f ‐size +100000k [root@hostname ~]# kill ‐9 %3 # 强制终止job 3,注意,此处的%不可省略 [root@hostname ~]# jobs [3]+ Killed find / ‐type f ‐size +100000k [root@hostname ~]# jobs # kill ‐9 表明强制终止指定的Job,‐15则表明是正常终止指定的job。 kill ‐l 则列出kill能够使用的所有信号 # 对于上述命令的详细帮助,使用 man command来获取帮助信息 # 带参Shell脚本的后台处理 # 下面是一个测试用的Shell脚本 [root@hostname ~]#more echo_time.sh #!/bin/bash time=$(date) echo $time # 直接执行带参的Shell脚本 [root@hostname ~]#./echo_time.sh Fri Feb 14 19:18:40 CST 2019 [1]+ Stopped ./echo_time.sh #按下[ctrl]+z将其切换到后台 [root@hostname ~]#jobs 4、作业脱机管理 1. 将作业(进程)切换到后台可以避免由于误操作如[ctrl]+c等导致的job被异常中断的情形,而脱机管理主要是针 对终端异常断开的情形。 2. 通常使用nohup命令来使得脱机或注销之后,Job依旧可以继续运行。也就是说nohup忽略所有挂断(SIGHUP) 信号。 3. 如果该方式命令之后未指定&符号,则job位于前台,指定&符号,则job位于后台。 [1]+ Stopped ./echo_time.sh [root@hostname ~]#kill ‐9 %1 #强制终止该job [1]+ Stopped ./echo_time.sh [root@hostname ~]#jobs #此时该job已经被标记为killed [1]+ Killed ./echo_time.sh [root@hostname ~]#./echo_time.sh & #将Shell脚本参数之后跟 &符号即将job放入到后台 [1] 2233 [root@hostname ~]# #此时依旧可以看到有输出,但可以继续后续操作 TODAY ‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐ 2019‐05‐03 11:08:25 [root@hostname ~]# jobs [1]+ Running ./echo_time.sh & [root@hostname ~]# ./echo_time.sh >temp.log 2>&1 & #最佳的办法是直接将其输出到日志文件 [2] 2256 [root@hostname ~]# jobs [1]‐ Running ./echo_time.sh & [2]+ Running ./echo_time.sh >temp.log 2>&1 & # 下面来查看日志,日志中的两次查询正好相差5分钟 [root@hostname ~]# more temp.log
4、作业脱机管理
1. 将作业(进程)切换到后台可以避免由于误操作如[ctrl]+c等导致的job被异常中断的情形,而脱机管理主要是针 对终端异常断开的情形。
2. 通常使用nohup命令来使得脱机或注销之后,Job依旧可以继续运行。也就是说nohup忽略所有挂断(SIGHUP) 信号。
3. 如果该方式命令之后未指定&符号,则job位于前台,指定&符号,则job位于后台。
#下面是使用nohup的示例,可以省略日志的输出,因为原job的输出会自动被nohup重定向到缺省的nohup.out日志文件 [root@hostname ~]# nohup ./echo_time.sh nohup: appending output to `nohup.out' # 直接断开终端,并重新连接一个新的终端窗口 [root@hostname ~]# jobs # 由于是一个新的终端,所以jobs无法看到任何作业 [root@hostname ~]# ps ‐ef | grep echo_time.sh robin 2623 1 0 11:26 ? 00:00:00 /bin/bash ./echo_time.sh [root@hostname ~]# more nohup.out # 其输出的日志可以看到job被成功完成 Fri Feb 14 19:18:40 CST 2019 #下面使用 nohup方式且将 Job 放入后台处理,同时指定了日志文件,则nohup使用指定的日志文件,而不会输出到缺 省的nohup.out [root@hostname ~]# nohup ./echo_time.sh >temp2.log 2>&1 & [1] 3019 [root@hostname ~]# jobs [1]+ Running nohup ./echo_time.sh >temp2.log 2>&1 &
6、输入输出重定向
一般情况下,计算机从键盘读取用户输入的数据,然后再把数据拿到程序(C语言程序、Shell 脚本程序等)中使 用;这就是标准的输入方向,也就是从键盘到程序。
程序中产生数据直接呈现到显示器上,这就是标准的输出方向,也就是从程序到显示器。输入输出方向就是数据的 流动方向:
- 输入方向就是数据从哪里流向程序。数据默认从键盘流向程序,如果改变了它的方向,数据就从其它地方流 入,这就是输入重定向。
- 输出方向就是数据从程序流向哪里。数据默认从程序流向显示器,如果改变了它的方向,数据就流向其它地 方,这就是输出重定向。
1、硬件设备和文件描述符
- 计算机的硬件设备有很多,常见的输入设备有键盘、鼠标等,输出设备有显示器、投影仪、打印机等。不 过,在 Linux中,标准输入设备指的是键盘,标准输出设备指的是显示器。
- Linux 中一切皆文件,包括标准输入设备(键盘)和标准输出设备(显示器)在内的所有计算机硬件都是文 件。
- 为了表示和区分已经打开的文件,Linux 会给每个文件分配一个 ID,这个 ID 就是一个整数,被称为文件描述符(File Descriptor)
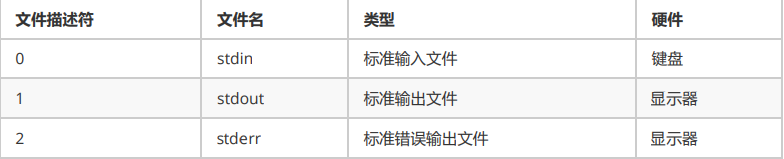
Linux 程序在执行任何形式的 I/O 操作时,都是在读取或者写入一个文件描述符。一个文件描述符只是一个和 打开的文件相关联的整数,它的背后可能是一个硬盘上的普通文件、FIFO、管道、终端、键盘、显示器,甚 至是一个网络连接。
stdin、stdout、stderr 默认都是打开的,在重定向的过程中,0、1、2 这三个文件描述符可以直接使用。
2、shell输出重定向
输出重定向是指命令的结果不再输出到显示器上而是输出到其他地方,一般是文件中。这样做的最大好处就是把命令结果保存起来,当我们需要时,可以随时查询,Bash支持的重定向符号如下
| 类型 | 符号 | 作用 |
| 标准输出重 定向 | command >file | 以覆盖的方式,把 command 的正 确输出结果输出到 file 文件中。 |
| command >>file | 以追加的方式,把 command 的正确输出结果输 出到 file 文件中。 | |
| 标准错误输 出重定向 | command 2>file | 以覆盖的方式,把 command 的错 误信息输出到 file 文件中。 |
| command 2>>file | 以追加的方式,把 command 的错误信息输出到 file 文件中。 | |
| 正确输出和 错误信息同 时保存 | command >file 2>&1 | 以覆盖的方式,把正确输出和错误信息同事保存到一个文件中 |
| command >>file 2>&1 | 以追加的方式,把正确输出和错误信息同时保存到 同一个文件(file)中。 | |
| command >file1 2>file2 | 以覆盖的方式,把正确的结果输出到file1文件中,把错误的文件输出到file2文件中 | |
| command >>file1 2>>file2 | 以3追加的方式,把正确的输出结果输入到file1文件中,把错误的信息输出到file2问你中 | |
| command > file 2>file | 不推荐,这种写法会导致file 文件被打开2次,引发资源竞争 | |
注意: 输出重定向中,> 代表的是覆盖,>> 代表的是追加。
输出重定向的完整写法其实是 fd>file 或者 fd>>file ,其中 fd 表示文件描述符,如果不写,默认为 1,也就是 标准输出文件。
当文件描述符为 1 时,一般都省略不写,如上表所示;当然,如果你愿意,也可以将 command >file 写作 command 1>file,但这样做是多此一举。
当文件描述符为大于 1 的值时,比如 2,就必须写上。 需要重点说明的是,fd 和 >之间不能有空格,否则 Shell 会解析失败;> 和 file 之间的空格可有可无。为了保 持一致,习惯在 > 两边都不加空格。
3、/dev/null文件
如果不想把命令的输出结果保存到文件,也不想把命令的输出结果显示到屏幕上,干扰命令的执行,可以把 命令的所有结果重定向到 /dev/null 文件中
root@hostname ~]# ls ‐l &>/dev/null
可以把 /dev/null 当成 Linux 系统的垃圾箱,任何放入垃圾箱的数据都会被丢弃,不能恢复
4、输入重定向
输入重定向就是改变输入的方向,不再使用键盘作为命令输入的来源,而是使用文件作为命令的输入
| 符号 | 说明 |
|
command |
将file文件中的内容作为command的输入 |
|
command |
从标准输入(键盘)读取数据,直到遇见分界符END才停止(分解符可以是任意的字符串,或者用户自定义) |
| command file2 | 将file1,作为command的输入,并将command的处理结果输出的file2. |
输入重定向举例
统计文档中有多少行文字。
- Linux wc 命令可以用来对文本进行统计,包括单词个数、行数、字节数,
- wc [选项][文件名]
- -c 选项统计字节数,-w 选项统计单词数,-l 选项统计行数。
1)统计 readme.txt 文件中有多少行文本:
[root@hostname~]# cat readme.txt # 预览一下文件内容 [root@hostname ~]# wc ‐l < readme.txt # 输入重定向
2)逐行读取文件内容
#!/bin/bash while read str; do echo $str done <readme.txt