参考了http://www.cnblogs.com/chaoku/p/3748456.html?utm_source=tuicool的代码。不过他的代码细节上有点问题。主要在于对于质心的处理上,他的代码中将前面的序号也作为数据进行求距离,但是这里是不用的。
kmeans基本思想就是在一个点集中随机选取k个点作为初始的质心,然后在以这K个点求点集中其他点和这质心的距离,并且按照最近的原则,将这个点集分成k个类,接着在这k个类中求其质心,接着便是迭代,一直到质心不变或者SSE小于某个阈值或者达到指定的迭代次数。不过这样的Kmeans有几个缺点1 我们如何确定K值,2初始的质心选取很重要。基于此,可以用二分kmeans(似乎是叫这个),如果有时间可以写一下。
Kmeans之所以能用MapReduce是因为Kmeans中有个计算质心的过程,而这个过程可以并行计算。不过用MapReduce似乎有一个不好的地方,就是他的这个迭代过程比较蛋疼,每次需要把数据放到HDFS,然后再删除,再读取,感觉反而会消耗很多资源,不过没有验证过,仅仅是自己的瞎想。
接下来说下思路。
1map用于求点集中各个点和k个质心的距离,选择最近的质心,key是那个质心对应的序号,value是那个点
2 reduce此时接受到的数据是相同质心的点集,接着要做的是便是求质心,对于相同质心的那个点集,求各列的平均值,以此作为新的质心。
3 以上这样就是一次跌代过程。显然一次迭代是不够的。那么如何用MapReduce进行迭代呢。
我们可以写一个判断条件,就是用于比较新的质心和旧的质心距离是否为0(也可以加上是否达到迭代次数,或者小于某个阈值等)。附上代码
1 while(true ){ 2 run(centerPath,dataPath,newCenterPath,true); 3 System. out.println(" " ); 4 System. out.println("The " + ++count+"th time's compution is completed"); 5 System. out.println(" " ); 6 if(Utils.CompareCenters(centerPath,newCenterPath)){ 7 Utils. deleteDir(newCenterPath); 8 break; 9 10 } 11 12 }
这里的CompareCenters就是一个用于判断的条件,如果是的话就break。否则就继续run。
具体说明下过程:
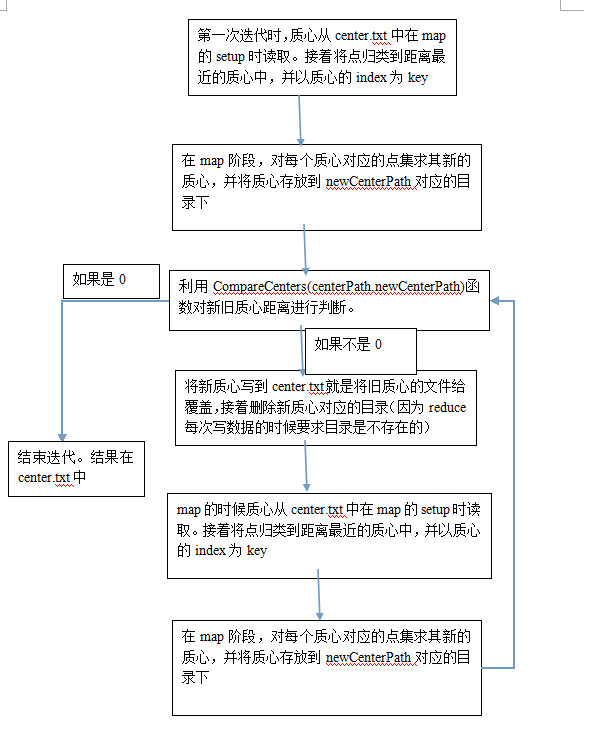
PS这里主要涉及了3个技术点
1 理解kmeans
2 会使用MapReduce迭代。一开始自己写的MapReduce都是直接在main下写了,没有run方法,后来才知道可以用run来启动,job.waitForCompletion(true)这句话比较重要,当时忘记在run里面写了,结果一直出错。
3 会hadoop的文件操作,比如删除文件,写数据等。
具体附上代码
1 package hadoop.MachineLearning.kmeans; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.conf.Configuration; 6 import org.apache.hadoop.fs.Path; 7 import org.apache.hadoop.io.IntWritable; 8 import org.apache.hadoop.io.Text; 9 import org.apache.hadoop.mapreduce.Job; 10 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 11 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 12 13 public class Kmeans { 14 15 public static void run(String centerPath,String dataPath,String newCenterPath,boolean runReduce) throws IOException, ClassNotFoundException, InterruptedException{ 16 Configuration conf =new Configuration(); 17 18 conf.set("centerPath",centerPath); 19 Job job=Job.getInstance(conf,"Kmeans"); 20 job.setJarByClass(hadoop.MachineLearning.kmeans.Kmeans.class); 21 job.setMapperClass(MyMapper.class); 22 job.setMapOutputKeyClass(IntWritable.class); 23 job.setMapOutputValueClass(Text.class); 24 if(runReduce){ 25 job.setReducerClass(MyReducer.class); 26 job.setOutputKeyClass(Text.class); 27 job.setOutputValueClass(Text.class); 28 } 29 30 FileInputFormat.addInputPath(job,new Path(dataPath)); 31 FileOutputFormat.setOutputPath(job,new Path(newCenterPath)); 32 System.out.println(job.waitForCompletion(true)); 33 34 } 35 36 public static void main(String[] args) throws Exception { 37 String centerPath="hdfs://10.107.8.110:9000/Kmeans_input/center_input/centers.txt"; 38 String dataPath="hdfs://10.107.8.110:9000/Kmeans_input/data_input/data.txt"; 39 String newCenterPath="hdfs://10.107.8.110:9000/Kmeans_output/newCenter"; 40 int count=0; 41 42 43 while(true){ 44 run(centerPath,dataPath,newCenterPath,true); 45 System.out.println(" "); 46 System.out.println("The "+ ++count+"th time's compution is completed"); 47 System.out.println(" "); 48 if(Utils.CompareCenters(centerPath,newCenterPath)){ 49 Utils.deleteDir(newCenterPath); 50 break; 51 52 } 53 54 } 55 56 57 } 58 59 }
package hadoop.MachineLearning.kmeans; import java.io.IOException; import java.util.ArrayList; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class MyMapper extends Mapper<LongWritable, Text, IntWritable, Text> { ArrayList<ArrayList<Double>> centerList=new ArrayList<ArrayList<Double>>(); public void setup(Context context) throws IOException{ Configuration conf=context.getConfiguration(); String centerPath=conf.get("centerPath"); centerList=Utils.GetCenterFromHDFS(centerPath,false); } public void map(LongWritable ikey, Text ivalue, Context context) throws IOException, InterruptedException { ArrayList<Double> point=Utils.TextToArray(ivalue); // int size=point.size(); double distance=0.0; double mindis=9999.0; int index=-1; for(int i=0;i<centerList.size();i++){ double currentDistance=0; for(int j=1;j<point.size();j++){//原文是j=0 double centerPoint = Math.abs(centerList.get(i).get(j)); double filed = Math.abs(point.get(j)); currentDistance += Math.pow((centerPoint - filed) / (centerPoint + filed), 2); } if(currentDistance<mindis){ mindis=currentDistance; index=i; } } /* for(int i=0;i<centerList.size();i++){ distance=Utils.getDistance(centerList.get(i),point); if(distance<mindis){ mindis=distance; index=i+1; } } */ // String value=""; context.write(new IntWritable(index+1),ivalue); } }
package hadoop.MachineLearning.kmeans; import java.io.IOException; import java.util.ArrayList; import java.util.Arrays; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class MyReducer extends Reducer<IntWritable, Text, Text, Text> { public void reduce(IntWritable _key, Iterable<Text> values, Context context) throws IOException, InterruptedException { // process values ArrayList<ArrayList<Double>> pointList=new ArrayList<ArrayList<Double>>(); for (Text val : values) { ArrayList<Double> point=Utils.TextToArray(val); pointList.add(point); } int row=pointList.size(); int col=pointList.get(0).size(); double[] avg=new double[col]; for(int i=1;i<col;i++){//原文是i=0 double sum=0; for(int j=0;j<row;j++){ sum+=pointList.get(j).get(i); } avg[i]=sum/row; } context.write(new Text("") , new Text(Arrays.toString(avg).replace("[", "").replace("]", ""))); } }
package hadoop.MachineLearning.kmeans; import java.io.IOException; import java.util.ArrayList; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileStatus; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.Text; import org.apache.hadoop.util.LineReader; public class Utils { /** * @param args * @throws IOException */ public static ArrayList<Double> TextToArray(Text text){ ArrayList<Double> centers=new ArrayList<Double>(); String[] line=text.toString().split(","); for(int i=0;i<line.length;i++){ double center=Double.parseDouble(line[i]); centers.add(center); } return centers; } public static ArrayList<ArrayList<Double>> GetCenterFromHDFS(String centerPath,boolean isDirectory) throws IOException{ Configuration conf=new Configuration(); Path path=new Path(centerPath); FileSystem fs=path.getFileSystem(conf); ArrayList<ArrayList<Double>> result=new ArrayList<ArrayList<Double>>(); if(isDirectory){ FileStatus[] fileStatus=fs.listStatus(path); for(int i=0;i<fileStatus.length;i++){ if(fileStatus[i].isFile()){ result.addAll(GetCenterFromHDFS(fileStatus[i].getPath().toString(),false)); } } return result; } FSDataInputStream infs=fs.open(path); LineReader reader=new LineReader(infs,conf); Text line=new Text(); while(reader.readLine(line)>0){ ArrayList<Double> center=TextToArray(line); result.add(center); } reader.close(); return result; } public static void deleteDir(String deletepath) throws IOException{ Configuration conf=new Configuration(); Path path=new Path(deletepath); FileSystem fs=path.getFileSystem(conf); fs.delete(path,true); } public static boolean CompareCenters(String oldPath,String newPath) throws IOException{ ArrayList<ArrayList<Double>> oldcenters=Utils.GetCenterFromHDFS(oldPath,false); ArrayList<ArrayList<Double>> newcenters=Utils.GetCenterFromHDFS(newPath,true); // // System.out.println(" "); // // System.out.println("oldcenters's size is "+oldcenters.size()); // System.out.println("newcenters's size is "+newcenters.size()); // // System.out.println(" "); int row=oldcenters.size(); int col=oldcenters.get(0).size(); double distance=0.0; for(int i=0;i<row;i++){ for(int j=1;j<col;j++){ double oldpoint=Math.abs(oldcenters.get(i).get(j)); double newpoint=Math.abs(newcenters.get(i).get(j)); distance+=Math.pow((oldpoint-newpoint)/(oldpoint+newpoint),2); } } if(distance==0.0){ Utils.deleteDir(newPath); return true; }else{ Configuration conf = new Configuration(); Path outPath = new Path(oldPath); FileSystem fs=outPath.getFileSystem(conf); FSDataOutputStream overWrite=fs.create(outPath,true); overWrite.writeChars(""); overWrite.close(); Path inPath=new Path(newPath); FileStatus[] listFiles=fs.listStatus(inPath); for(int i=0;i<listFiles.length;i++){ FSDataOutputStream out=fs.create(outPath); FSDataInputStream in=fs.open(listFiles[i].getPath()); IOUtils.copyBytes(in,out,4096,true); } Utils.deleteDir(newPath); } return false; } public static double getDistance(ArrayList<Double> point1,ArrayList<Double> point2){ double distance=0.0; if(point1.size()!=point2.size()){ System.err.println("point size not match!!"); System.exit(1); }else{ for(int i=0;i<point1.size();i++){ double t1=Math.abs(point1.get(i)); double t2=Math.abs(point2.get(i)); distance+=Math.pow((t1-t1)/(t1+t2),2); } } return distance; } public static void main(String[] args) throws IOException { // TODO Auto-generated method stub String oldpath="hdfs://10.107.8.110:9000/Kmeans_input/center_input/centers.txt"; String newpath="hdfs://10.107.8.110:9000/Kmeans_input/test"; if(Utils.CompareCenters(oldpath,newpath)){ System.out.println("equals"); }else{ System.out.println("not equals"); } /* ArrayList<ArrayList<Double>> centers=Utils.GetCenterFromHDFS(path,true); for(ArrayList<Double> center:centers){ System.out.println(" "); for(double point:center){ System.out.println(point); } } */ //String deletepath="hdfs://10.107.8.110:9000/output/"; //Utils.deleteDir(deletepath); } }