一、垃圾回收机制详解
垃圾回收机制是Python解释器自带的一种机制,专门用来回收不可用变量值所占的内存空间。
引入垃圾回收机制的意义:释放系统中一些无用的内存空间,防止内存溢出,降低程序崩溃的风险。
原理分析:
(1)使用“引用计数”来跟踪和回收垃圾;
(2)使用“标记-清除”来解决容器中存在的循环引用问题;
(3)通过“分代回收”的方式来提高垃圾回收的效率。
引用计数值:变量值被变量名关联的次数
x = 18 y = x z = x list_1 = [10,x] dict_1 = {'age':x} 变量值13被引用的次数为5次 直接引用3次,间接引用2次 引用为地址传递,而非值传递,没有开辟新的内存空间
分析一个例子
x = 10 list_1 = ['a','b',[1,2,3],x] 列表里存储的是['a'的内存地址, 'b'的内存地址, [1,2,3] 的内存 地址,10的内存地址] x = 123 print(list_1) >> ['a','b',[1,2,3],10]
标记清除:主要是为了解决容器对象(list、set、dict、 clase、instance)引起的循环引用问题,这些容器对象都包含有对其他对象的引用。
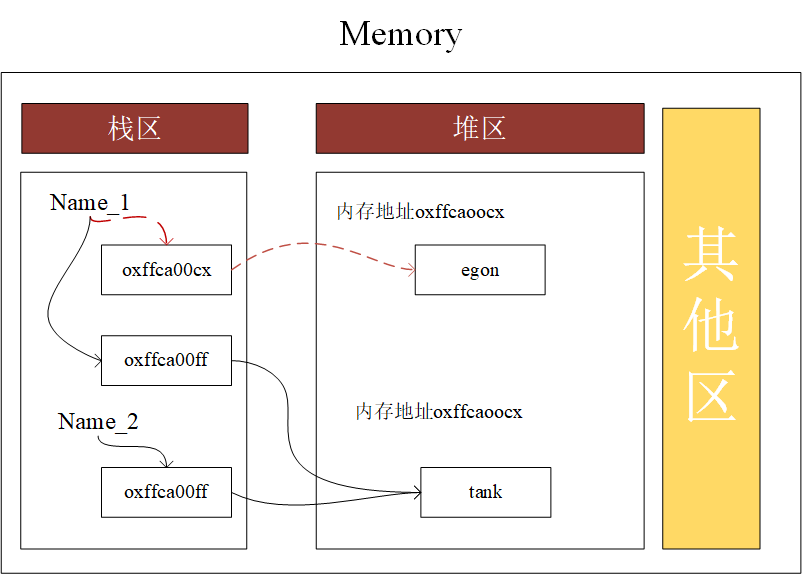
关于变量的存储,在内存中有两块区域——栈区和堆区,栈区存储的是变量名和变量值内存地址的关联关系,堆区存储的是变量值,内存管理回收的就是堆区的内容
name_1 = 'egon', name_2 = 'tank'
当执行 name_1 = name_2 时,在内存中变化如下:
标记/清除算法的做法是当应用程序可用的内存空间被耗尽的时,就会停止整个程序,然后进行两项工作,第一项则是标记,第二项则是清除 #1、标记 标记的过程其实就是,遍历所有的GC Roots对象(栈区中的所有内容或者线程都可以作为GC Roots对象),然后将所有GC Roots的对象可以直接或间接访问到的对象标记为存活的对象,其余的均为非存活对象,应该被清除。 #2、清除 清除的过程将遍历堆中所有的对象,将没有标记的对象全部清除掉。
分代回收
在历经多次扫描的情况下,都没有被回收的变量,gc机制就会认为,该变量是常用变量,gc对其扫描的频率会降低
分代回收的核心思想是:在历经多次扫描的情况下,都没有被回收的变量,gc机制就会认为,该变量是常用变量,gc对其扫描的频率会降低
二、格式化字符串(%s、format、f-string)
1、%占位符
%s占位符:可以接收任意类型的值 %d占位符,只能接受数字 name = input('please enter the name:').strip() height = int(input('please enter the height:').strip()) print('my name is %s , my height is %d' % (name,height))
2、str.format


(1)使用位置参数,按照位置一一对应 print('{} say {} is a good boy'.format('egon','tank')) egon say tank is a good boy (2)使用索引对应位置的值 print('{0} say {1} is a good boy, so many {2} like {1}'.format('egon','tank','girl')) egon say tank is a good boy, so many girl like tank (3)使用关键字参数或者字典 print('my name is {name}, my height is {height}'.format(height=187,name='tank')) my name is tank, my height is 187 user_info = {'name':'tank','age':18} print('The age of {name} is {age}'.format(**user_info)) 使用**进行解包操作 The age of tank is 18 (4)填充与格式化字符: 先取到值,然后在冒号后设定填充格式:[填充字符][对齐方式][宽度] # *<10:左对齐,总共10个字符,不够的用*号填充 print('{0:*<10}'.format('开始执行')) # 开始执行****** # *>10:右对齐,总共10个字符,不够的用*号填充 print('{0:*>10}'.format('开始执行')) # ******开始执行 # *^10:居中显示,总共10个字符,不够的用*号填充 print('{0:*^10}'.format('开始执行')) # ***开始执行*** (5)精度与进制 print('{salary:.3f}'.format(salary=1232132.12351)) #精确到小数点后3位,四舍五入,结果为:1232132.124 print('{0:b}'.format(123)) # 转成二进制,结果为:1111011 print('{0:o}'.format(9)) # 转成八进制,结果为:11 print('{0:x}'.format(15)) # 转成十六进制,结果为:f print('{0:,}'.format(99812939393931)) # 千分位格式化,结果为:99,812,939,393,931
3、f-strings(python3.5版本后出来的)
f-strings表示以f或者F开头的字符串,核心之处在于{}的使用
- {}可以是变量名
>>> name = 'egon' >>> age = 19 >>> f'The age of {name} is {age}' 'The age of egon is 19' >>>
- {}可以是任意合法的Python表达式
可以为数学表达式 print(f'{3/2%2}') 1.5 可以是函数 >>> def test(n): print('last year,the age of {name} is {age}'.format(name='tank',age=n)) return n+1 >>> print(f'this year the age of tank is {test(18)}') last year,the age of tank is 18 this year the age of tank is 19 >>> 可以使用对象的方法 name = 'egon' >>> print(f'who is {name.upper()}') who is EGON >>>
- 在类中使用
>>> class Person(object): ... def __init__(self, name, age): ... self.name = name ... self.age = age ... def __str__(self): ... return f'{self.name}:{self.age}' ... def __repr__(self): ... return f'===>{self.name}:{self.age}<===' ... >>> >>> obj=Person('egon',18) >>> print(obj) # 触发__str__ egon:18 >>> obj # 触发__repr__ ===>egon:18<=== >>> >>> >>> >>> # 在f-Strings中的使用 >>> f'{obj}' # 触发__str__ 'egon:18' >>> f'{obj!r}' # 触发__repr__ '===>egon:18<==='
三、基本运算符
在计算机中,人们可以进行多种类型的运算操作,包括算数运算、比较运算、逻辑运算、赋值运算、成员运算、身份运算、位运算。
- 算数运算符:+ - * / // ** %
# 3+2=5 # 3-2=1 # 3*2=6 # 3/2=1.5 # 3%2=1 # 3//2=1 # 3**2=9
- 比较运算
等于(==) 不等于(!= or <>) 大于(>) 小于(<) 大于等于(>=) 小于等于(<=)
- 赋值运算
= += -= *= /= //= %= **= - 逻辑运算
逻辑与(and):and两边式子的布尔值都为True,则为True,否则为False 逻辑或(or):or两边式子的布尔值只要有一个为True,则为True 逻辑非(!):将目标的布尔值取反 # 三者优先级: not>and>or #1、not与紧跟其后的那个条件是不可分割的 #2、如果条件语句全部由纯and、或纯or连接,按照从左到右的顺序依次计算即可 #3、如果语句中既有and也有or,那么先用括号把and的左右两个条件给括起来,然后再进行运算 # 短路运算(偷懒原则): 0 or 1 >> 1 1 and 3 >>3 0 and 2 and 3 >>0 0 and 2 or 1 >>1 0 and 2 or 1 or 4 >>1 0 or False and 1 >> False
- 身份运算
#is比较的是id #而==比较的是值 id相同,值一定相同;但是值相同,id不一定相同。