【tip】字符串编码的学习
【总结】:
(1)用什么编码,就用什么去解密码(用什么编码存的,就用什么编码去取)
#-*- coding:utf-8 -*- x = 'egon' x.encode('gbk') print(x.decode('gbk'))
(2)Python3 环境的str类型默认存为Unicode格式,而Python2中需要在在字符串变量值前面加上‘u’,即x=u'上',来保证str类型不乱码
(3)Python程序读取文件前两个阶段不乱码的core:
文件头加上: #-*- coding:保存到硬盘中的编码格式(如,gbk) -*-
(4)Python解释器读文件默认的字符串编码
#python2解释器:ASCII
#python3解释器:UTF_8
一、知识储备
1.1三大核心硬件:
# 软件运行前,软件的代码及其相关数据都是存放于硬盘中的 # 任何软件的启动都是将数据从硬盘中读入内存,然后cpu从内存中取出指令并执行 # 软件运行过程中产生的数据最先都是存放于内存中的,若想永久保存软件产生的数据,则需要将数据由内存写入硬盘
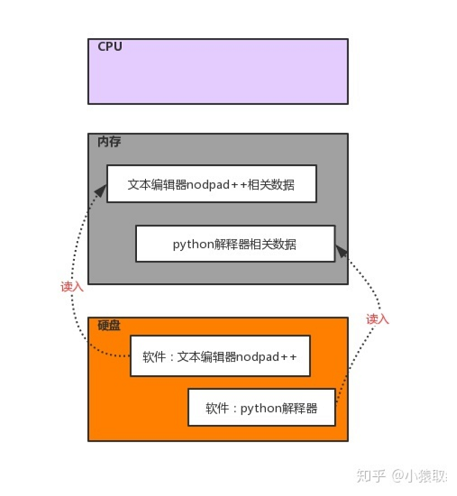
1.2文本编辑器与Python解释器读取文件的异同
#文本编辑器 1、启动一个文件编辑器 2、文件编辑器会将文件内容从硬盘读入内存 3、文本编辑器会将刚刚读入内存中的内容显示到屏幕上 #Python解释器 1、启动python解释器(相当于文本编辑器) 2、从硬盘上将test.py的内容读入到内存中 3、python解释器解释执行刚刚读入的内存的内容,开始识别python语法 #异同: 相同点:python解释器是解释执行文件内容的,因而python解释器具备读py文件的功能,这一点与文本编辑器一样 不同之处:文本编辑器将文件内容读入内存后,是为了显示或者编辑,根本不去理会python的语法,而python解释器将文件内容读入内存后,会执行python代码、识别python语法
二、字符编码的介绍
2.1、字符编码的发展历程
阶段一:美国(ASCII)
阶段二:中国(gbk)、日本(shift_js)、韩国(euc_kr)
阶段三:万国编码(unicode)
# Unicode ''' 1、兼容各国字符、与各国字符都有对应关系 2、采用16位(16bit=2Bytes)二进制数对应一个中文字符串,个别生僻会采用4Bytes、8Bytes ''' ''' # 英文字符可以被ASCII识别 英文字符--->unciode格式的数字--->ASCII格式的数字 # 中文字符、英文字符可以被GBK识别 中文字符、英文字符--->unicode格式的数字--->gbk格式的数字 # 日文字符、英文字符可以被shift-JIS识别 日文字符、英文字符--->unicode格式的数字--->shift-JIS格式的数字 '''

2.2、编码与解码
由字符转换成内存中的Unicode,以及由Unicode转换成其他编码的过程都称为编码。
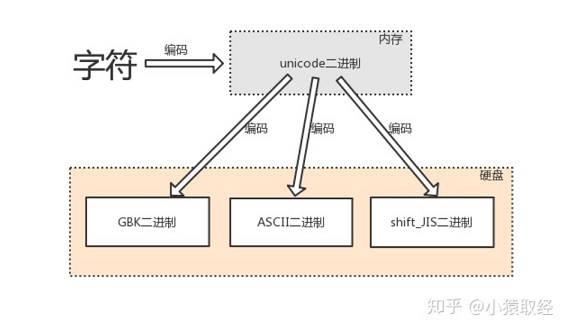
由内存中的Unicode转换成字符,以及其他编码转换成Unicode的过程,都称为解码decode

# 在诸多文件类型中,只有文本文件的内存是由字符组成的,因而文本文件的存取也涉及到字符编码的问题
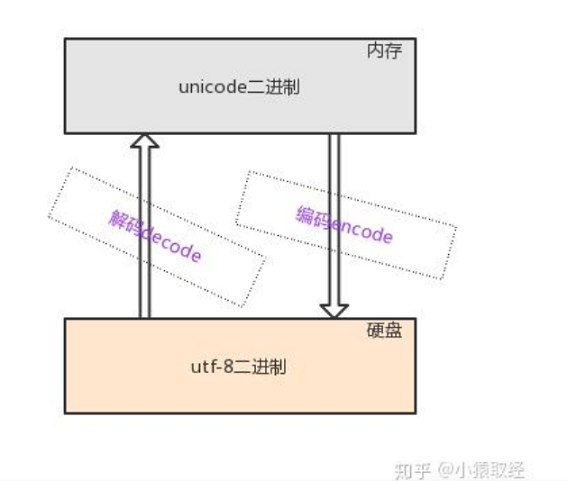
2.3、utf-8的由来
理论上可与将内存中的Unicode格式的二进制直接存放到硬盘中,但是由于Unicode固定使用两个字节来存储一个字符,这就使得如果我们输入的字符中包含大量的英文字符时,Unicode格式就会额外占用一部分空间,最为致命的是当我们由内存写入硬盘时会额外消耗一倍的时间也就是IO延迟时间,针对这种情况,也就产生了基于Unicode的一种精简格式——utf-8,它是Unicode的转换格式
# 多国字符—√—》内存(unicode格式的二进制)——√—》硬盘(utf-8格式的二进制)
2.4、字符编码的应用
#1. 保证存的时候不乱:在由内存写入硬盘时,必须将编码格式设置为支持所输入字符的编码格式 #2. 保证存的时候不乱:在由硬盘读入内存时,必须采用与写入硬盘时相同的编码格式
python解释器执行文件的前两个阶段
执行py文件时,必须将python解释器读文件时采用的编码方式设置为文件当初写入硬盘时的编码格式,如果没有设置,python解释器则才用默认的编码方式,在python3中默认为utf-8,在python2中默认为ASCII,我们可以通过指定文件头来修改默认的编码
python解释器执行文件的第三个阶段
设置文件头的作用是保证运行python程序的前两个阶段不乱码,经过前两个阶段后py文件的内容都会以unicode格式存放于内存中。 在经历第三个阶段时开始识别python语法,当遇到特定的语法name = '上'(代码本身也都全都是unicode格式存的)时,需要申请内存空间来存储字符串'上',这就又涉及到应该以什么编码存储‘上’的问题了。 在Python3中,字符串类的值都是使用unicode格式来存储 由于Python2的盛行是早于unicode的,因此在Python2中是按照文件头指定的编码来存储字符串类型的值的(如果文件头中没有指定编码,那么解释器会按照它自己默认的编码方式来存储‘上’),所以,这就有可能导致乱码问题
2.5、字符串encode与decode使用
# 1、unicode格式------编码encode-------->其它编码格式 >>> x='上' # 在python3在'上'被存成unicode >>> res=x.encode('utf-8') >>> res,type(res) # unicode编码成了utf-8格式,而编码的结果为bytes类型,可以当作直接当作二进制去使用 (b'xe4xb8x8a', <class 'bytes'>) # 2、其它编码格式------解码decode-------->unicode格式 >>> res.decode('utf-8') '上'
本文转自海峰老师的博客:
https://zhuanlan.zhihu.com/p/108805502