突然感觉kafka跟socket有点像,只是kafka具备更多的功能,是一个经典的消费者生产者模式。
kafka中有不同的topic,生产者可以把数据发送到不同的topic,消费可以指定相应的topic进行消费。
本文就kafka是什么,不做详细的介绍依旧是上两张图。
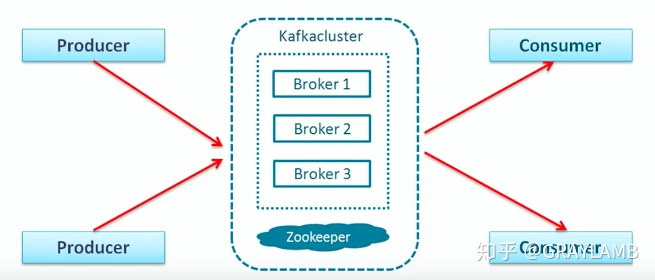
图一:展示了kafka的强大的扩展能力,扩展能力强了,自然吞吐能力会大大增强。
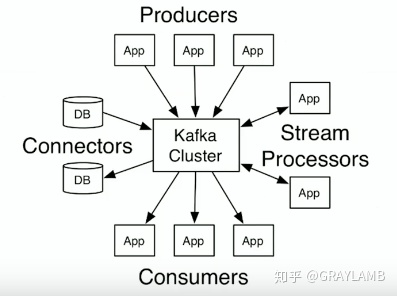
图二:展示了kafka的工作模式,也就是在业务上的扩展能力,业务能力很强。
本讲主要是在本地操作,首先你需要在本地下载一个kafka的服务,并且启动它,当前启动之前你肯定要先启动ZK,网上有大量的怎么在windows上启动kafka的教程
然后,在你项目中,根据你的spark版本可kafka的版本下载相应的驱动包(我理解成驱动包,有点类似于前面的数据库的驱动包,方便连接kafka和SparkStreaming)
我使用的pom.xml的配置如下:
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka-0-8_2.11</artifactId> <version>2.1.1</version> </dependency>
首先使用kafka 生产消息代码如下:
import java.util.HashMap import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord} object KafkaWordProducer { def main(args: Array[String]) { /** * 第1个参数localhost:9092是Kafka的broker的地址,第2个参数wordsender是topic的名称 * 第3个参数“3”表示每秒发送3条消息,第4个参数“10”表示,每条消息包含10个单词(实际上就是10个整数) */ val Array(brokers, topic, messagesPerSec, wordsPerMessage) = Array("localhost:9092","wordsender","3","10") // Zookeeper connection properties val props = new HashMap[String, Object]() props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers) props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer") props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer") val producer = new KafkaProducer[String, String](props) // Send some messages while(true) { (1 to messagesPerSec.toInt).foreach { messageNum => val str = (1 to wordsPerMessage.toInt).map(x => scala.util.Random.nextInt(10).toString).mkString(" ") println(str) val message = new ProducerRecord[String, String](topic, null, str) producer.send(message) } Thread.sleep(1000) } } }
运行情况如下:
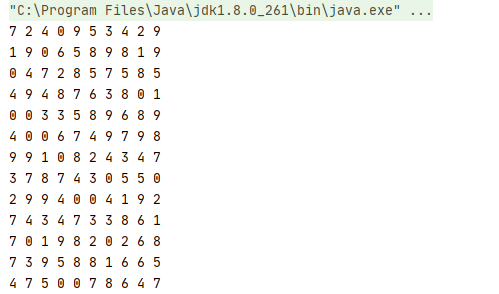
其次使用sparkStreaming来消费kafka生产的数据,并进行相应的数据操作,代码如下:
import org.apache.spark.SparkConf import org.apache.spark.streaming._ import org.apache.spark.streaming.kafka.KafkaUtils object SparkKafka { def main(args:Array[String]){ val sc = new SparkConf().setAppName("KafkaWordCount").setMaster("local[2]") val ssc = new StreamingContext(sc,Seconds(10)) ssc.checkpoint("file:///D:/2020Q4/spark_kafka/checkpoint") //设置检查点,如果存放在HDFS上面,则写成类似ssc.checkpoint("/user/hadoop/checkpoint")这种形式,但是,要启动hadoop val zkQuorum = "localhost:2181" //Zookeeper服务器地址 val group = "1" //topic所在的group,可以设置为自己想要的名称,比如不用1,而是val group = "test-consumer-group" val topics = "wordsender" //topics的名称 val numThreads = 1 //每个topic的分区数 val topicMap = topics.split(",").map((_,numThreads.toInt)).toMap val lineMap = KafkaUtils.createStream(ssc,zkQuorum,group,topicMap) val lines = lineMap.map(_._2) val words = lines.flatMap(_.split(" ")) val pair = words.map(x => (x,1)) val wordCounts = pair.reduceByKeyAndWindow(_ + _,_ - _,Minutes(2),Seconds(10),2) wordCounts.print ssc.start ssc.awaitTermination } }
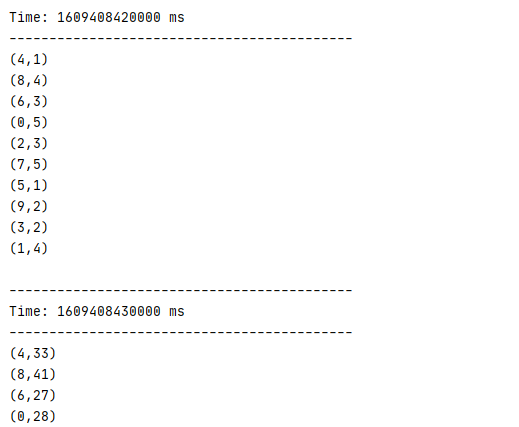
运行结果如下:
以上:)