操作系统 笔记(三)计算机体系结构,地址空间、连续内存分配(四)非连续内存分配:分段,分页

 5353
5353  收藏 13
收藏 13上课视频来源B站,http://www.bilibili.com/video/av6538245/
上一篇:操作系统from清华大学向勇,陈渝 笔记(二)操作系统的启动、中断、异常、系统调用
INDEX:
3-1 计算机体系结构&内存分层体系
3-2地址空间和地址生成
3-3连续内存分配:内存碎片与分区的动态分配
3-4 连续内存分配:压缩式/交换式碎片整理
4-1 非连续内存分配:分段
4-2 非连续内存分配:分页
4-3 非连续内存分配:页表—概述,TLB
4-4 非连续内存分配:页表—二级,多级页表
4-5 非连续内存分配:页表—反向页表inverted page table
3-1 计算机体系结构&内存分层体系
计算机体系结构/内存分层体系
基本硬件结构: CPU(程序执行处),内存(放置了代码和处理的数据),设备(I/O)
内存的层次结构: CPU的数据放的位置,寄存器和CACHE都在CPU内部,速度快容量小,主存(物理内存)放操作系统本身和应用,通过交换/分页和磁盘交互,将永久保存的数据放到磁盘中(虚拟内存),慢而容量大,5ms寻道时间。
操作系统对内存分配做了什么:
(1)抽象,逻辑地址空间;(2)保护,独立地址空间;(3)共享,访问相同内存;(4)虚拟化,更多的地址空间,对应用程序透明
操作系统管理内存的不同机制:
程序重定位,分段,分页,虚拟内存,按需分页虚拟内存
OS本身也是软件,实现高度依赖于硬件,要知道内存架构,MMU(内存管理单元,硬件组件中负责处理CPU的内存访问请求)
3-2地址空间和地址生成
地址空间的概念:
物理地址空间是硬件支持的地址空间
E.G:内存条代表的主存,硬盘代表的磁盘
起始地址空间0,到地址max
逻辑地址空间是一个运行的程序所具有的内存范围,一维线性
二者之间的交互,映射关系,落在物理地址空间上。
具体过程:
C程序通过编译,汇编,链接link,载入(程序重定位)生成EXE,将逻辑地址映射到物理空间上。C程序中函数的位置(入口),变量的名字就是逻辑地址,汇编后(.o文件)起始地址为0,把变量名和函数名转为相应的从0开始的连续逻辑地址,link把多个.o合成一个,放在硬盘中,通过loader应用程序再把exe放在内存中执行,这里有分配地址空间和映射(偏移)的过程。过程与os无关,编译器和loader来完成。此时得到的仍然是逻辑地址,
接下来,物理地址生成的四个步骤
1, CPU要在内存中执行指令,AOU需要知道这条指令的内容,发送请求,传参数,参数就是逻辑地址
2, 查表。根据CPU中的MMU(有块区域表示映射关系,如果在MMU没查到会去内存中的MAP找),查表逻辑地址->物理地址。
3, 找到后CPU给主存(就是内存)发请求,请求一个物理地址的内容(就是指令的内容)
4, 主存会通过总线把内容传给CPU,CPU执行指令。
操作系统的作用是在这些步骤之前建立好映射表。
以及地址安全检查
逻辑地址要检查起始地址和长度
OS设置逻辑地址的界限和基址,不对就抛出内存异常
CPU—逻辑地址—界限寄存器—–基址寄存器—物理地址—-内存
3-3 连续内存分配:内存碎片与分区的动态分配
物理内存分配可以分为连续分配和非连续分配。
连续分配会造成内存碎片问题,空闲内存不能被利用,外部碎片,在分配单元见的未使用内存,内部碎片,在分配单元中的未使用内存。
简单的内存管理方法:
当程序从硬盘加载到内存中时,要分配一个连续的区间;当应用程序需要访问数据时,要空间。
OS要跟踪。。。满块,空快(孔洞)
分配策略(貌似严蔚敏的数据结构课讲过?): 首次适配,最有适配,最差适配
1. 首次适配,从0地址往后查找和使用第一个可用空闲快(要比需要的空间大)。基本实现机制要求把空闲的内存块按地址排序。回收要考虑能否合并内存块。
优点:简单,易于产生更大的空闲快,向着地址空间的结尾
劣势:易产生外部碎片(随着动态分配加剧),不确定性
2. 最优适配:找比需求大但最接近需求的空闲内存块,产生尽可能小的内存碎片。原理是为了避免分配大空闲块,最小化外部碎片,要求对空闲地址快按尺寸size排序,回收要合并。
优点:当大部分分配需要小空间时使用,简单
缺点:外部碎片太小太细,不利于后续重分配。
3. WORSTFIT 最差匹配
使用最大的空闲快,大块拆分变小块,可以避免产生太多微小的碎片,也要排序,回收合并。
优势:分配中大型SIZE时实用
缺点:重分配慢,对大块的请求可能没得用了。
3-4 连续内存分配:压缩式/交换式碎片整理
- compression压缩式碎片整理
调整内存中程序运行的位置,通过拷贝尽量把程序放到一起,空出较多的空闲位置。拷贝要考虑何时去挪,不能在程序运行的时候挪,要在waiting时,和开销。 - 交换式碎片整理
硬盘当做内存的备份,把waiting的程序包括数据放在磁盘上,腾出空间给其余运行的程序。(抢占waiting程序回收其内存),也要考虑开销和换哪个程序
(四)非连续内存分配:分段,分页
4-1 非连续内存分配:分段
为什么需要非连续内存分配?
连续内存分配有碎片的缺点,对应非连续的优点:更好的内存利用和管理,允许共享代码和数据(共享库。。),支持动态加载和动态链接。最大的问题在于管理的开销。在虚拟地址和物理地址之间的转换,如果用软件来实现,开销巨大。因此要考虑用硬件来协同解决。
管理方法?
分段,分页机制,更好的分离和共享
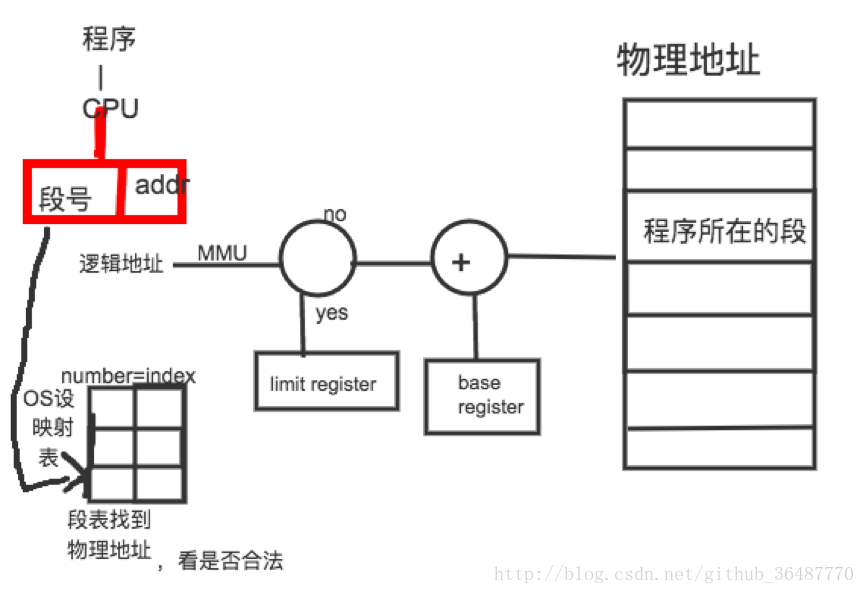
分段机制:程序的分段地址空间设计,寻址方案。
把逻辑地址空间分散到多个物理地址空间,堆-→堆,运行栈-→运行栈,程序数据-→数据,运行exe—>代码和库
寻址方案:
一维连续逻辑地址,把一个段看成一个内存块。程序访问内存地址分为两部分,段的寻址(段号segment number)+ 段内偏移的寻址(addr)
段寄存器+地址寄存器实现方案(x86)
单地址实现方案(s+addr合在一起)
硬件实现方案
4-2 非连续内存分配:分页
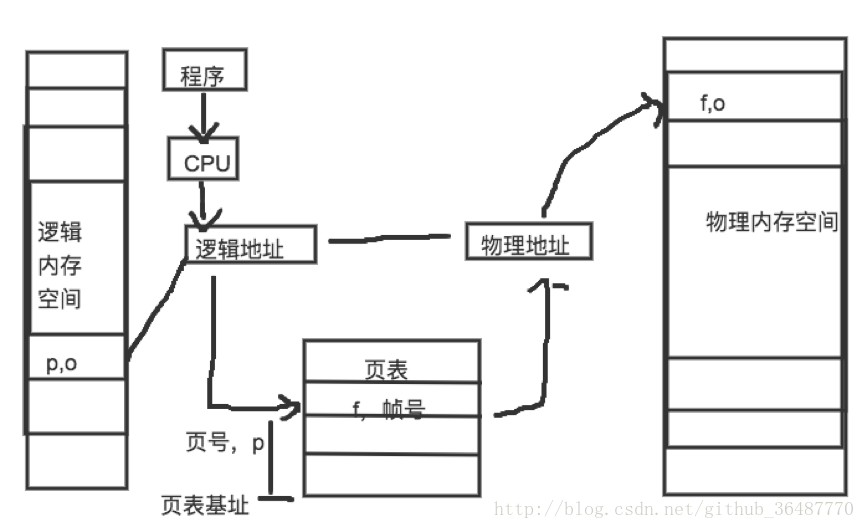
分页也是实现机制和寻址,也需要页号和偏移
类似,区别在于页帧的size不变。
划分物理内存至固定大小的帧frame(物理页),逻辑地址空间也要到相同大小的页(page,逻辑页)。两者大小要相等,为2的幂数,如512,4096,8192.。。
建立方案,change pages to frames,需要页表和MMU/TLB(快表,完成对MMU的缓存)。
Frame的概念:物理内存被分割成大小相等的帧,是一个二元组(frame number, offset)f—帧号,F位,共有2F个帧;o—帧内偏移,S位,每一帧有2S字节。
物理地址=2S * f + o
对16bit的地址空间,9bit大小的页帧,物理地址(3,6)
F=16-9=7 存帧号 未用到
S=9 帧内的位数
And f=3 frame number,o=6
代入=1542

page的计算方式与之类似,区别在于页号大小的size和帧号的大小可能不一致,但offset都是一样的。二元组(p,o)
虚拟地址=2S * p+ o
页寻址机制,其中OS建立的页表page table保存了逻辑地址—物理地址之间的映射关系。由页号查帧号。
特点:页内偏移大小一定,不需要考虑不同段大小不一致,硬件更易管理;PAGE的地址空间大小和FRAME的地址空间大小是不同的,一般前者更大,页是虚拟内存,连续,帧是不连续的物理内存,不是所有的页都有对应的帧,装不下时会用虚拟内存(以后会讲)。有助于减少碎片。
4-3 非连续内存分配:页表—概述,TLB
页表结构:
大数组,索引是page number,内容frame number
每个运行的程序都有一个页表,属于程序运行状态,会动态变化,PTBR(页表基址寄存器)。
页表项中除了frame number 还有标志位flags检查是否存在地址, including dirty bit, resident bit (是否存在该对应的物理地址)and clock/reference bit.
性能问题:
时间开销:页表太大不能放到CPU中,只能放内存,每次寻址一个内存单元需要2次内存访问,获取页表项和访问数据
空间开销:○1页表可能非常大,64位机器,寻址空间是2的64次幂,一个页size如果只有1024 1k,要建立一个极大的页表=254,存不下。○2n个程序对应n个页表,页表个数非常大。
两种解决方法:缓存(caching)和间接(indrection)访问
在cpu的MMU中,存在一个cache叫TLB translation look-aside Buffer ,缓存近期访问的页帧转换表项。首先CPU根据逻辑地址查快表TLB(key=p, value=f,由于使用关联内存(associate memory)实现,具备快速访问性能,很少超过64个表项,每个对应一个页面的相关信息。)如果命中,FRAME很快被获取,如果未命中MISS,则去查页表并更新对应的表项到TLB中。
TLB的缺失不会很大,32位一个页4K,访问4K次miss一次,可以接受。写程序时注意具有局部性,把频繁的访问集中在一个区域。以避免对内存的访问。另外,还需要注意,miss后,更新是硬件完成(x86),还是OS完成(现代机器,MIPS, SPARC, HP PA)。
4-4 非连续内存分配:页表—二级,多级页表
空间上怎么压缩页表?多级页表(参见数据结构中的多级索引表)
将大的PAGE的page number分为两部分P1&P2,OFFSET不变
多次访问,存俩表,开销大,怎么节省的呢?
通过省去P2中(p1 不存在映射关系,驻留位(resident bit==0)是0的页表项)对应的page table来省空间。应用程序适合这种方式。
推广→把页号分为k个部分,建立页表树。
64位通常是5级页表,以时间换空间,再用TLB来缓解时间上的开销
4-5 非连续内存分配:页表—反向页表inverted page table
由于2个问题:○1大地址空间(64-bits)使前向映射页表繁琐(5级),○2虚拟地址空间增长速度快鱼物理地址空间
因此,前向页表与逻辑空间地址的大小相关→反向页表则是与物理地址空间的大小相对应。
反向页表基于页寄存器,page registers, using frame as index while the content is occupier (page numbers),residence bit (是否被占用), protection bits.
优点:空间开销少。映射表的大小相对于物理内存很小,且与逻辑地址空间的大小无关。
E.G: 物理内存4K*4K=16M,页面大小是4KB,则页帧数为4K。
If 8 bytes per page register, then room for page registers is 8*4K=32KB
The extra cost of page registers is only 32K/16M=0.2%
问题在于怎么用页号找帧号?
关联内存 associate memory
类似TLB,并行查找,KEY是页号,value是帧号
但关联存储器用到的硬件逻辑很复杂,开销很大,本身size做不了多大,还需要放到CPU否则要二次访问。大的关联存储器也会造成时间开销大。
反向页表整体搜索机制
如果帧数少,放到关联内存中,在关联内存中查找逻辑页号,成功则提取帧号,失败抛出page fault。限制因素在于大量的关联内存很昂贵,难以在单个时钟周期内完成且耗电。
折中方案——-哈希表
用硬件加速,建立哈希表来实现反向页表。
对页号做哈希计算,页i放在表中funchash(i)的位置,求得f(i)作为页寄存器表的索引获取对应的页寄存器再检查标签是否有i。
问题:
- 会有碰撞,多个页帧号到底对应哪个,加入参数PID==ID of running program来缓解冲突;
- 哈希表在内存中,要访问内存,内存的时间开销还是很大
优点:本身物理存址小省空间,不再是每个应用程序都要page table了,整个系统只用一个。
缺点:需求高,有高效哈希函数和解决冲突的机制,要硬件软件配合