背景
2020年2月7日晚,由于武汉肺炎疫情影响,宅在家里即为国家贡献。此刻父亲在刷着抖音app,母亲在刷着快手app,而我作为一个it从业者开始思考互联网给我们带来了什么;概括总结起来互联网给人们带来了内容,服务这两大块,其中内容以文本,图片,音频,视频的形式呈现,并提供给网民信息知识,或者让网民愉悦心情。而服务呢,全部包含了人们的衣(电商)、食(外卖,团购)、住(自如租房)、行(打车)、消费(支付宝,微信)、交流(微信)、游戏(腾讯);可以说互联网已经改变了我们的生活习惯,我们也离不开互联网;作为普通用户可以很简单的拥有一部手机,然后买些流量可上网,下载如上所说的app,便能够尽享当下互联网的繁荣;然而作为一名程序猿更应该知晓这背后的一个个复杂的系统是如何的运作起来,特别的是当用户量很大,或者某个时刻激增的时候系统能否依然稳健运行,针对这个问题,我想浅谈《云计算》,《大数据》,《人工智能》。(知识水平有限,如有错误表述,请批评指正)
part1-云计算
为什么要云计算
基于合理高效利用计算资源的思想,将孤立的服务器通过云计算技术集中起来,虚拟化成一个云系统。这种云系统可类比为“金箍棒”,根据需要可灵活调节,如“针”,如“擎天柱”。
这种资源的整合集中有如下的好处。
- 节约固定资产成本开销,初创公司在探索尝试阶段,不用先投入高昂资本到物理服务器上;
- 极高灵活性,包括时间灵活性,空间灵活性,计算服务可关可开,可大可小;
- 扩容效率高,在某个时间段需要大量计算服务的场景下,(如淘宝双11,春运火车票购买),通过云计算技术可以高效升级资源服务;
云计算是什么
云计算的思想可类比为自来水厂集中供水,用户按需使用并缴纳相应水费;云计算的目标是资源的管理,主要涉及到计算资源、网络资源、存储资源;
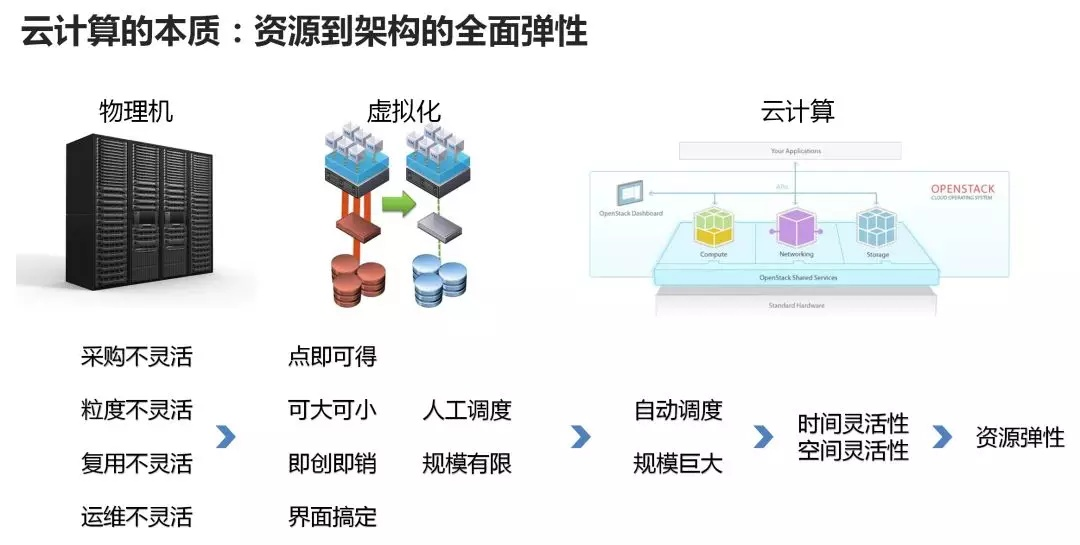
云计算的前辈-虚拟机,虚拟机属于半自动化,因为需要专业工作者的人工配置;而且这种虚拟化技术能够实现最大集群规模不过百台物理机。
以下是一些虚拟化的软件;
- vmware: 商业;稳定性强;花钱
- kvm:免费开源
- virtualbox:桌面级虚拟化;桌面级开源;对于生产并不适用
云计算的产生
1. 云计算领头羊亚马逊aws,亚马逊的电商业务也分淡季和旺季,淡季的时候就想使用少量的计算服务资源,而旺季的时候又必须很快使用到计算服务资源;此外使用商用的vmware需要花费高昂的费用。因此亚马逊基于开源的kvm虚拟化技术开发出aws云计算软件系统,并利用它赚了很多钱。
2. 云计算的老二rackspace与美国航空航天局合作开源了openstack,意图集结全球之力一起干亚马逊的云计算
云计算的分类
- 私有云:使用私有云的用户财大气粗,出于数据安全的考虑,只希望云厂商将云计算技术部署到自己的物理机器上;
- 公有云:云厂商自己提供物理机,并搭建维护起来的云服务,面向小微企业提供按需付费的服务;
云计算的三种业务模式
类比现实生活中“躺在家里床上,我想吃麦当劳汉堡”,这个汉堡如何能够出现在我的面前呢?(例子可能不太恰当)
- 汉堡从实体店里生产出,要有个麦当劳店铺,‘泥瓦匠们’装修了这个店铺(厨房、吧台、吊顶。。。)类比为laas,即基础设施服务
- 厨师在店铺里,揉面,热烤肠等制作出汉堡。类比为paas,即平台服务
- 我点了个外卖,获取了这个汉堡。支持送外卖的服务,类比为saas,即软件即服务
以计算机的角度理解如下
- laas:云计算成功部署实现对计算,网络,存储资源的弹性控制后,出现的资源管理平台,即为基础设施服务,laas
- paas:有了laas之后,还需要使应用层弹性,应用可分为通用的程序和自己开发的业务程序
- 通用的程序不用安装,一般放到标准的paas层;如spark、redis、mysql、hadoop、elasticsearch
- 自己的程序自动安装,需要自己做一些自动化部署脚本的工作
- 自己开发的脚本在不同的环境中会千差万别,在这个环境work,另外一个环境可能就不work,基于此容器的思想应运而生
- docker技术
- k8s技术,管理docker的平台
- openstack、docker、k8s的关系:https://blog.csdn.net/dualvencsdn/article/details/79207281
- 自己开发的脚本在不同的环境中会千差万别,在这个环境work,另外一个环境可能就不work,基于此容器的思想应运而生
- saas:软件即服务,是云计算最上层直接展现给用户的成品,用户按需进行付费使用
part2-大数据
为什么要大数据
- 互联网发展,网民产出了海量的数据。
- 如何对海量数据进行价值提取,涉及到如下环节
- 海量数据收集
- 海量数据传输
- 海量数据存储
- 海量数据计算
大数据涉及的关键技术
- 数据收集:多台机器分工协作完成收集,最后再汇总。
- 数据传输:一个内存里面的队列肯定会被大量的数据挤爆掉,于是就产生了基于硬盘的分布式队列,这样队列可以多台机器同时传输,随你数据量多大,只要我的队列足够多,管道足够粗,就能够撑得住。
- 数据存储:一台机器的文件系统肯定是放不下的,所以需要一个很大的分布式文件系统来做这件事情,把多台机器的硬盘打成一块大的文件系统。
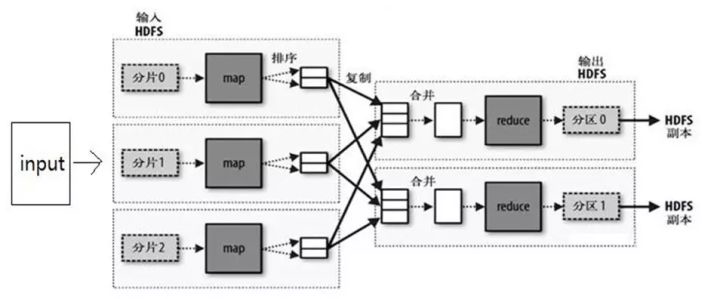
- 数据计算:一台机器处理大文件肯定耗时严重,采用分布式计算的思想,如hadoop、spark等,多台机器协作处理,大大提升了任务的效率。
part3-人工智能
为什么要人工智能
人类发明计算机的终极梦想是实现机器像人一样能够对知识有归纳,演绎的能力。当计算机赋有这样的能力后,就可以帮助人类做很多事情,例如(人脸识别,机器翻译,语音识别,个性化推荐等等)。
当前人工智能如何实现
- 对知识归纳:机器学习阶段,即是输入要学习的数据,进行模型训练,产出模型的过程;
- 对知识演绎:模型应用阶段,让模型能够很好的对新知识进行预测;
人工智能-对于文本处理完整的任务流程
- 模型
- 机器学习:LR、SVM 、LDA、GBDT、XGB、PCA、simhash、kmeans、knn、决策树、随机森林等
- 深度学习-文本分类:fasttext、textcnn、han、dpcnn
- 深度学习-文本相似:simnet(双塔网络)
- 深度学习-机器翻译:transformer
- 损失函数
- MSE(L2 loss)、L1 loss、交叉熵、log loss
- 优化器
- sgd、adam、adagrad
- 数据输入
- 样本构成
- 训练集合(针对二分类,一般正负样本量=1:1)
- 测试结合(同上)
- 数据样式
- 对于深度学习embeding过程:文本一般会look up词表,转成id数字
- 对于机器学习:往往构造特征
- 样本构成
- 模型效果评估的常用指标(对于分类任务)
- 训练集、测试集上的:准确率、召回率
- F1-score
- auc
参考
https://zhuanlan.zhihu.com/p/35996270?utm_source=wechat_session&utm_medium=social&utm_oi=696370488514998272