学习语音识别有些时间了。老板要求我们基于Kaldi搭一个语音识别系统,在设备上通过MIC讲话,连着设备的PC的console上就能基本实时显示出讲话的内容。由于我们都是小白,刚开始可以要求低些,就用传统的GMM-HMM,能实现孤立词识别就算达标了,后面随着这方面能力的提高,再做更难一点的。任务下达后我根据之前对kaldi的简单理解把模块分成了三部分:数据准备和MFCC、GMM-HMM、解码网络创建和解码,由三个人每人负责一部分学习,掌握基本原理,搞清楚有哪些事情要做。在其他两个同学先挑了模块后就由我来负责解码网络构建和解码部分了。
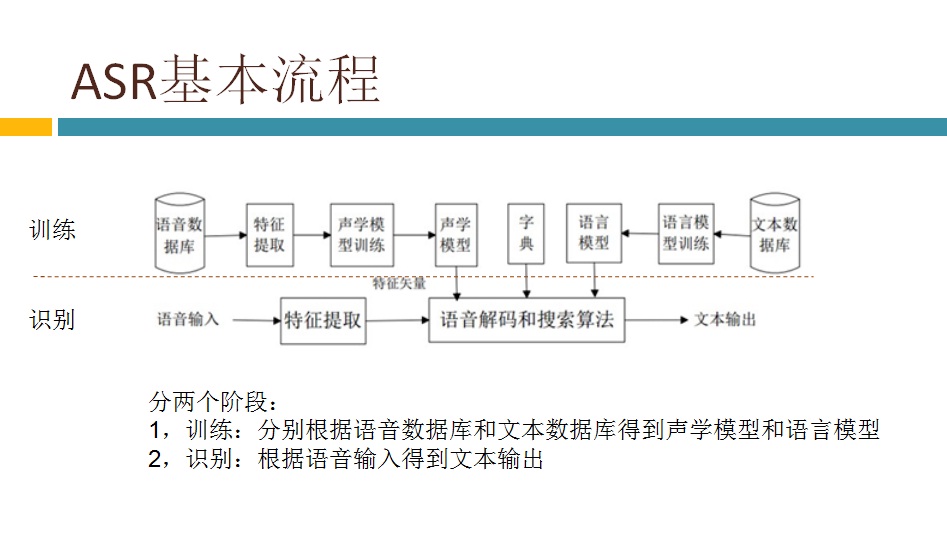
我们三个学习了kaldi两三个星期后感觉下来kaldi不是很容易上手,主要原因有四。一是我们都是新手,语音识别领域的一些概念和套路还没完全搞清楚。二是kaldi的文档偏少,不利于代码的理解。三是kaldi是算法和工具的集合,语音识别的整个流程是靠很多复杂的shell和Perl脚本把这些工具串起来实现的,不易读。四是kaldi是用C++实现的,而我们先前主要是用C开发软件(芯片公司的软件工程师多数都是在底层用C开发软件)。我们克服了这些困难,理出了每个模块有哪些事情要做,也搞清楚了软件实现分训练和识别两大部分,有些模块在训练和识别中都有,比如MFCC,而有些模块只在训练中有。训练是给识别做准备的,训练得到声学模型、字典和语言模型,并基于WFST将这三个合并成一个大的解码网络用于识别中。真正运行起来的语音识别系统只有识别部分的软件在运行。
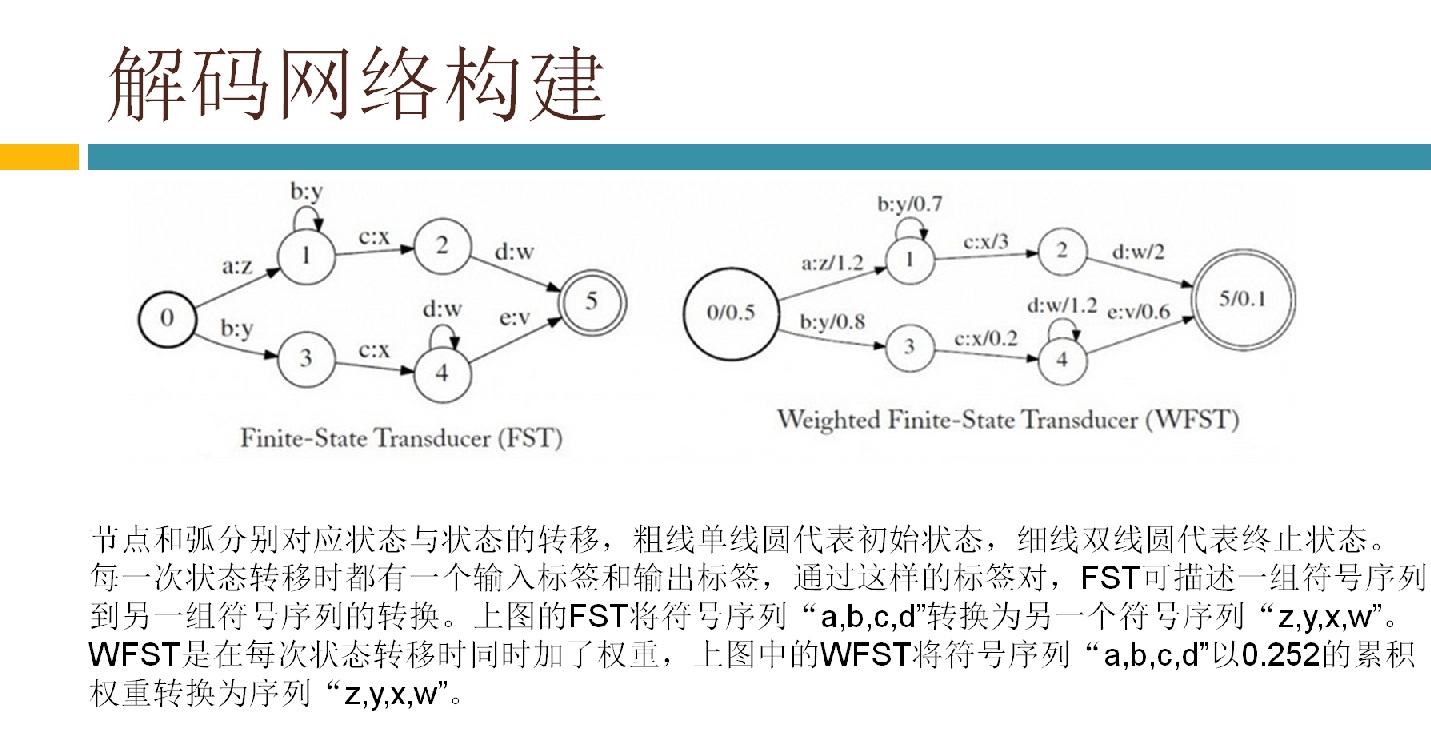
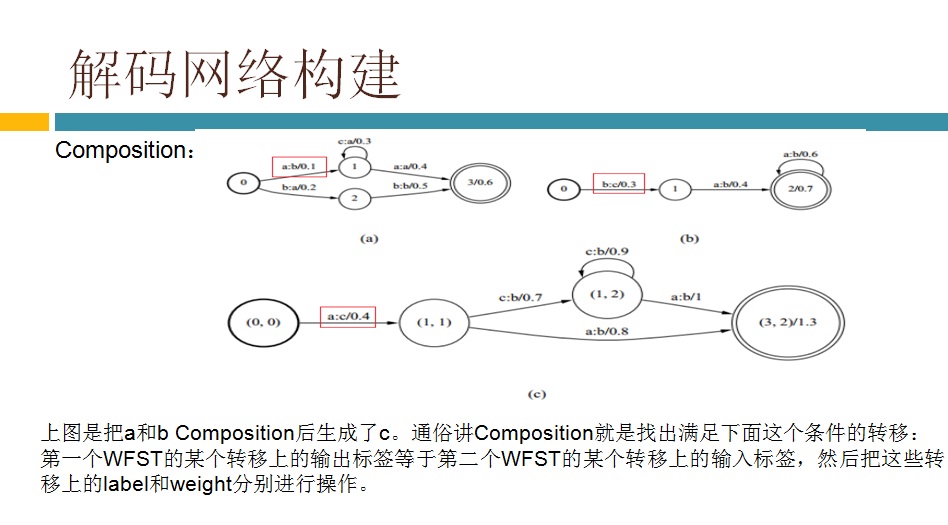
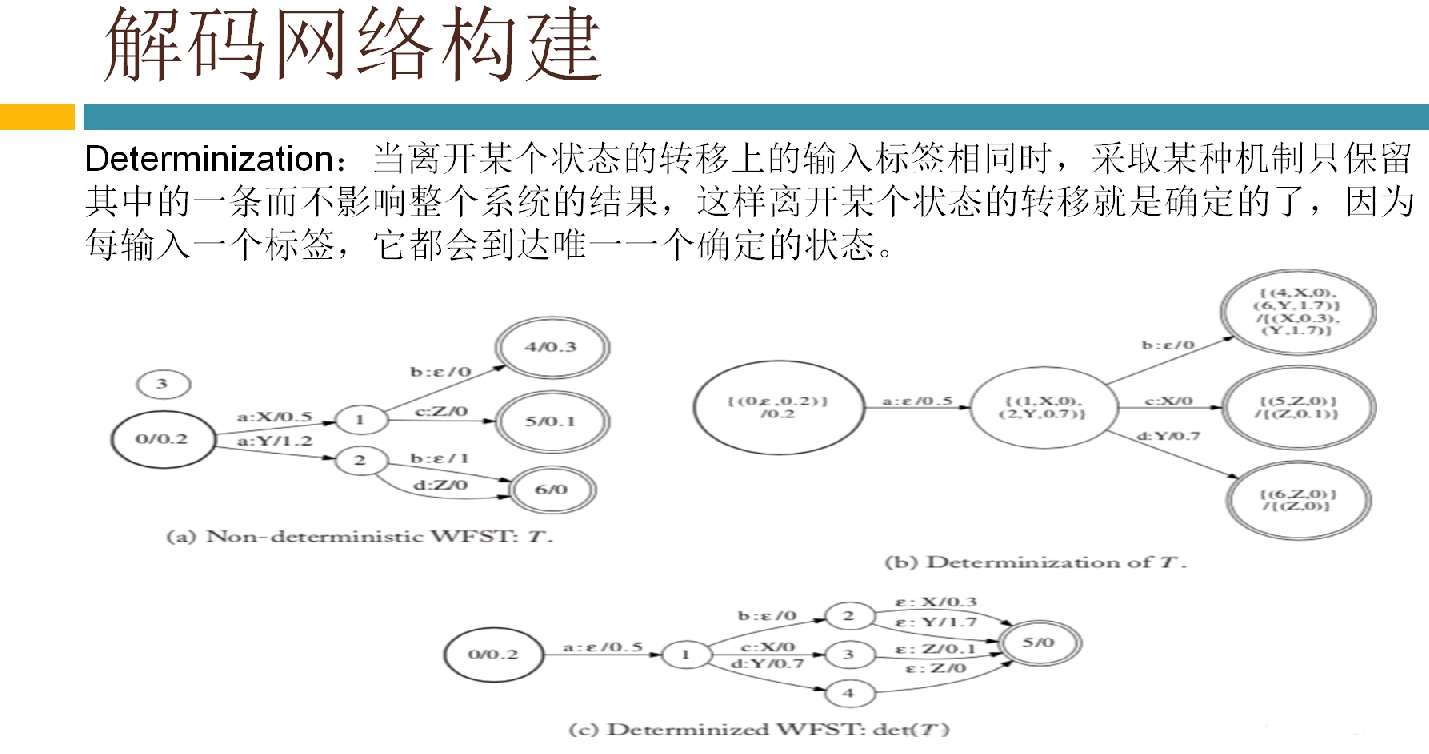
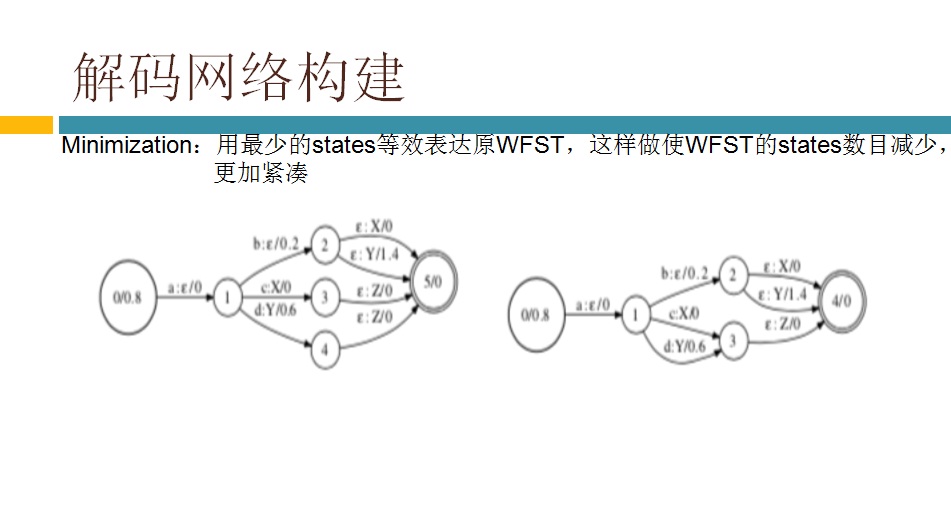
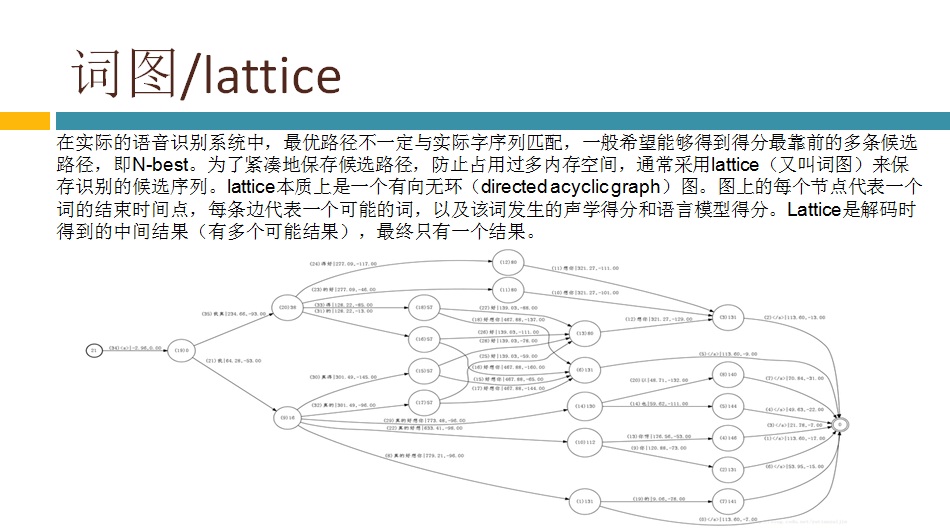
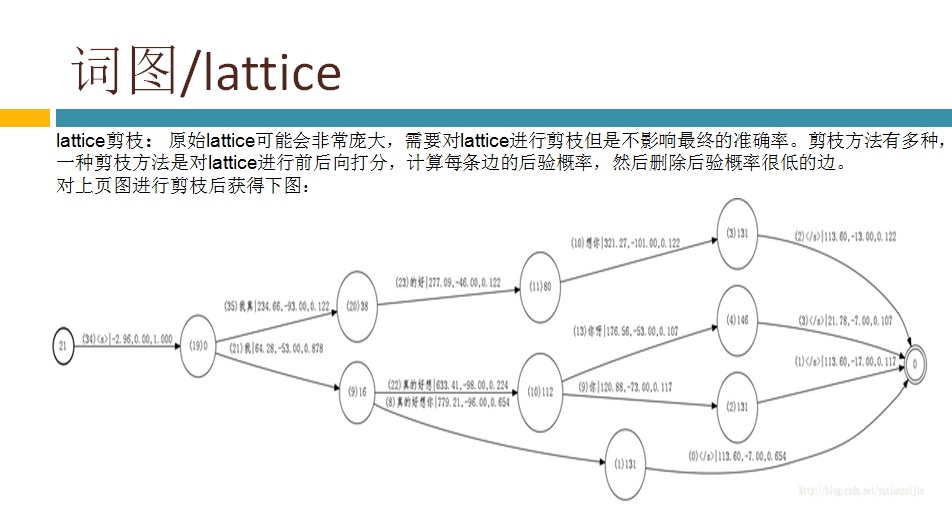
具体到我负责的解码,主要有两大部分组成,一是生成解码网络,二是基于解码网络解码。这里面的重中之重就是WFST(加权的有限状态转换器)。WFST属于半环代数理论。我是学控制出身,读本科时学了高数、矩阵、概率论等,读研究生时对矩阵进行了更深入的学习(控制学科对矩阵的要求较高),其他数学分支都没学过,半环代数理论显然是新东西。由于相关基础没有,学习起来不是很轻松,网上也说这学科对学数学和计算机理论的人学起来轻松些。现阶段我们只是搭语音识别系统,不需要深入研究算法,再加上时间也不允许(老板给我们定下了dealline),就仅仅了解了WFST的基本原理,后面就通过具体的例子来熟悉脚本和代码流程。Kaldi里有两种类型的解码器:offline 和 online。yesno就是最简单的offline解码器的例子,通过运行这个例子基本搞清楚了相关脚本和函数的意思。因为我们要搭的是在线实时系统,offline的参考性不大,也就没太关注,转而去看kaldi里的online decoder了。kaldi里的online decoder有两个版本:online(老版本) 和online2(新版本)。官网推荐用online2(基于例子RM(resource management)),并且声称要逐渐把老版本online废弃掉。但是现在RM的语料库无法从网络上下载到,所以例子RM就无法运行,只能去用老版本的online了。还好好多使用者说还是老版本的online好用,总算给我吃了一颗定心丸。看了相关的博客,都是基于kaldi里的唯一的中文识别的例子thchs30来做在线解码的。根据博客的指导,先下语料库,做各种训练得到解码网络等。再下载portaudio,使能从PC的MIC上采集到语音数据。最后改写脚本运行,这样一个在线解码的例子就跑起来了,PC的console上实时显示出了说的文字。在代码里加些log跟踪一下,也就搞清楚了在线解码时软件实现的机制和各种调用过程。
就这样解码相关的除了算法外其他的基本都搞清楚了。按照惯例,要做PPT给组内同学讲,让大家共同提高。我就根据自己的理解做了语音识别解码器相关的内容(一些图片还是借用了各种文档和博客里的,再此表示感谢,就不一一列出了)。下面就是我做的PPT的内容,给有需要的朋友看看。如果有错误,烦请指出,非常感谢!